7.5欠拟合和过拟合
我们希望模型能够学习数据内涵的规律,但是又不希望模型死记硬背训练数据。上一节我们对数据集进行了划分,这一节我们就来对模型训练中的状态进一步进行讨论。
模型在训练中的状态分为三种,一种是欠拟合,一种是适度拟合,一种是过拟合。我们分别进行讨论。
7.5.1欠拟合
我们定义一个对模型的评价指标。比如对于回归问题,我们用MSE(均方误差)来作为评价指标。如果模型在训练集上表现都很差,那模型就是欠拟合。 比如你的数据明显是一条抛物线的分布,但是你拿一条直线去拟合。这时,无论你怎么训练。MSE都会很高。
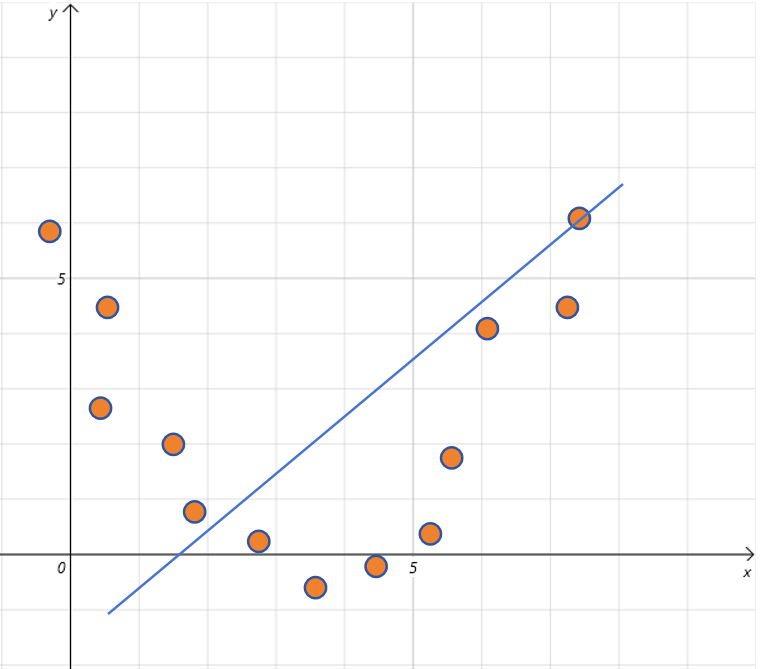
所以欠拟合表明模型还没有学习到真正的规律。
欠拟合的常见原因有: 1. 数据本身就没有规律。 2. 模型太简单,也就是你的假设函数太简单。(比如上边图像中包含了特征的二次项,但是你却只用一次函数去拟合) 3. 训练不足,还需要训练更多的迭代。
7.5.2过拟合
过拟合是模型在训练数据上指标很好,但是在验证数据集上指标很差。也就是模型对训练数据学习过度,已经死记硬背了。
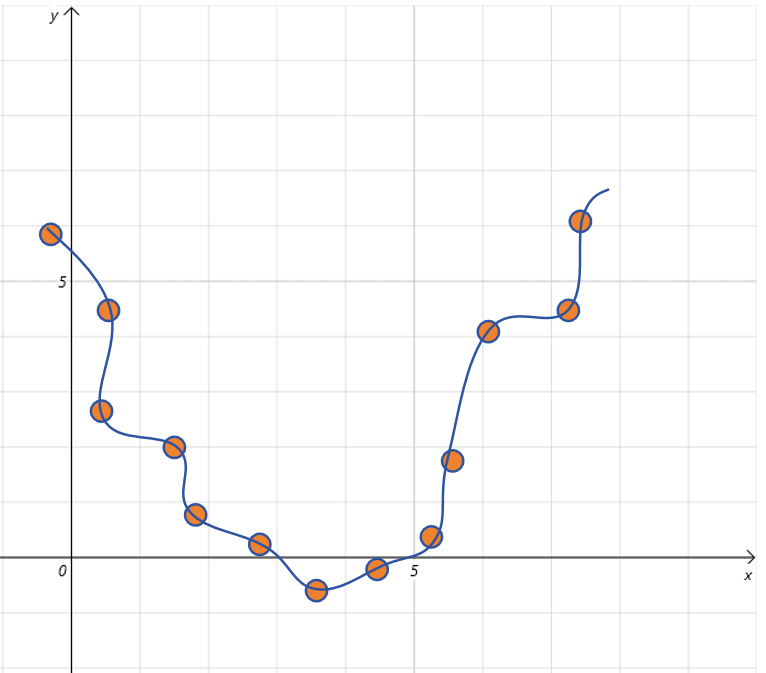
如上图所示,就是一个典型的过拟合曲线。它代表着我们在线性回归的模型里添加了过多的高次项,模型已经完全拟合了所有训练数据。
评价一个模型过拟合的标准就是模型在训练数据集上表现很好,但是在验证数据集上表现很差。
导致过拟合的原因有: 1. 假设函数太复杂。比如用特征的高次项去拟合简单的问题。 2. 训练数据太少。导致模型记住了个例。 3. 训练迭代次数太多。导致模型记住了所有数据。
7.5.3适度拟合
适度拟合是我们训练模型时希望模型达到的状态,它证明模型学到了数据里的底层规律。这些底层规律在验证集上也适用。我们称这种能力为泛化能力。训练集上学到的能力,可以泛化到没有见过的数据上。适度拟合的表现是模型在训练数据集和验证数据集上指标都很好。
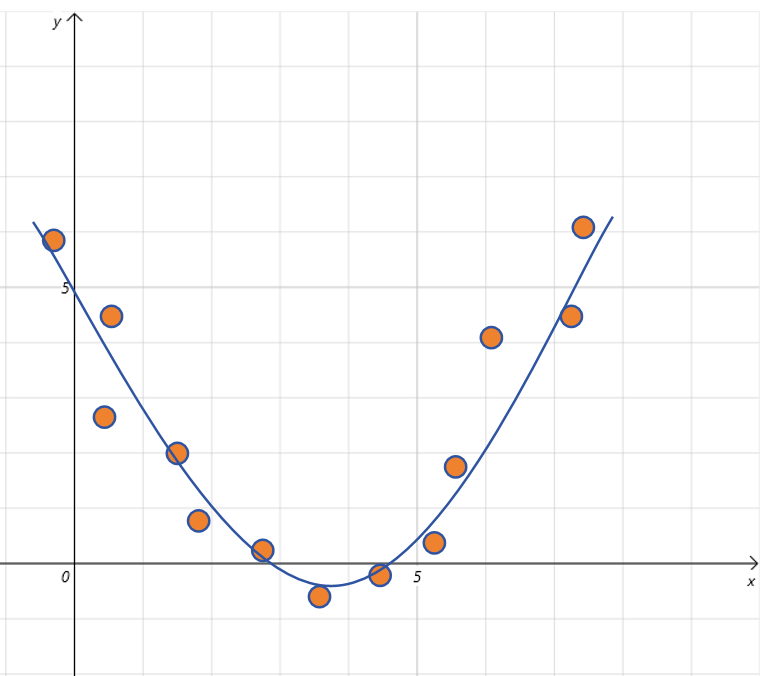
上图中的曲线就是对样本点的一个适度拟合。
7.5.4最佳实践
训练的第一步,是我们必须选择一个衡量模型性能的指标。接着划分数据集。然后开始模型的训练。
在模型的训练过程中,每过一些训练周期,你需要计算模型在训练数据集和验证数据集上的指标值。
首先你应该关注的是模型在训练数据集上的表现,如果模型在训练数据集上的表现不佳,那么就证明模型目前处于欠拟合的状态。此时你应该参考我们上文所说的原因进行调整。
当模型在训练数据集上表现达到你的预期时,你应该同步考虑模型在验证集上的表现,如果此时模型在验证集上的表现你也满意,那么恭喜你,你已经得到一个好的模型。如果此时模型在验证集上的表现很差,那么模型就处于过拟合的状态。你需要按照上文介绍的办法对训练过程进行调整。直到获得一个在训练集和验证集上都表现不错的模型。