13.7 注意力机制
注意力机制是一个可以显著提升序列到序列模型的技术。我们这一节就来一探究竟。
13.7.1 序列到序列模型的问题
假如我们要做一个英文翻译到中文的模型,需要翻译的英文为:
“Since I started writing this book on December 6, 2024, 193 days have passed. I’m truly grateful that I’ve been able to keep going until now. I will continue writing until the book is complete, and I hope it will be helpful to everyone.”
它对应的中文为:
“自从我在2024年12月6日开始写这本书以来,已经过去193天了,我非常庆幸自己能够坚持到现在。我会继续写下去,直到这本书完成,也希望这本书能对大家有所帮助。”
翻译问题需要用到我们之前介绍的Encoder-Decoder的模式,如下图所示:
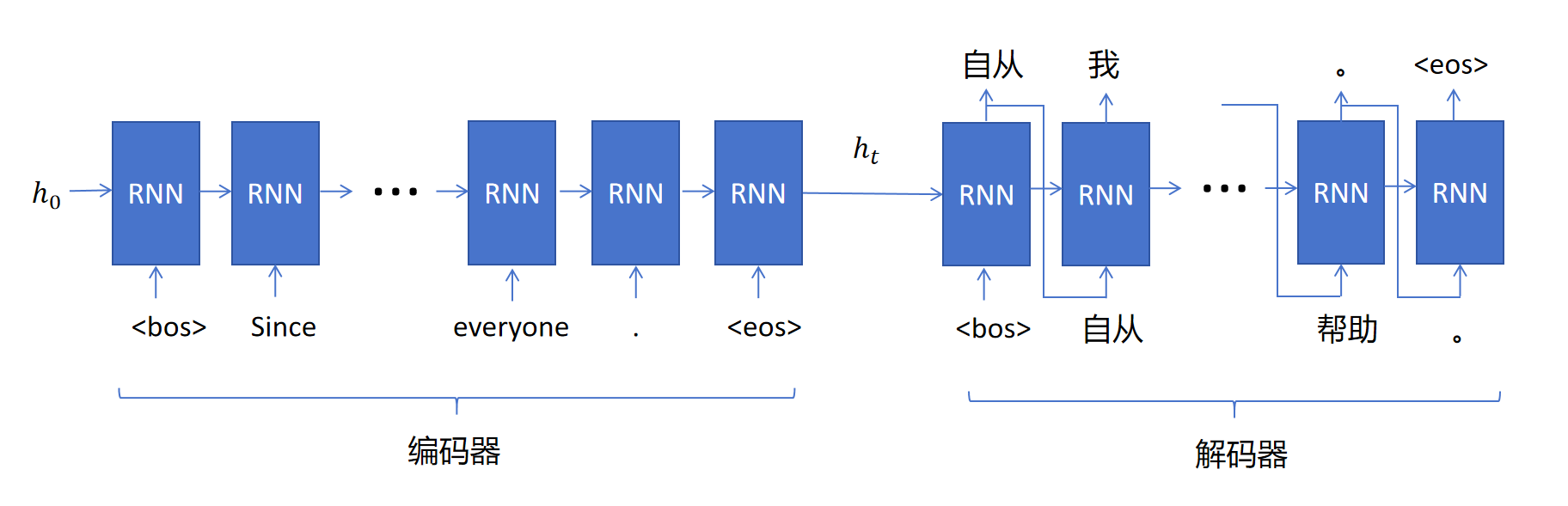
在Encoder阶段,读入所有的英文token,最后只有一个隐状态传递给Decoder。Decoder阶段,第一个时间步的输入有两个:分别是代表序列开始的<bos> token,和Encoder传递来的隐状态。输出为中文的第一个token,和Decoder第一个时间步的隐状态。然后把输出的第一个中文token的embedding作为下一个时间步的token输入,外加上一时间步的隐状态,输出第二个中文token。依次类推,直到某个时间步Decoder输出的token为序列结束符<eos>。
你可能会有一个担心,输入的英文句子很长,并且里边还有大量的比如时间这样的细节信息,这些信息都可以被压缩到Encoder最终输出的这一个隐状态里吗?答案是并不能,这种结构在输入句子较短的时候表现还可以,但是随着输入句子的长度增加,效果会随之下降。
13.7.2 注意力机制
我们人类是如何进行长句的翻译呢?我们也不是一次性记住所有要翻译的句子,然后一次性全部翻译。我们会在翻译时,时不时的把注意力放在原始的英文句子的某些部分,然后逐步的生成中文的翻译。注意力机制就是模拟人类这种翻译方法,让Decoder在生成内容时,可以把注意力放在Encoder不同时间步的隐状态上作为参考信息。
所以添加了注意力机制的Encoder-Decoder RNN在Decoder生成内容时,它有以下几个输入:
上一时刻的隐状态(LSMT还有上一时刻的细胞状态)。
上一时刻输出token的embedding(上一时刻的输出就是这一时刻的输入)。
通过注意力观察后的Encoder不同时间步的隐状态(即使是LSTM,也只用隐状态。因为隐状态更能代表当时时间步的信息,细胞状态是长期记忆信息)。
注意力机制其实很简单,就是将Encoder在每个时间步,也就是对每个英文token生成的隐状态的值进行加权求和,权值之和为1。
其中是标量,表示在翻译当前token时对的注意力,且。为第i个时间步,也就是第i个英文token输出的隐状态向量。
有了注意力向量,将它与每个时间步输入的中文token的embedding进行拼接作为输入就实现了带注意力的Encoder-Decoder RNN了。
我们就剩下一个问题了,那就是如何计算注意力权重? 在翻译过程中,对于不同的时间步,需要关注的点,注意力权重是不一样的。在Decoder不同时间步,对Encoder中不同英文token输出的隐状态的注意力是不同的。具体注意力权重的值是通过一个简单的神经网络来计算的。我们通过下边这个例子来详细解释。
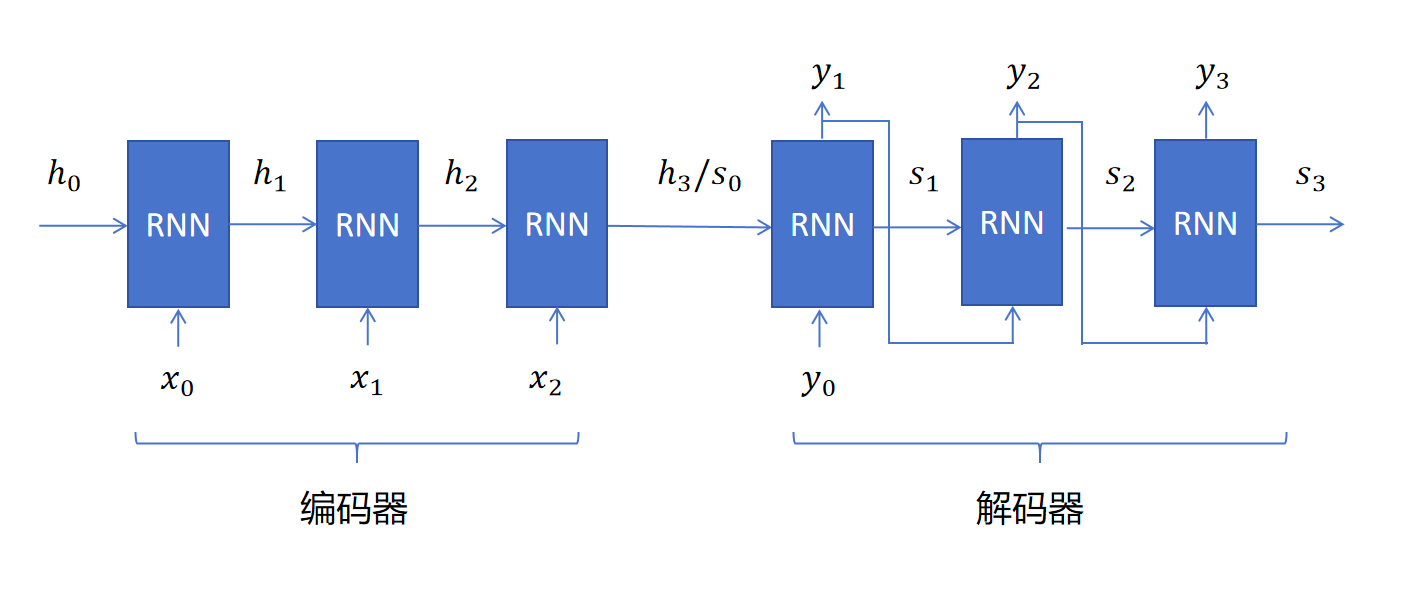
假设Encoder输入3个英文token,分别为。初始隐状态为,三个时间步对应的隐状态分别为。将作为解码器的隐状态输入,为了区分,Decoder的隐状态用s表示。所以。Decoder每一步生成的中文token,作为下一时间步的输入。并且中间产生隐状态。这个图里边是没有增加注意力机制的Encoder-Decoder RNN,这里我们只是定义了符号,接下来我们看如何计算注意力权值。
我们以Decoder第一个时间步的注意力向量为例,需要生成对的注意力权重值,并且需要保证。则注意力向量就等于:
我们定义一个简单的神经网络FCN,假设它只有一层,输出层,输出层只有一个神经元。首先将分别和进行拼接,得到3个输入向量,然后经过FCN,得到3个标量的logits值,再对这3个个logits值应用softmax,就得到了的具体注意力权重值了。
Decoder第二个时间步的注意力向量为,它也需要计算当前时间步对的注意力权重值。做法和上一个时间步一样,将分别和进行拼接,得到3个输入向量,然后经过FCN,得到3个logits值,再对这3个个logits值应用softmax,就得到第二个时间步对的注意力权重:了。
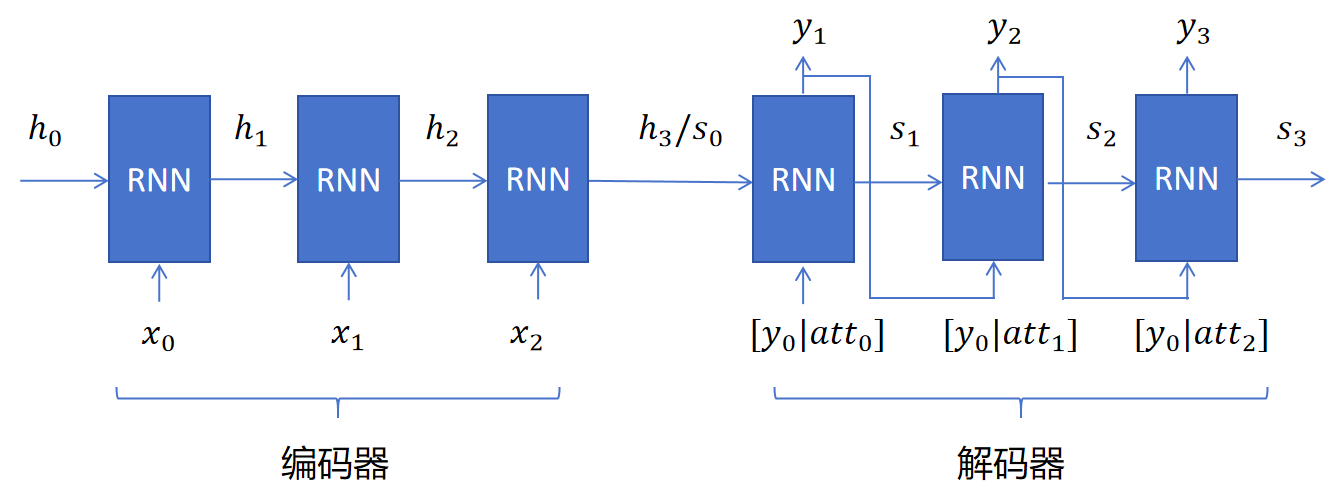 带注意机制的Decoder部分,每个时间步不光有隐状态输入,还有注意力向量和上一步输出token的embedding进行拼接的向量作为输入。
带注意机制的Decoder部分,每个时间步不光有隐状态输入,还有注意力向量和上一步输出token的embedding进行拼接的向量作为输入。
13.7.3 总结
上边我们以RNN进行讲解,实际上可以替换为LSTM,GRU。另外在计算注意力时,我们讲的是最简单的情况,只有一个输出层,实际大部分情况下我们会添加一层隐藏层。上边我们是以翻译为例子,注意力机制也可以应用到其他序列到序列的模型里。