8.6多分类神经网络的反向传播
虽然在PyTorch里你只需要定义模型的前向传播过程并给出损失函数。PyTorch框架会帮你在后向传播时自动计算梯度并使用优化器更新参数。但是我们还是需要自己推导一次神经网络反向传播的梯度计算。这将帮助你彻底了解神经网络的训练原理,消除它的神秘感。而且了解反向传播的具体过程也是理解后边一系列神经网络训练优化技术的基础。
8.6.1网络结构
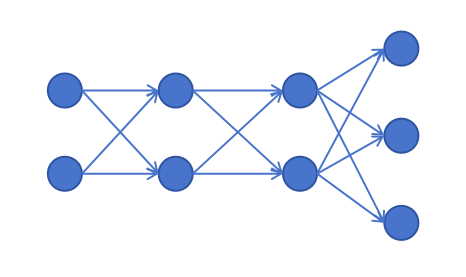 我们以上边这个图里展示的神经网络为例,输入feature维度为2,2个隐藏层,每层的神经元为2个,输出层有3个神经元来支持3分类任务。
我们以上边这个图里展示的神经网络为例,输入feature维度为2,2个隐藏层,每层的神经元为2个,输出层有3个神经元来支持3分类任务。
8.6.2前向传播过程
我们先写出前向传播过程。
输入:
[x1x2]
第一个隐藏层的logits:
[z11z21]=[x1x2][w111w211w121w221]+[b11b21]
第一个隐藏层的输出如下。其中act()是激活函数,对logits的值逐个应用激活函数:
[a11a21]=[act(z11)act(z21)]
第一个隐藏层的输出作为第二个隐藏层的输入,则第二个隐藏层的logits为:
[z12z22]=[a11a21][w112w212w122w222]+[b12b22]
第二个隐藏层的输出:
[a12a22]=[act(z12)act(z22)]
输出层的logits:
[z13z23z33]=[a12a22][w113w213w123w223w133w233]+[b13b23b33]
输出层经过softmax:
a3=[a13a23a33],ai3=∑j=13ezj3ezi3
输出层经过cross entropy,计算loss的公式如下:
真实标签用一维的one-hot向量表示:
y=[y1y2y3]
其中向量y的元素中只有一个元素为1,其余元素为0。
则 loss公式为:
loss=−(y1lna13+y2lna23+y3lna33)
8.6.3反向传播过程
神经网络里每层的权重和偏置都可以看成是一个由多个参数构成的矩阵。反向传播时需要计算每个权重和偏置的梯度,实际上就是用最终的loss值对每一个参数求导,这些对单个参数的求导计算可以通过矩阵运算进行加速。后边我们会详细来解释。如果你不理解其中的过程,你可以从最终的loss对单个参数利用链式法则进行求导。你会发现和我下边讲的结果是一致的。推导的过程可能有些麻烦,但是一旦你完成一次,神经网络对你而言,就不再神秘了。
8.6.3.1 loss对logits求导
首先我们来求解loss对模型输出的logits z3的偏导数。它等于loss对z13,z23,z33分别求导,我们以loss对z13求导为例:
∂z13∂loss=∂a13∂loss⋅∂z13∂a13+∂a23∂loss⋅∂z13∂a23+∂a33∂loss⋅∂z13∂a33
=a13−y1⋅∂z13∂a13+a23−y2⋅∂z13∂a23+a33−y3⋅∂z13∂a33 (式8-1)
接下来,我们分两种情况进行讨论:
第一种情况
这个样本分类结果就是第一类,这时label为:y1=1,y2=0,y3=0,可以化简上式为:
∂z13∂loss=a13−y1⋅∂z13∂a13
继续求导:
∂z13∂loss=a13−y1⋅(∑j=13ezj3)2ez13∑j=13ezj3−(ez13)2
带入以下a13的公式进行化简:
a13=∑j=13ezj3ez13
化简后的结果为:
∂z13∂loss=a13−y1⋅(a13−(a13)2)
继续化简:
∂z13∂loss=a13−y1
第二种情况
这个样本分类结果不是第一类:
假设类别为k,k不是第一类。
则化简式8-1为:
∂z13∂loss=ak3−yk⋅∂z13∂ak3
继续求导:(因为k不等于1,所以z13仅出现在softmax的分母里。)
∂z13∂loss=ak3−yk⋅(∑j=13ezj3)2−ezk3ez13
同样,根据softmax公式进行化简:
∂z13∂loss=ak3−yk⋅−a13ak3=yka13
此时,yk=1,y1=0,所以可以改写为:
∂z13∂loss=a13−y1
可以看到,两种情况都可以得到同一个结果。上边是loss对z13求导。不失一般性,loss对zi3求导公式为:
∂zi3∂loss=ai3−yi(i=1,2,3)
我们把loss对第三层的logits的导数记作:
δ3=[a13−y1a23−y2a33−y3]
8.6.3.1 输出层的梯度
输出层的logits计算公式如下:
[z13z23z33]=[a12a22][w113w213w123w223w133w233]+[b13b23b33]
而且上边我们已经求得了loss对输出层logits的导数。我们下边分别求loss对每一个 wij3的梯度。
我们以loss对w113的偏导数为例:
∂w113∂loss=∂z13∂loss⋅∂w113∂z13+∂z23∂loss⋅∂w113∂z23+∂z33∂loss⋅∂w113∂z33
因为其中只有z13和w113有关,上边连加表达式的后两项z23,z33对w113求导都为0,所以有:
∂w113∂loss=∂z13∂loss⋅∂w113∂z13=δ13a12
依次类推,我们可以求出每个wij3的梯度:
[δ13a12δ13a22δ23a12δ23a22δ33a12δ33a22]
可以用矩阵运算表示如下:
∂w3∂loss=(a2)Tδ3=[a12a22][δ13δ23δ33]
下边我们来考虑偏置的梯度值。以loss对b13的偏导为例:
∂b13∂loss=∂z13∂loss⋅∂b13∂z13=δ13
同理,loss对b23,b33的偏导为:δ23,δ33,所以loss对于第三层偏置的偏导就等于δ3。
因为loss对于第二层参数的偏导数,需要利用链式法则,通过a2进行传递,所以下边我们计算loss对于a2的偏导数。
我们以loss对a12为例:
∂a12∂loss=∂z13∂loss⋅∂a12∂z13+∂z23∂loss⋅∂a12∂z23+∂z33∂loss⋅∂a12∂z33
=δ13w113+δ23w123+δ33w133
同理,可以得到:
∂a22∂loss=δ13w213+δ23w223+δ33w233
改为矩阵表示loss对第二层激活值的偏导为:
∂a2∂loss=δ3(w3)T=[δ13δ23δ33]⎣⎢⎡w113w123w133w213w223w233⎦⎥⎤
接着,我们求loss对第二层logits值的偏导:
δ2=∂z2∂loss=∂a2∂loss⋅∂z2∂a2=δ3(w3)T⊙act′(z2)
其中⊙是矩阵对应元素相乘,因为激活函数是对每个z值单独应用的,所以这里求导也是逐个元素应用的。
8.6.3.2 第二层的梯度
与上边对输出层的权重和偏置的求导方法一样,我们可以得到:
∂w2∂loss=(a1)Tδ2
loss对于第二层偏置的偏导就等于δ2。
δ1=δ2(w2)T⊙act′(z1)
8.6.3.3 第一层的梯度
∂w1∂loss=xTδ1
loss对于第一层偏置的偏导就等于δ1
8.6.4 各层的梯度
其中δi表示loss对第i层logits的偏导数。
δ3=[a13−y1a23−y2a33−y3]
∂w3∂loss=(a2)Tδ3
∂b3∂loss=δ3
δ2=δ3(w3)T⊙act′(z2)
∂w2∂loss=(a1)Tδ2
∂b2∂loss=δ2
δ1=δ2(w2)T⊙act′(z1)
∂w1∂loss=xTδ1
∂b1∂loss=δ1
通过上边的推导,你应该已经可以看出来了每一层参数和偏置求导的规律。
假设这个神经网络一共有n层,第n层是输出层。x是输入向量,y是one-hot的label向量。
则:
δn=an−y
对于第i层而言:
δi=δi+1(wi+1)T⊙act′(zi)
∂wi∂loss=(ai−1)Tδi
∂bi∂loss=δi
第一层的输入是x:
a0=x
8.6.5 批量数据支持
上边我们的推导是针对一条数据的,但是我们实际训练神经网络时都是用一个batch的数据进行训练的。
同样以上边的网络结构为例:
按行输入三条数据,batch size是3:
⎣⎢⎡x11x21x31x12x22x32⎦⎥⎤
第一个隐藏层的logits:
⎣⎢⎡z111z211z311z121z221z321⎦⎥⎤=⎣⎢⎡x11x21x31x12x22x32⎦⎥⎤[w111w211w121w221]+⎣⎢⎡b11b11b11b21b21b21⎦⎥⎤
注意上边的偏置参数矩阵,它的三行是相同的参数。这是因为需要对每条记录的计算结果都增加偏置,所以将偏置复制了3行,这里的3是BatchSize。权重参数矩阵不变。
忽略第二个隐藏层,我们看输出层的logits:
⎣⎢⎡z113z213z313z123z223z323z133z233z333⎦⎥⎤=⎣⎢⎡a112a212a312a122a222a322⎦⎥⎤[w113w213w123w223w133w233]+⎣⎢⎡b13b13b13b23b23b23b33b33b33⎦⎥⎤
输出层对每一行应用softmax,得到:
a3=⎣⎢⎡a113a213a313a123a223a323a133a233a333⎦⎥⎤
label为:
y=⎣⎢⎡y11y21y31y12y22y32y13y23y33⎦⎥⎤
其中y的每一行都是one-hot编码的,也就是每行只有一个元素是1,其余为0。
loss函数为:
loss=−31∑i=13(yi1lnai13+yi2lnai23+yi3lnai33)
因为softmax是按行计算,loss计算也是按行进行计算,最终再对loss求平均,其他行的数据并不会对当前行的计算造成影响。所以3行的∂z3∂loss和只有一行的唯一区别就是前边多了个31。所以:
δ3=31⎣⎢⎡a113−y11a213−y21a313−y31a123−y12a223−y22a323−y32a133−y13a233−y23a333−y33⎦⎥⎤
接下来我们分析loss对输出层权重的偏导数。以w113为例:
∂w113∂loss=∂z113∂loss⋅∂w113∂z113+∂z213∂loss⋅∂w113∂z213+∂z313∂loss⋅∂w113∂z313
=δ113a112+δ213a212+δ313a312
你可以求出其他第三层权重的偏导数,你会发现它和只有一行输入的情况下,没有变化,依然是:
∂w3∂loss=(a2)Tδ3
接下来我们分析loss对输出层偏置的偏导数,以b13为例:
∂b13∂loss=∂z113∂loss⋅∂b13∂z113+∂z213∂loss⋅∂b13∂z213+∂z313∂loss⋅∂b13∂z313
=∂z113∂loss+∂z213∂loss+∂z313∂loss
=δ113+δ213+δ313
同理可以得到:
∂b23∂loss=δ123+δ223+δ323
∂b33∂loss=δ133+δ233+δ333
注意,可以看到这里loss对b3求偏导的结果和单个样本的结果不同。之前只有一个样本,δ3也只有一行,loss对b3求偏导就直接是δ3。但是当BatchSize为3的时候,截距被复制到3行,对每一个样本都起作用。δ3也有3行。loss对b3求偏导就是δ3的三行相加。
loss对于下一层logits的偏导和权重类似,都不受BatchSize的影响,依然为:
δi=δi+1(wi+1)T⊙act′(zi)
最终我们得到针对BatchSize为N的批量数据的梯度公式如下:
δn=N1(an−y)
对于第i层而言:
δi=δi+1(wi+1)T⊙act′(zi)
∂wi∂loss=(ai−1)Tδi
∂bji∂loss=∑k=1Nδkji
第一层的输入是x:
a0=x
后边我们会利用这些我们推导出的公式来手动实现一个神经网络的训练。