17.1 Llama1
Llama 系列模型由 Meta 研发,在DeepSeek出现之前,是开源社区中最受关注的大语言模型之一。许多开发者在此基础上进行模型微调或构建智能应用。
Llama1 的论文题为 Open and Efficient Foundation Language Models(中文:《开放高效的基础语言模型》),强调了两个核心理念:开放性(Open)与高效性(Efficient)。
开放(Open)
Llama1 完全使用公开获取的数据进行训练,不涉及 Meta 内部或客户的私有数据。其性能已达到 GPT-3 水平,并已向研究社区开源,但目前仅限非商业用途。
高效(Efficient)
传统模型扩展策略往往以训练计算成本为衡量标准。例如,小模型(如 10B 参数)在训练初期损失下降较快,但后期趋于饱和;而大模型(如 50B 参数)在后期表现更优。如图所示(图 2-27),设定相同性能目标时,大模型的单位训练成本反而更低。
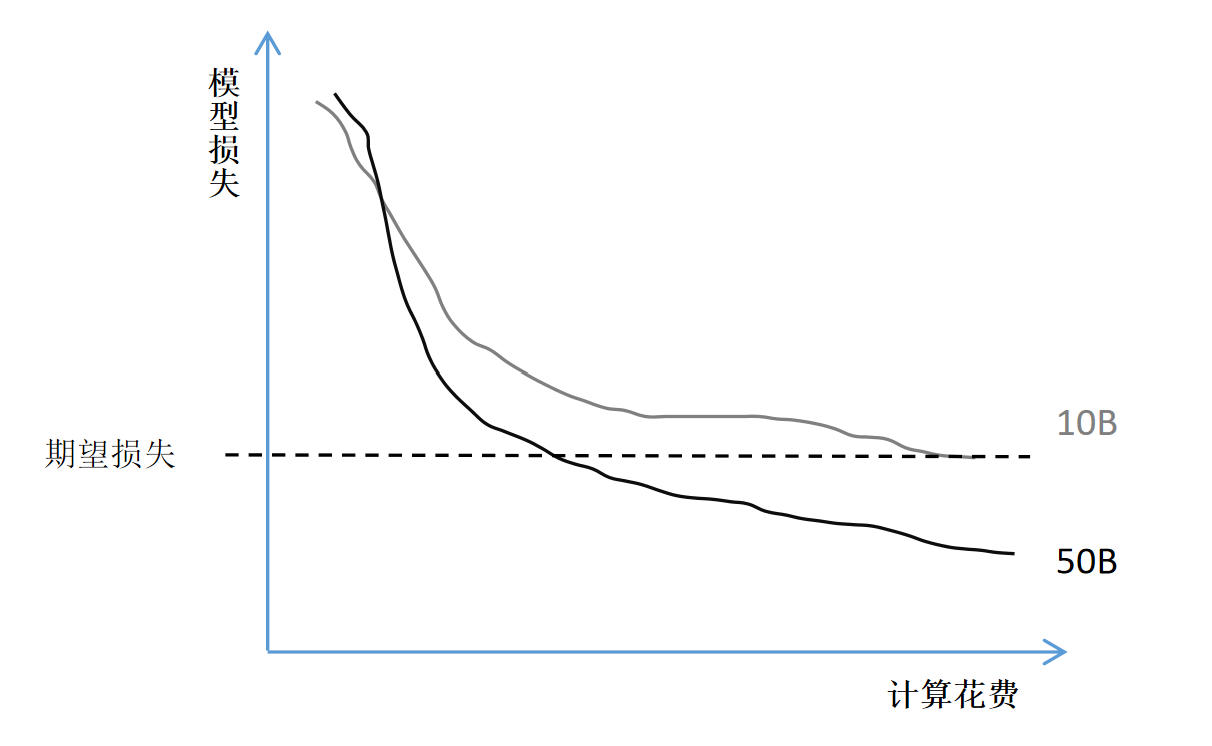
Meta 提出了新的视角:应更关注推理阶段的计算成本,因为训练只需一次,而推理会被频繁调用。因此,可以在训练阶段为小模型投入更多资源,从而实现推理时的高效性。
此外,Meta 的实验表明,增加训练数据规模比扩大模型参数更能提升性能。例如,尽管原有经验建议 10B 参数模型使用 2000 亿 token,Meta 实验发现,即便 7B 模型使用 1 万亿 token,性能依然在持续提升。这一发现也成为 Llama 设计哲学的核心之一。
17.1.1 训练细节
Llama1 的训练数据全部来源于公开渠道。其主要数据集是 2017~2020 年间的 CommonCrawl,经过去重和清洗,去除了所有非英文文本。
为了保证数据质量,Meta 使用一个线性分类器进行文本筛选:以维基百科引用的网页作为正样本,其他网页为负样本,从而筛选出更高质量文本。
训练时,书籍和维基百科数据各训练两个 epoch,其余数据仅训练一次。总训练数据达 1.4 万亿 token。
训练使用 2048 块 80GB 显存的 A100 GPU,上下文长度设为 2048 token,整个过程持续 21 天。
17.1.2 模型结构设计
Llama 使用与 GPT 系列类似的 Transformer 解码器架构,并在其基础上做出若干优化,以提升性能与稳定性:
- 前置归一化(Pre-Norm):将归一化步骤放在每个子层输入位置,提高训练稳定性。
- RMSNorm 替代 LayerNorm:减少归一化的计算开销。
- 使用 SiLU 激活函数:提升模型表达能力。
- 采用旋转位置编码(RoPE):更好处理相对位置信息。
RMSNorm 简介
RMSNorm 是对传统 LayerNorm 的一种优化,其关键在于去除归一化中的减均值步骤及偏置项,从而降低计算复杂度。
- LayerNorm 的公式如下:
- RMSNorm 的公式如下:
这种归一化方式减少了冗余操作,提高了训练效率。
SiLU 激活函数
SiLU(Sigmoid Linear Unit),也称 Swish,定义如下:
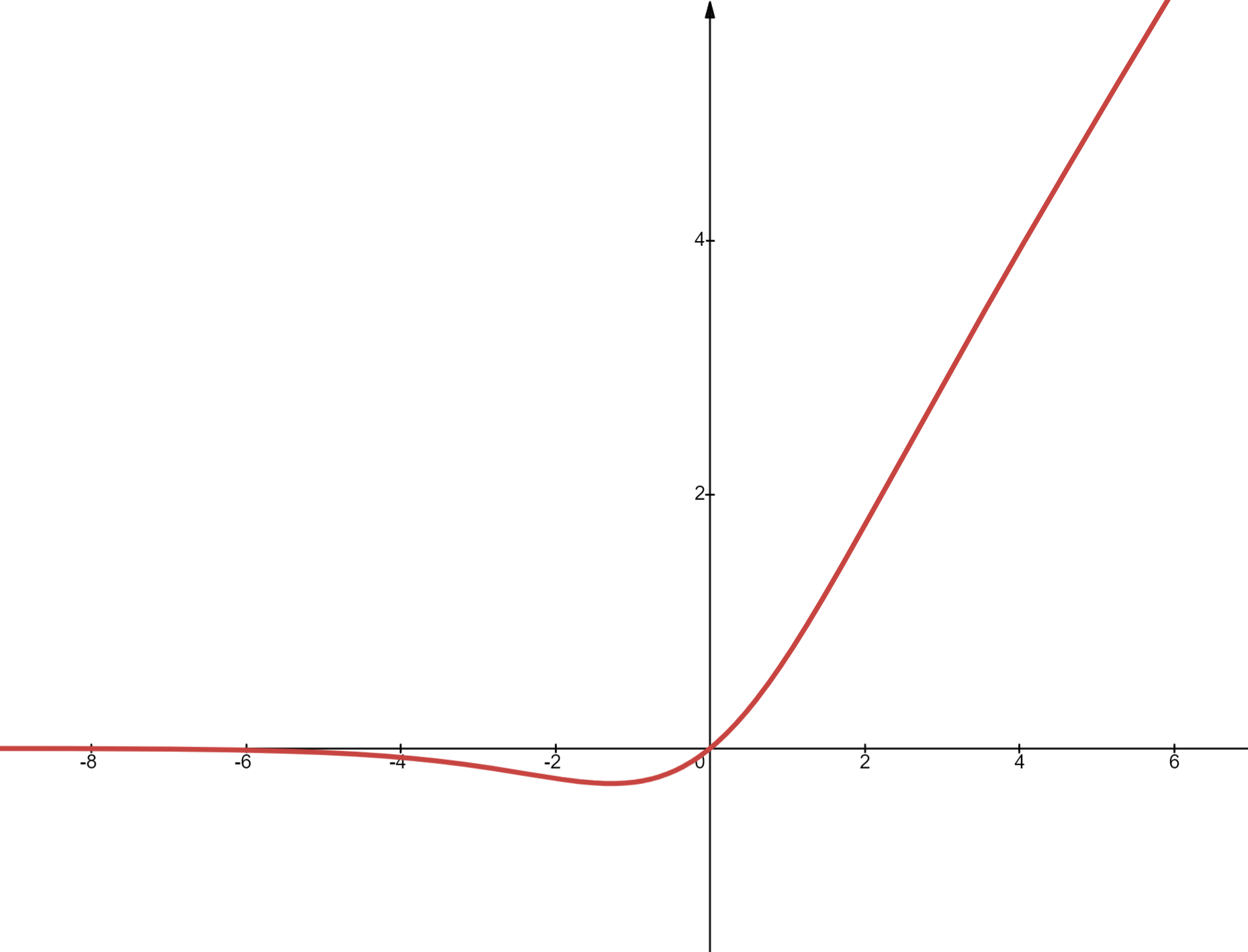
如上图所示,SiLU 函数在 0 附近较为平滑,远离 0 时则近似于 ReLU。虽然计算上比 ReLU 稍贵(因需计算 sigmoid),但实验显示它有助于提升模型精度,因此被 Llama1 所采用。
总结来看,Llama1 结合了开放的数据源、高效的训练策略与结构优化,不仅在性能上可与 GPT-3 相抗衡,还为开源社区与研究开发提供了可靠、高质量的大模型基础。