15.5 把这一切组装起来
之前章节我们讲了Transformer模型里的大部分组件,这一节我们就把它们组装起来。
15.5.1 整体架构
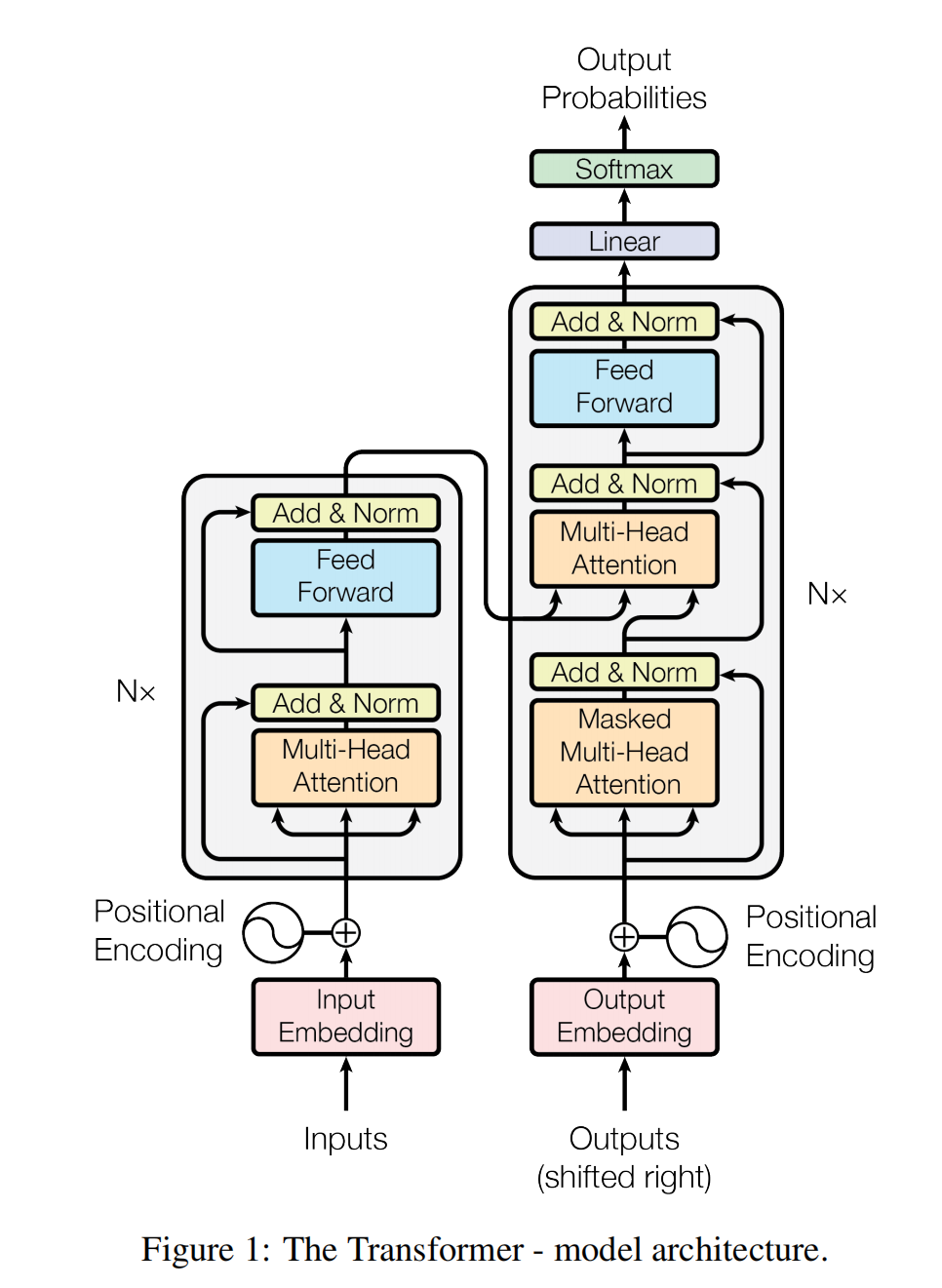 上图来自Transformer的论文,它整体上分为左右两部分。左半部分是编码器Encoder部分,右边部分是解码器Decoder部分。
上图来自Transformer的论文,它整体上分为左右两部分。左半部分是编码器Encoder部分,右边部分是解码器Decoder部分。
15.5.2 编码器
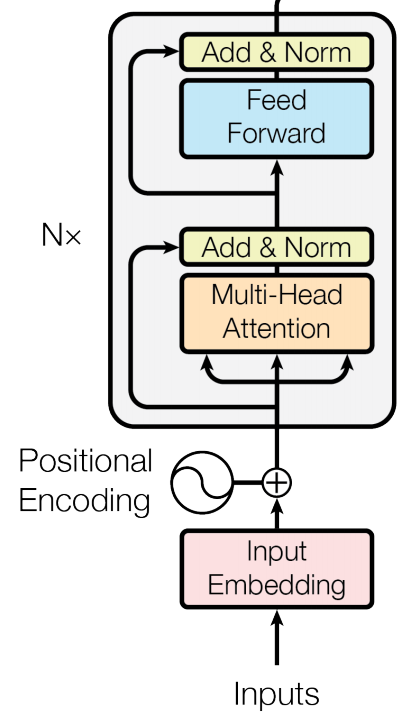 我们首先来看编码器部分。对于将英文翻译为中文的这个序列到序列问题。编码器部分输入的是一个batch的token id列表,还有这个batch token 列表对应的mask,mask用来标志哪些token是填充的
我们首先来看编码器部分。对于将英文翻译为中文的这个序列到序列问题。编码器部分输入的是一个batch的token id列表,还有这个batch token 列表对应的mask,mask用来标志哪些token是填充的
接下来利用Embedding模块,根据每个token的id,转化为token的embedding,然后加上每个token的位置编码信息。输出的表达token embedding的tensor 形状为[batch_size,seq_len,d_k]。其中d_k为embedding的维度,标准Transformer里是512。
接下来就进入N个EncoderBlock,标准Transformer里N为6。每个EncoderBlock的输入为表示inputs embedding张量,它的维度为[batch_size,seq_len,d_k]。在EncoderBlock内部,根据自注意模块和全连接模块的embedding更新后,保持维度不变,还是[batch_size,seq_len,d_k]。因为EncoderBlock输入和输出的张量维度一致,所以可以堆叠多层。
我们来查看一下EncoderBlock内部的细节,首先是一个我们之前讲过的多头自注意里层,然后是一个残差连接和Layer Norm。我们之前讲过残差连接,它可以让更深的层容易训练。然后是一个全连接层,同样后边有一个残差连接和Layer Norm。
全连接模块实现:
class FeedForwardBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float) -> None:
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
# (batch, seq_len, d_model) --> (batch, seq_len, d_ff) --> (batch, seq_len, d_model)
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))全连接模块里定义了两个层,第一个层将每个token embedding的维度从512扩展到2048,然后应用了ReLU激活,接着进行dropout。第二层将每个token embedding的维度从2048重新降维到512。
Add & Norm 模块实现:
class ResidualConnection(nn.Module):
def __init__(self, features: int, dropout: float) -> None:
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization(features)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))上边代码中传入的sublayer,可以是多头注意力模块,也可以是全连接模块。可以看到在前向传播时,先对输入的序列进行Layer Norm,然后进入sublayer,加一个dropout,最后和输入序列进行一个残差连接。
15.5.3 编码器的完整代码
class EncoderBlock(nn.Module):
def __init__(self, features: int, self_attention_block: MultiHeadAttentionBlock,
feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
# 定义多头自注意力模块
self.self_attention_block = self_attention_block
# 定义全连接模块
self.feed_forward_block = feed_forward_block
# 定义两个Add & Norm模块
self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(2)])
def forward(self, x, src_mask):
# 第一个残差连接,跳过多头注意力模块
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask))
# 第二个残差连接,跳过全连接模块
x = self.residual_connections[1](x, self.feed_forward_block)
return x
class Encoder(nn.Module):
def __init__(self, features: int, layers: nn.ModuleList) -> None:
super().__init__()
# 传入的6个EncoderBlock
self.layers = layers
self.norm = LayerNormalization(features)
def forward(self, x, mask):
# 依次调用6个EncoderBlock
for layer in self.layers:
x = layer(x, mask)
# 输出前进行Layer Norm
return self.norm(x)15.5.4 编码器的总结
编码器的作用是根据上下文,不断更新输入序列中每个token的Embedding。让最终输出序列token的embedding有最佳的语义。因为自注意力机制,可以一次性输入整个序列,序列内多个token可以并行处理,大大加快了处理速度。其中使用了位置编码增加了token的位置信息。通过多头注意力让token可以根据上下文信息修改自身embedding。通过全连接模块让每个token更新自身embedding。通过残差连接和LayerNorm让深度网络更容易训练。
15.5.5 解码器
以英文翻译中文任务为例,解码器的作用就是参考编码器的输出,以及自身已经翻译的内容,生成下一个中文token。
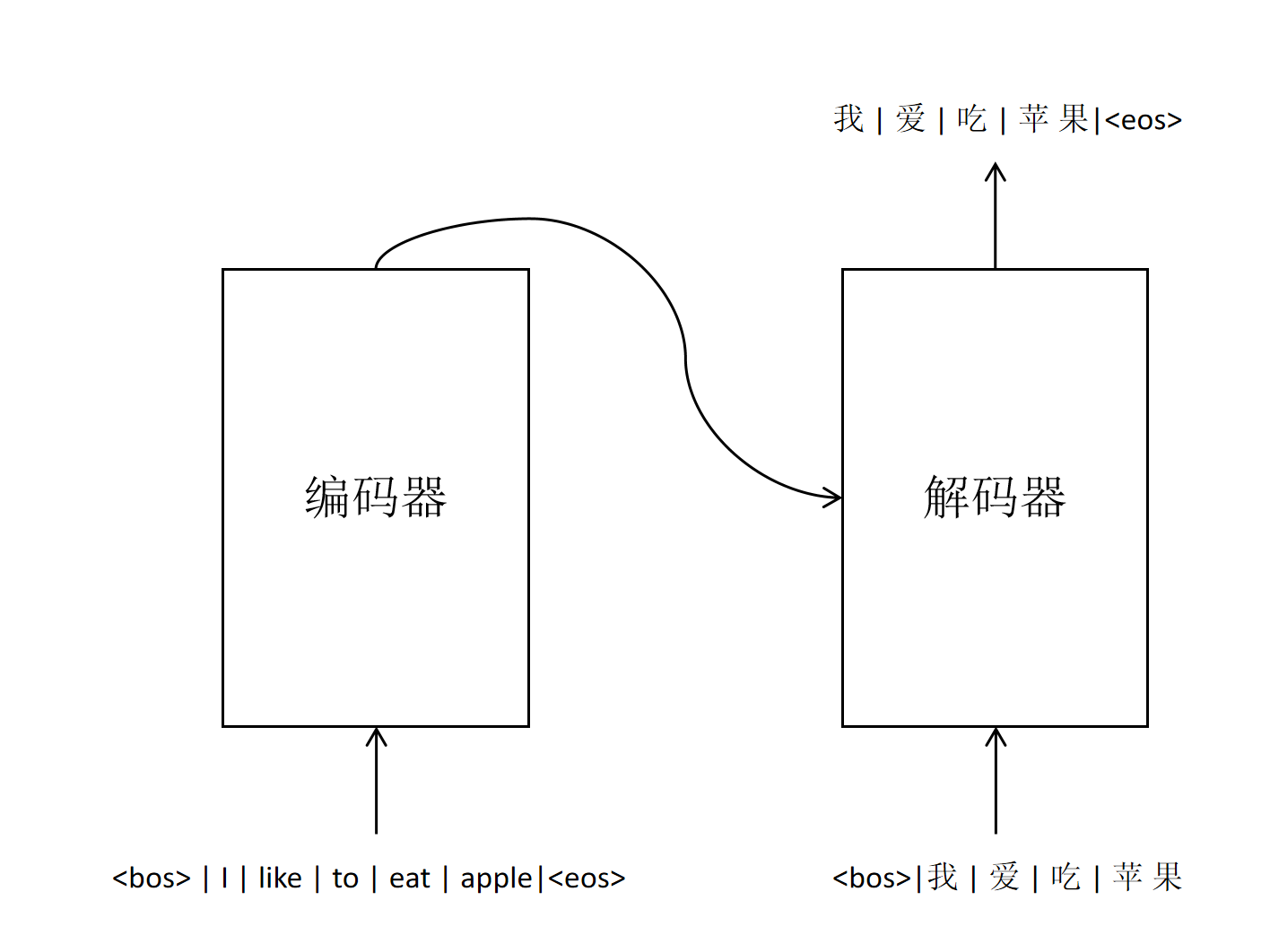 解码器的输入包含两个部分:
解码器的输入包含两个部分:
编码器输出 编码器输出的是英文序列里每个token的embedding。它的维度为512。经过多层编码器的自注意力机制,每个token的embedding都已经根据上下文,计算出恰当的语义信息。它们将作为解码器输出的重要参考。
已经翻译出来的token序列
Transformer的编码器可以一次性输入完整的英文token序列,但在模型进行实际翻译时,需要解码器逐个生成对应的中文token序列。
对于Transformer模型在推理时,解码器确实如上述过程所述,是逐个生成中文token的。但是在训练时,因为我们已经知道英文对应的中文token序列,所以我们可以通过一种叫做带掩码的多头注意力机制(Masked Multi-Head Attention,MMHA)来实现并行化训练。
对于上图中中文token序列:
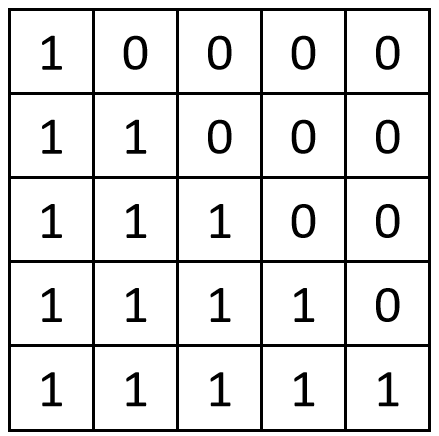
Mask矩阵每行表示当前token可以看到的token,1代表可以看到,0代表看不到。
比如第一行只有第一个位置为1,代表第一个token
第二个token 可以看到前两个token。
Transformer里只有注意力计算时是跨token,根据上下文更新自身embedding的。在进行注意计算时,不光传入Q,K,V矩阵,还需要传入这个Mask矩阵。让每个token在注意里计算时,根据mask矩阵,只关注自己以及前边的token。这样在一次训练里就可以对整个中文序列一次性进行训练了。
在实际代码实现时,先利用Q、K矩阵进行注意力计算,在softmax()前,把Mask矩阵为0的位置的注意力结果填充成一个非常大的负值,这样经过softmax()后,这些位置的值就都为0。在接下来计算当前token的特征值时,序列中Mask为0的token的权重就为0,代码如下:
def attention(query, key, value, mask, dropout: nn.Dropout):
d_k = query.shape[-1]
# (batch, h, seq_len, d_k) --> (batch, h, seq_len, seq_len)
attention_scores = (query @ key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
# 给mask为0的位置填入一个很大的负值
attention_scores.masked_fill_(mask == 0, -1e9)
# (batch, h, seq_len, seq_len)
attention_scores = attention_scores.softmax(dim=-1)
if dropout is not None:
attention_scores = dropout(attention_scores)
# (batch, h, seq_len, seq_len) --> (batch, h, seq_len, d_k)
return (attention_scores @ value), attention_scoreMask机制只能在训练时一次性对解码器所有位置的token进行训练。但是在模型训练好进行生成时,因为事先并不知道答案,只能一步生成一个新的token,然后拼接到解码器的输入,再生成下一个。
交叉注意力 Cross-Attention 观察Transformer模型架构图的Encoder Block部分,它也是6个,每个Encoder Block有两个注意力模块,一个全连接模块。我们上边讲了第一个注意力模块,Masked Multi-Head Attention模块,下边我们看关键的第二个注意力模块。
之前我们讲RNN的注意力时讲过,解码器是和编码器的输出计算注意力,然后取解码器的输出的注意力加权值。这种注意力计算是两个不同序列的,我们叫做交叉注意力 Cross-Attention。
Corss-Attention是非常重要的一步,它是解码器从编码器获取信息的唯一途径。从模型架构图中可以看到,交叉注意力模块的K和V矩阵来自编码器的输出。Q矩阵来自解码器部分。所以解码器根据当前翻译的需要提出查询向量q,和所有编码器输出的k进行匹配,计算注意力。最终得到编码器输出的v的注意力加权值。
def forward(self, x, encoder_output, src_mask, tgt_mask):
# 第一个自注意力模块,Q、K、V都来自自身。
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tgt_mask))
# 第二个交叉注意力模块的Q矩阵来自Decoder,K,V矩阵来自Encoder的输出。
x = self.residual_connections[1](x, lambda x: self.cross_attention_block(x, encoder_output,encoder_output, src_mask))
# 全连接模块。
x = self.residual_connections[2](x, self.feed_forward_block)
return x解码器最终会接一个线性分类头,输入是512,输出维度是字典的大小。线性层的输出再经过softmax()之后,就是字典里每个token作为输出下一个token的概率值。
15.5.6 解码器实现
class DecoderBlock(nn.Module):
def __init__(self, features: int, self_attention_block: MultiHeadAttentionBlock,
cross_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock,
dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(3)])
def forward(self, x, encoder_output, src_mask, tgt_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tgt_mask))
# 交叉注意力模块的Q矩阵来自Decoder,K,V矩阵来自Encoder的输出
x = self.residual_connections[1](x, lambda x: self.cross_attention_block(x, encoder_output,encoder_output, src_mask))
x = self.residual_connections[2](x, self.feed_forward_block)
return x
class Decoder(nn.Module):
def __init__(self, features: int, layers: nn.ModuleList) -> None:
super().__init__()
self.layers = layers
self.norm = LayerNormalization(features)
def forward(self, x, encoder_output, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.norm(x)15.5.7 完整代码
完整代码可以从github下载transformer.py。