16.2 BERT
GPT-1的成功让人们看到了在NLP领域“预训练+微调”模式的可行性,GPT-1是Decoder-Only的架构。BERT(Bidirectional Encoder Representations from Transformers)的作者认为GPT-1的注意力是单向的,也就是每个token只能关注它前面token的信息。但是对于NLP任务,双向注意力可以看到序列里所有token的信息,这样对于上下文理解会更加全面,应该会取得更好的效果。
16.2.1 BERT模型架构
BERT是一个Encoder-Only的架构。它采用了Transformer里的Encoder部分的架构。
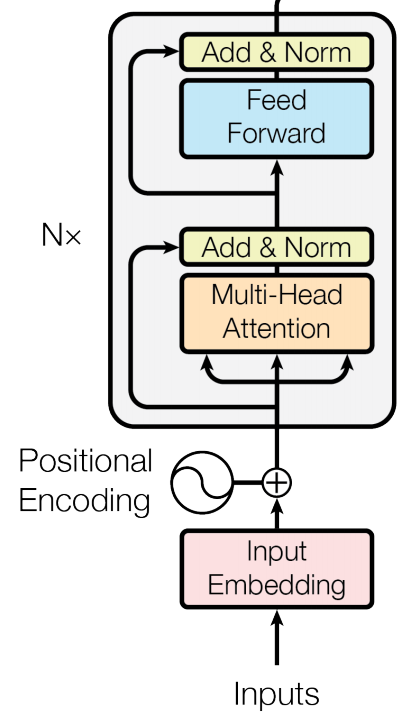
BERT里将Encoder模块的层数用L表示,Token Embedding和隐藏层大小用H表示,自注意力的头用A表示。然后推出了两种大小的BERT模型。
BERT_base:(L=12,H=768,A=12) 总参数量为110M。这个大小与GPT-1是同样参数规模的,就是用来和GPT-1比效果的。
BERT_large(L=24,H=1024,A=16)总参数量为340M。
BERT也是采用了“预训练+微调”的模式。在预训练期间,BERT通过不同的预训练任务在未标记的数据上进行模型训练。 对于微调,首先使用预训练的参数初始化 BERT 模型,然后使用下游任务中的标记数据对所有参数进行微调。 每个下游任务都有单独的微调模型,即使它们使用相同的预训练参数进行了初始化。BERT 的一个特征是其跨不同任务的统一结构。也就是BERT预训练的结构和最终的下游任务在模型结构之间的差异很小。
16.2.2 输入和输出
BERT可以解决NLP领域的两类问题,一类是序列级别的问题,一类是token级别的问题。
序列级别的问题
序列级别的问题也分为两类,一类是单个序列的,比如对一句话进行正面和负面情绪的判别。一类是两个序列的,比如判断两句话的蕴含关系。所以这就需要BERT在输入设计上能够支持单个序列,也要能支持两个序列。输出上需要有一个位置可以输出对单个或者多个序列进行总结的信息。
Token级别的问题
Token级别的问题类似NER,它需要BERT能够为每个token输出它在上下文中的含义信息。
所以最终BERT的输入如下:
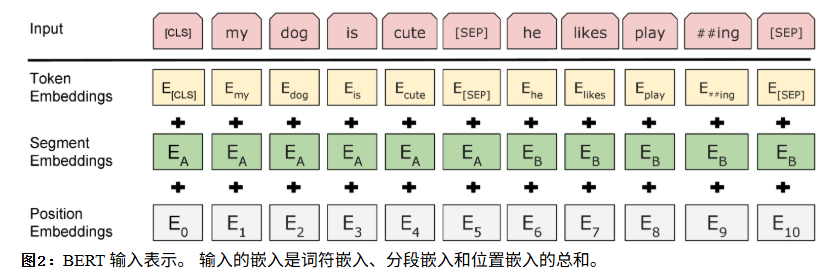 上图中最上边的Input是原始输入,我们给所有的输入前增加一个特殊的[cls] token,它是一个占位符,将来在BERT Encoder Block最后一层第一个位置的输出向量,就代表了整个输入的全局信息。利用这个信息,加一个分类头就可以对序列(单序列或者多序列)进行分类。我们发现Input中间还有一个[SEP] token,它就是序列的分隔符,用来隔开两个序列的。通过这个token,让模型知道这个token的前后属于不同的序列。
上图中最上边的Input是原始输入,我们给所有的输入前增加一个特殊的[cls] token,它是一个占位符,将来在BERT Encoder Block最后一层第一个位置的输出向量,就代表了整个输入的全局信息。利用这个信息,加一个分类头就可以对序列(单序列或者多序列)进行分类。我们发现Input中间还有一个[SEP] token,它就是序列的分隔符,用来隔开两个序列的。通过这个token,让模型知道这个token的前后属于不同的序列。
对于token级别的任务,每个token位置最后一层Encoder的输出的向量就代表了这个token结合上下文后的表示信息,加一个分类头就可以进行NER分类了。对于所有token都共享一个NER分类头。
上图中下边有3个不同的Embedding。它们按位相加,构成了序列最终的输入向量。
Token Embedding,就是每个token的词向量,代表了每个token的原始含义。此时还没有上下文信息。字典里每个token都有一个Embedding,并且是可学习的参数。
Segment Embedding,用于区分每个token属于哪个序列的Embedding,每个序列共享一个Embedding,也是可学习参数。
Position Embedding,用于给每个位置一个Embedding,不同与Transformer里用sin和cos函数生成固定位置编码,这里的位置编码也是可学习参数,让模型在训练中自己学习。
16.2.3 预训练BERT
因为BERT预设是可以同时解决序列级别问题和token级别的问题。所以预训练时就必须设计能提取token上下文信息和序列信息的任务。
Token级别任务:遮蔽语言模型
遮蔽语言模型(Masked Language Model),是随机将输入token中的一些进行mask,替换为[MASK] token。然后在BERT输出时,根据[MASK]token的输出向量加一个分类头,预测出原始被遮蔽的token id。这个任务就是填空题,锻炼模型根据上下文信息猜出空缺token的能力。这样训练模型就让模型能更高的提取token级别的上下文信息。但是为了防止模型只是在输入[MASK]这个token时才刻意提取它的上下文信息,实际BERT在训练时,先随机选择15%的token做最终的token id预测。在这15%的token里,80%的概率用[MASK] token替换原来的token,10%的概率随机替换为其他token,10%的概率保持原有token不变。经过这样的数据设计,BERT模型就可以很好的提取没个token的上下文信息了。
序列级别任务:下一句预测
很多NLP下游任务,比如问答,自然语言推理,都是基于理解两个句子的关系。BERT设计的序列级别的任务是判断两个句子是否是连续的。在预训练样本中采集两个连续的句子作为正样本,两个不连续的句子作为负样本,提取[cls] token 最后一层的输出向量加一个分类头,进行二分类判断。这个任务可以很好的让[cls]token提取序列级别的上下文信息。
对于预训练数据,BERT使用了BooksCorpus(800万个单词)和英文的Wikipedia(25亿个单词)。
16.2.4 微调BERT
BERT的微调很简单,只需要按照问题类型组织输入token即可。比如是两个序列,就在序列之间加[SEP] token,并且设置合适的Segment Embedding。
另外根据不同的任务,利用输出不同位置token的输出,加上分类头来进行下游任务。序列级别的就提取[CLS] token的输出,token级别的就提取每个token的输出。
BERT进行微调时,只有分类头是全新的随机初始化的,其他参数,包括Encoder和Embedding都是预训练好的,进行全参数量的微调。
16.2.5 BERT的意义
BERT 在概念上很简单,在实际应用中非常强大。 它在 11 种自然语言处理任务上获得了当时最优结果,包括将 GLUE 得分提高到 80.5%(提升绝对值 7.7%),MultiNLI 准确度达到 86.7%(提升绝对值 4.6%),SQuAD v1.1 问答测试 F1 达到 93.2(提升绝对值 1.5 个点)以及 SQuAD v2.0 测试集 F1 达到 83.1(提升绝对值 5.1 个点)。
BERT是NLP领域第一个火出圈,现象级的预训练模型,在大语言模型出来之前,BERT就是NLP领域最受人瞩目的模型。大多数的NLP问题,仅需要少量的标注数据,甚至几百个,就可以达到非常不错的效果。