17.3 Llama 2
Meta 发布的 Llama 2 模型全称为 Open Foundation and Fine-Tuned Chat Models,中文可译为《开放的基础和微调对话模型》。相较于前代 Llama 1,Llama 2 在多个方面实现了显著的进步,成为开源大模型中的里程碑。
17.3.1 三大核心进步
Llama 2 相比 Llama 1 有以下三大关键改进:
开放性提升 Llama 2 不仅继续开源,同时也开放了商业使用许可,极大地扩展了其实际应用范围。
训练数据量增加 Meta 强调“数据优先”的理念,相比扩大模型参数,优先扩充训练数据集。Llama 2 的训练数据量较前代增长了约 40%,总量达到 2 万亿个 token。
引入对话模型 Llama 2 推出专门用于对话的微调版本 —— Llama 2-Chat,意图提供 ChatGPT 的开源替代方案。
17.3.2 模型参数与结构配置
Llama 2 共发布三个参数规模的版本:
- Llama 2–7B:约 70 亿参数
- Llama 2–13B:约 130 亿参数
- Llama 2–70B:约 700 亿参数
其他主要配置如下:
- 上下文长度从 LLaMA 1 的 2048 token 提升至 4096 token;
- 训练 GPU 时长:以 70B 模型为例,训练总计使用了约 172 万 GPU 小时。
17.3.3 全流程训练体系
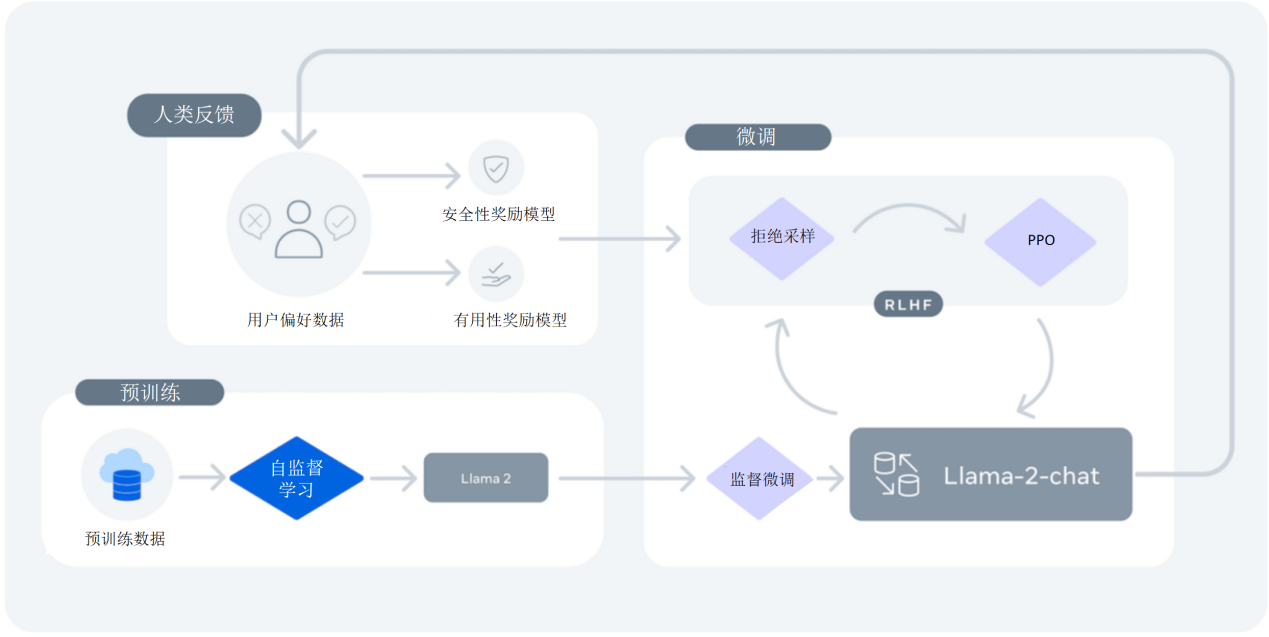
Llama 2 的训练流程如上图所示,可分为以下阶段:
预训练(Pretraining) 使用大规模无标注文本进行自回归训练,学习语言的基础结构和语义。
监督微调(Supervised Fine-tuning, SFT) 使用 10 万条 问答对进行标注训练,使模型输出更符合人类意图。
奖励模型训练(Reward Modeling) 利用 100 万条 人类偏好数据,对同一问题的多个回答进行排序,分别训练两个奖励模型:
- 安全性奖励模型(Safety)
- 有用性奖励模型(Helpfulness)
强化学习(Reinforcement Learning) 基于奖励模型提供的信号,优化模型输出质量,最终形成用于对话的 LLaMA 2-Chat 模型。
17.3.4 分组查询注意力机制(GQA)
在 Llama 2 的架构中,特别是 70B 模型中引入了 分组查询注意力机制(Group Query Attention, GQA),用于优化传统多头注意力机制。其优点包括:
- 降低模型参数量;
- 减少推理过程中的KV-Cache;
- 提升计算效率。
在基于注意力计算的大模型在进行生成时,每次生成一个token,然后将这个token加入到输入序列里,再生成下一个token。这样导致序列前边的token会被重复多次送入大模型进行计算。又因为mask机制限制了每个token只能看到自己后边的token。所以每个token再次被送入大模型,它在每一层计算出来的q,k,v向量都是不变的。又因为在计算后边token时,只用到前边token的k,v向量。所以每次可以将新生成token的k,v向量缓存下来,避免下次生成时的重复计算。这个缓存就叫做KV-Cache。
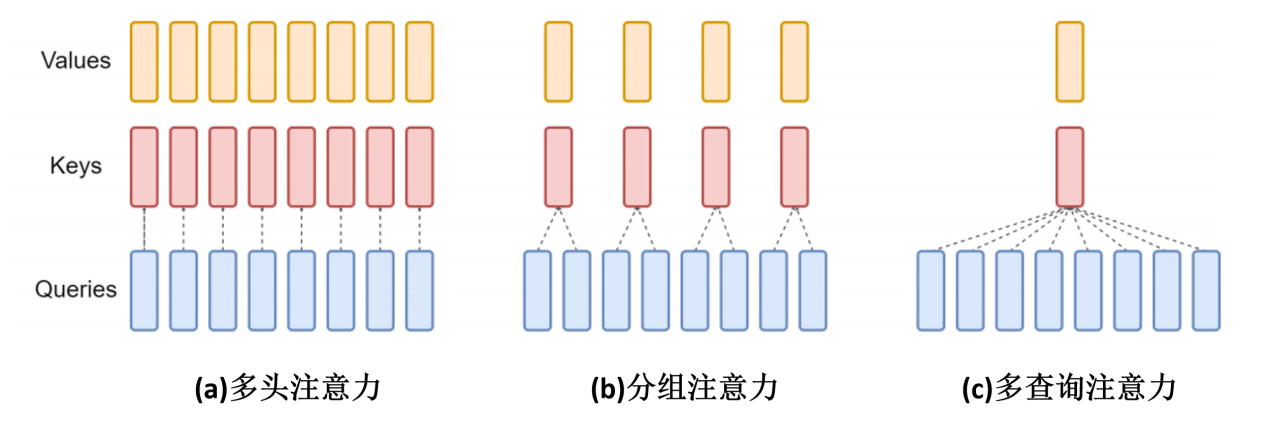
在传统的多头注意力机制中,每个 token 的特征对应生成相等数量的key、query和value头部,如上图(a)所示的八个。在这种设置中,每个query都与其他 token 的相应位置的key以及与自身相应位置的key进行注意力计算。然后根据注意力权重对value向量进行加权求和。
相比之下,如上图(c)所示的多查询注意力机制,虽然每个token的特征仍然生成八个query,但仅生成一个key和一个value。在这种结构中,每个token所有的query都与自己和其他token的生成的唯一key进行相似度计算。并对每个token唯一的value进行注意力加权求和。
分组查询注意力,如上图(b)所示,结合了多头注意力机制和多查询注意力机制的特点。在GQA中,query被分组,例如每组两个,每组对应一个key和一个value。这种方法既保持了注意力机制的精确度,又提高了参数使用的效率。
在传统的多头注意力机制中,假设原始token的维度为 512,对应的Q、K和V矩阵的生成通过线性变换层实现,其中权重矩阵w_q、w_k和w_v的维度均为512×512。由此生成的q、k和v向量维度也均为512,并被分为8个头,每个头的维度为64。
当优化为GQA时,考虑到每两个查询一组的配置,对应的k和v向量可以通过减半其线性层输出的维度来生成,即w_k和w_v的维度降为512×256,有效减少了模型的参数量。在这种设置中,尽管q保持8个头,但k和v的头数减少为4个。
为了在实现上保持一致性并有效利用矩阵乘法,k和v的头部在进行注意力计算前会被复制一份,从而与q的头再次对应。这样的处理使得q、k、v三者的头部数量一致,保证了后续逻辑与传统多头注意力机制相符。
GQA在llama2里只应用在最大的模型Llama70B里。其中8个query共享一个key和value。
17.3.5 表现与发展潜力
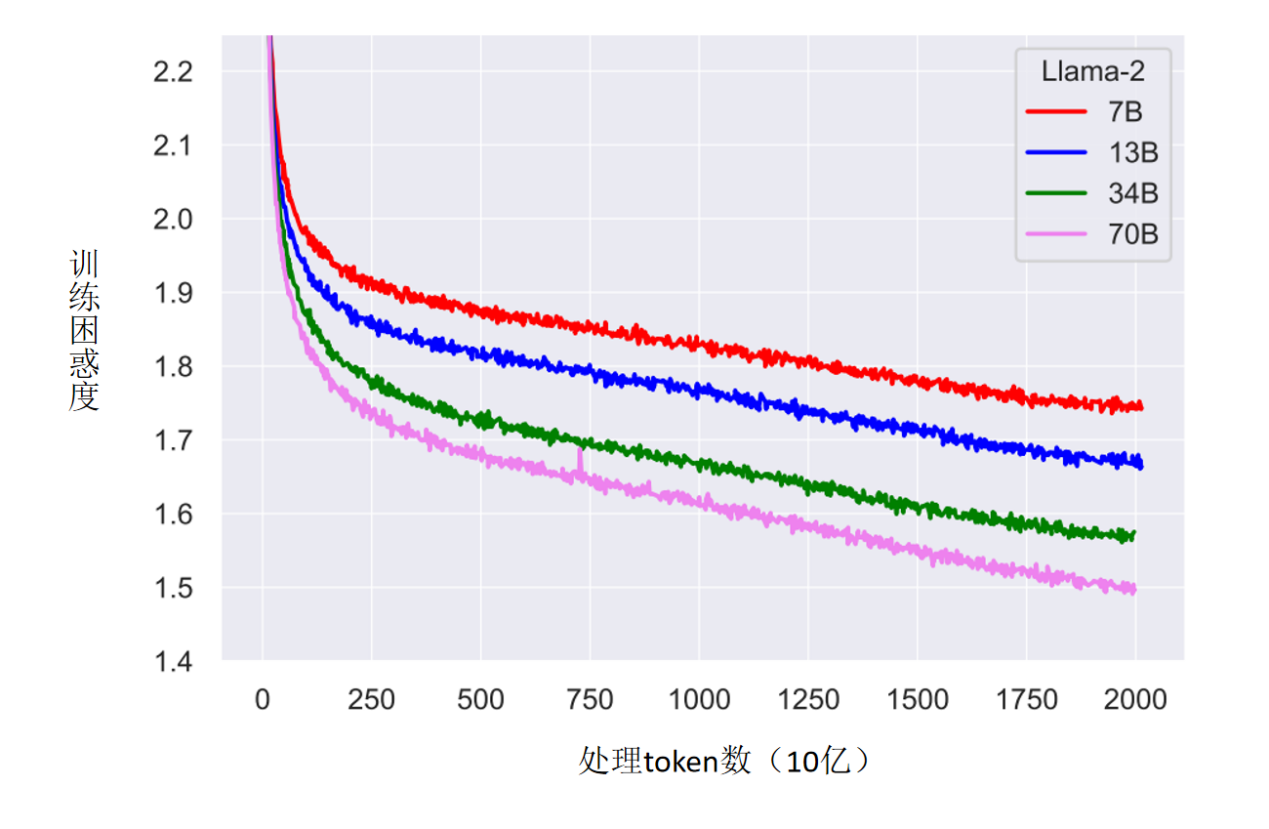
尽管 Llama 2 已使用高达 2 万亿 token 的训练数据,但模型的性能表现仍显示出持续优化的空间。如上图所示,训练困惑度(Perplexity)在 token 增加后仍持续下降,Meta 也据此在下一代 LLaMA 3 中进一步加大了数据规模。
Llama 2 不仅在训练数据、模型开放性和对话能力上大幅提升,更在架构上引入创新机制如 GQA,提高了性能与效率。作为开源社区的重要成果,Llama 2 正日益成为工业界与研究界开发智能对话系统的核心基础。