11.8 目标检测
之前我们讲的都是卷积神经网络都是以图像分类任务作为例子,但是在实际应用中,更多的是目标检测的任务。因为实际场景中,一个图片中可能会同时有很多不同的物体。我们需要知道一个图片中都包含哪些物体,以及它们的位置和大小。比如在自动驾驶场景中,自动驾驶汽车需要能识别马路上的所有目标和位置。
 下边我们就以检测“汽车”,“行人”,“自行车”为例来讲解目标检测。
下边我们就以检测“汽车”,“行人”,“自行车”为例来讲解目标检测。
11.8.1 分类和定位
首先我们简化问题,假设一个图片里最多只能有一个目标(“汽车”,“行人”,“自行车”)。我们怎么在对这个目标进行分类的同时给出它的位置和大小。

对于上图,在数据标注时,需要标注人员用一个框来框出目标,并给出目标类别。这个框叫做“边界框”(bounding box)。有了这个框就告诉了我们目标在图片中的位置。一般我们用中心点的x坐标,y坐标,框高,框宽四个数字来表示目标位置。
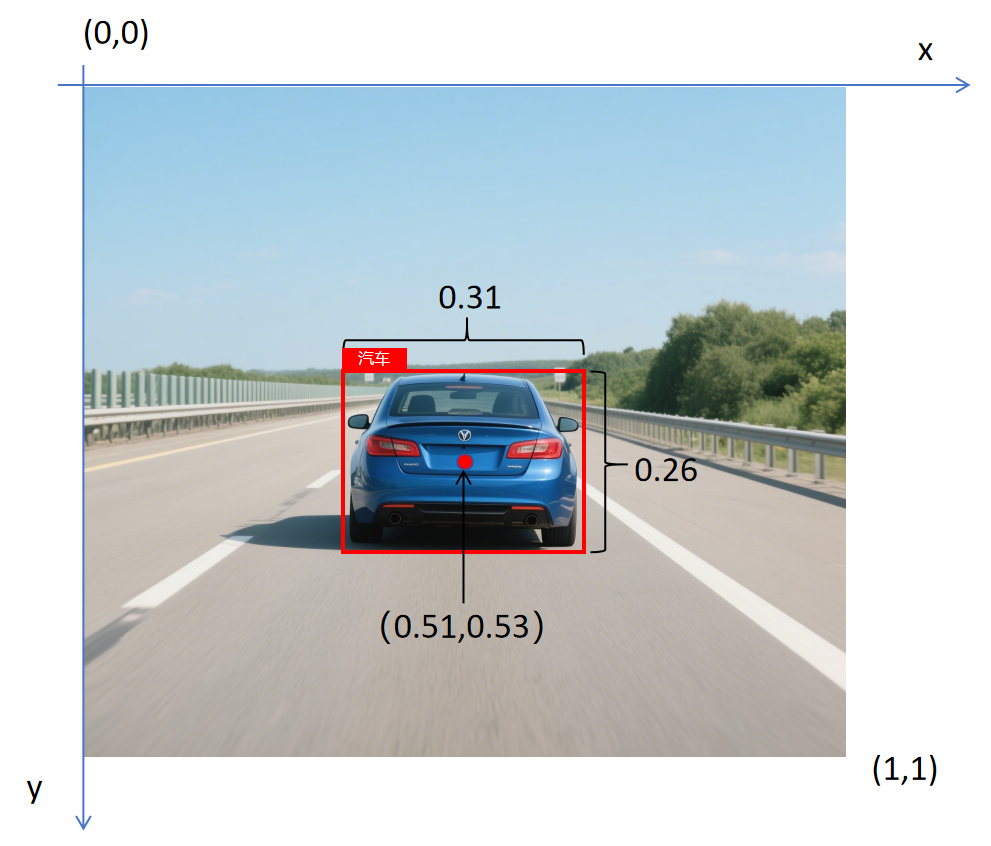 在目标检测中,以图片左上角作为原点(0,0),对图片的高和宽做归一化,右下角坐标为(1,1)。然后再获取边界框的位置数值。比如对于上边图片中的汽车,它的中心点坐标就为(0.51,0.53),高为0.26,宽为0.31。
在目标检测中,以图片左上角作为原点(0,0),对图片的高和宽做归一化,右下角坐标为(1,1)。然后再获取边界框的位置数值。比如对于上边图片中的汽车,它的中心点坐标就为(0.51,0.53),高为0.26,宽为0.31。
上图的标注数据一共包含8个元素,除了边界框位置的4个值外,还包含以下几个值: 图片中是否包含目标:,标注时,如果图片中含有汽车,行人,自行车中的任一个目标,值为1,如果都不包含,值为0。 图片中是否包含汽车:,标注时,如果是汽车,值为1,否则为0。 图片中是否包含行人:。 图片中是否包含自行车:。 这8个元素一起构成一个标注数据(在深度学习里,标注数据也叫做Ground Truth。) [,x,y,h,w,,,] 对应到上边这张图,它的Ground Truth就为: [1,0.51,0.53,0.26,0.31,1,0,0]
我们也需要对卷积神经网络进行改造,让网络可以输出对应的这8个值,原来在做图像三分类的卷积神经网络时,我们输出层有3个神经元,在做分类和定位任务时,我们需要改造输出层为8个神经元。其中每个神经元对应上边一个元素。
在训练的loss计算时,分为三部分进行,第一部分是对进行判断,这是一个二分类,激活函数用sigmoid,将网络输出映射到0-1的概率值。损失函数用二分类交叉熵损失。对于x,y,h,w,这几个连续值,直接使用MSE损失函数进行计算。对于,,,它们被当做一组多分类处理,激活函数用softmax,将网络输出映射到0-1的概率。并且这3个分类的概率和为1。损失函数用多分类交叉熵损失。 总的损失函数分为两种情况:
如果标注数据,表明图片中不包含任何目标,这时就不在意网络后边其他几个值的输出。网络的整体loss就仅为判断图片是否包含目标的二分类交叉熵损失。不计算边界框坐标 (x, y, h, w) 的损失和类别概率的损失。
如果标注数据,就是将对8个元素所有的损失相加,得到分类和定位的最终损失函数。
最终用总的loss计算梯度,反向传播。
如果你有足够的标注数据,经过上边方法的训练,你会得到不错的结果。由此可见: 1. 卷积神经网络不仅擅长做分类,也可以做回归任务。 2. 如果你的一个任务有多个目标,可以列出每个目标的loss,然后将多个loss加和,组成这个任务总的loss。这样神经网络在学习时会兼顾多个目标。
11.8.2 滑动窗口法
通过上边的办法,我们已经可以输出图片中一个目标的边界框了。那对于一个图片里含有多个目标的情况,我们该怎么处理呢?一个最简单的想法就是定义不同大小的窗口,让它在图片上滑动,每滑动一次,就截取一个图片,让卷积神经网络来进行分类和定位。这样就可以对整个图片进行目标检测了。
 因为图片中可能有不同大小的目标,所以可以定义不同大小的窗口来滑动。另外对于滑动窗口的步长也很重要,如果步长太小,则截取的图片太多,检测太慢。步长太大,又有可能没有一个窗口可以截取到完整的目标。
因为图片中可能有不同大小的目标,所以可以定义不同大小的窗口来滑动。另外对于滑动窗口的步长也很重要,如果步长太小,则截取的图片太多,检测太慢。步长太大,又有可能没有一个窗口可以截取到完整的目标。
11.8.3 利用卷积节省计算
 对于上图,上边一排是利用一个大的窗口在图像上滑动了4次。下方是每次窗口滑动截取的图片。利用滑动窗口法进行目标检测,对下边几个图片要分别独立进行卷积神经网络。可以发现截图有很多重复的部分,这些重复的部分每次都会被后边分类定位的卷积神经网络计算。造成大量的计算浪费。
我们首先看对于上图左上角的第一个滑动窗口截取图片进行分类和定位操作的卷积神经网络:
对于上图,上边一排是利用一个大的窗口在图像上滑动了4次。下方是每次窗口滑动截取的图片。利用滑动窗口法进行目标检测,对下边几个图片要分别独立进行卷积神经网络。可以发现截图有很多重复的部分,这些重复的部分每次都会被后边分类定位的卷积神经网络计算。造成大量的计算浪费。
我们首先看对于上图左上角的第一个滑动窗口截取图片进行分类和定位操作的卷积神经网络:
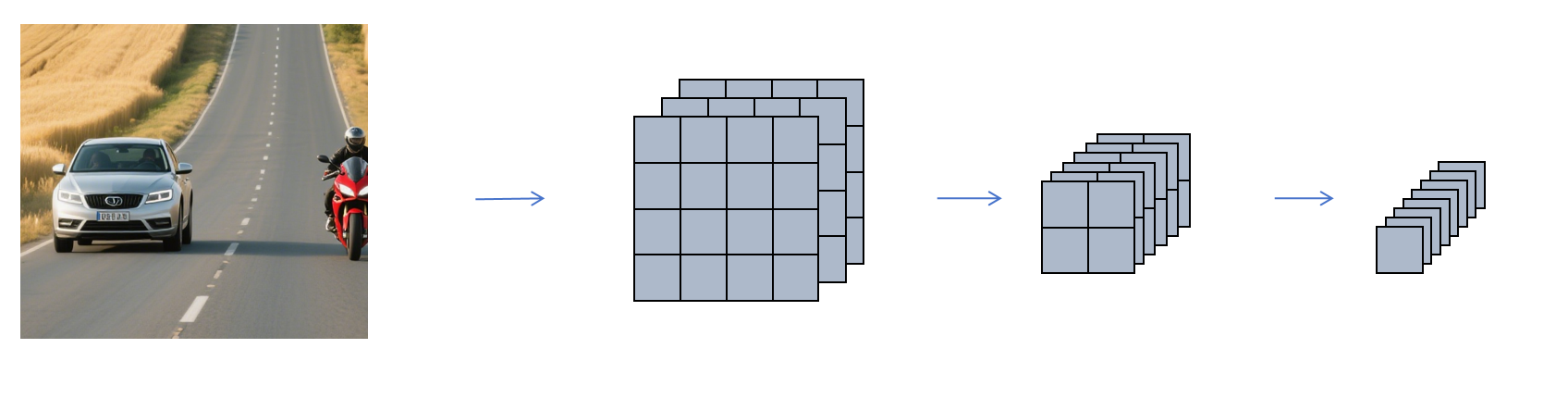 它经过卷积,池化,等操作,最后得到了一个1×1×8的特征图,其中的8个元素对应目标的类别和位置信息。
它经过卷积,池化,等操作,最后得到了一个1×1×8的特征图,其中的8个元素对应目标的类别和位置信息。
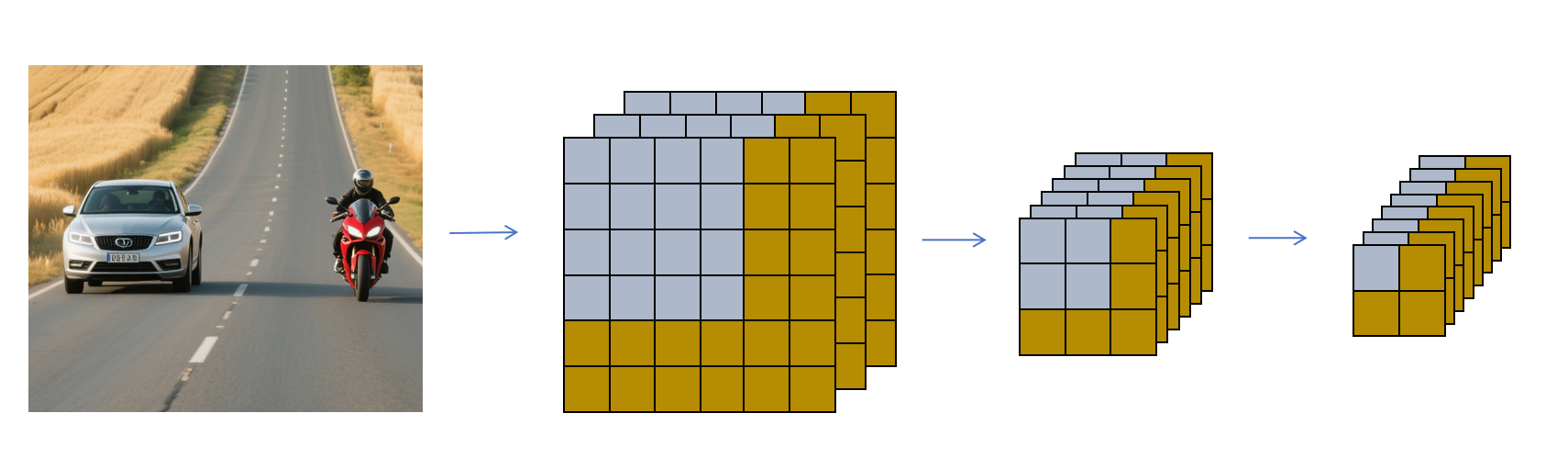 如上图,为了共享计算,我们可以对原始完整图片进行同样的卷积,池化等操作。最后得到了2×2×8的特征图,它分别对应原始图片4个滑动窗口最终获得的8个代表类别和位置的特征。这样对原始图片进行一次卷积网络的计算,就可以获得所有滑动窗口的最终8个特征,大大减少了计算量。
如上图,为了共享计算,我们可以对原始完整图片进行同样的卷积,池化等操作。最后得到了2×2×8的特征图,它分别对应原始图片4个滑动窗口最终获得的8个代表类别和位置的特征。这样对原始图片进行一次卷积网络的计算,就可以获得所有滑动窗口的最终8个特征,大大减少了计算量。
11.8.4 R-CNN 系列算法
R-CNN(Regions with Convolutional Neural Networks)是目标检测中的一类重要算法。 它的思想是分两阶段进行目标检测。
- 第一阶段获得目标可能存在的区域。获取可能区域的办法可以用各种方法,可以用卷积神经网络也可以用传统计算机图形学手动构造特征的办法,总之只要能给出目标可能存在的区域即可。
- 第二阶段对目标区域运行卷积神经网络进行进行分类和定位。这里可以对图片的可能区域部分进行卷积操作。也可以先对原始完整图片进行一次卷积操作,获得完整的特征图,然后将可能区域映射到对应的特征图上的区域,再进行分类和定位。
R-CNN分了两阶段进行目标检测,所以它的速度相对较慢,但是精度比较高。
11.8.5 YOLO 系列算法
YOLO(You Only Look Once)是一种端到端的实时目标检测算法,它最大的特点是速度快、实时性强。它是目标检测领域另一个重要的算法。
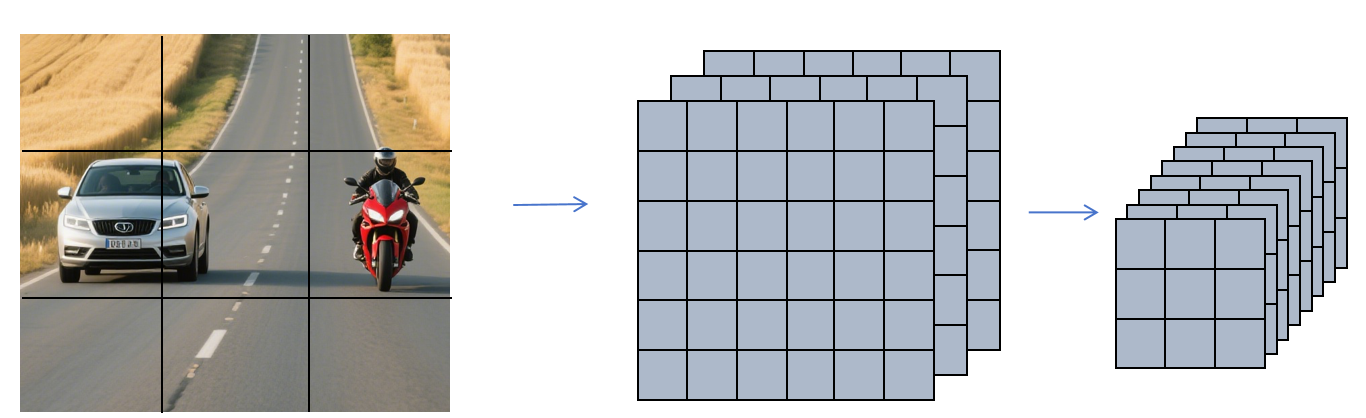 YOLO的基本思想是将原始图片划分为多个cell,比如上图分为3×3的cell。那最终就让卷积神经输出的特征图为3×3×8。原始图片上的每个目标的中心点落在哪个cell,就由哪个cell负责预测。因为特征图上每个像素的感受野是大于它对应cell的,所以即使目标有一部分超出它所在的cell。特征图里的特征还是能准确预测出每个目标的位置和大小。注意这里我们每个cell输出8个特征,是因为我们只分3类,假如你要分1000类,那么你最后每个cell的特征个数就是5+1000=1005,这里的5是4个位置信息和1个代表这个cell内是否包含目标的标志位。另外这里我们为了演示简单,将原图分为3×3个cell,但是在实际中都会划分成更多的cell,比如13×13。
YOLO的基本思想是将原始图片划分为多个cell,比如上图分为3×3的cell。那最终就让卷积神经输出的特征图为3×3×8。原始图片上的每个目标的中心点落在哪个cell,就由哪个cell负责预测。因为特征图上每个像素的感受野是大于它对应cell的,所以即使目标有一部分超出它所在的cell。特征图里的特征还是能准确预测出每个目标的位置和大小。注意这里我们每个cell输出8个特征,是因为我们只分3类,假如你要分1000类,那么你最后每个cell的特征个数就是5+1000=1005,这里的5是4个位置信息和1个代表这个cell内是否包含目标的标志位。另外这里我们为了演示简单,将原图分为3×3个cell,但是在实际中都会划分成更多的cell,比如13×13。
11.8.6 总结
目标检测是计算视觉的一个重要分支,我们上边讲的只是最基本,简化后的原理。实际目标检测还要处理更多问题,比如如果一个cell里包含多个目标的情况怎么处理?多个cell对同一个目标进行了预测怎么办?图片里的目标大小差别很大怎么办?等等。后边我会专门出一个教程来讲目标检测。在深度学习这门课里我们对目标检测的讨论就到这里。