18.3 DeepSeekV2
DeepSeekV2的论文题目为: A Strong, Economical, and Efficient Mixture-of-Experts Language Model 可以翻译为《一种强大、经济且高效的混合专家语言模型》。这一节我们就来看一下DeepSeekV2都做了什么改进。
18.3.1 模型架构
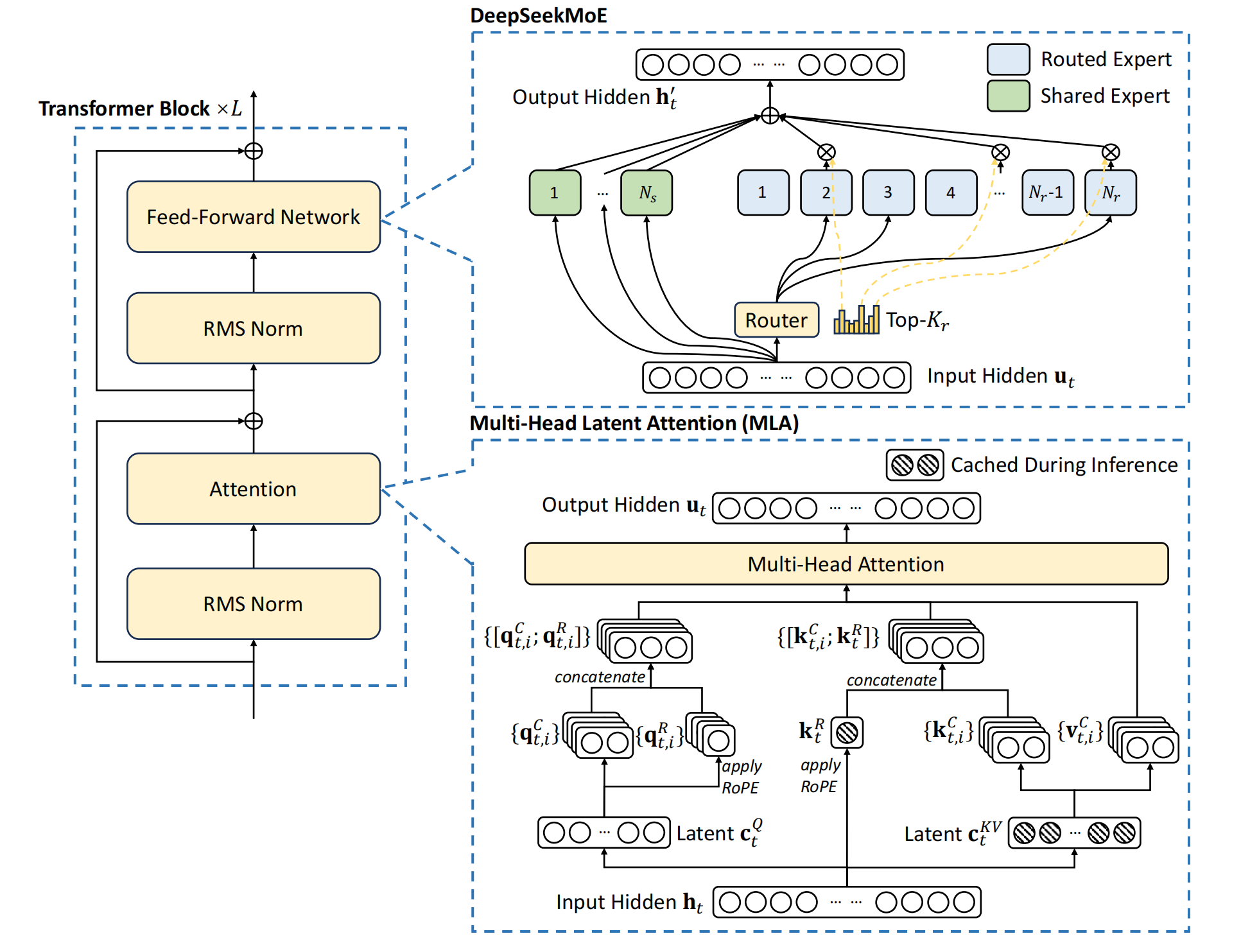
可以看到DeepSeekV2是由多个Transformer Block构成。每个Transformer Block里由RMS Norm, Attention, Feed-Forward Network几个模块,以及残差连接构成。
上一节我们讲了DeepSeek-MOE对Feed-Forward Network模块进行了修改,它由多个专精的专家以及共享专家构成。这个改动在DeepSeek V2里依然保留。同时,在DeepSeek V2里也对注意力层进行了修改。提出了MLA (Multi-Head Leitent Attention),多头潜在注意力机制。
18.3.2 KV Cache
之前我们提到过KV Cache。它是一种为了加快模型推理时生成速度,减少不必要重复计算的技术。因为语言模型逐个token生成的原理,每次生成一个token,并将新生成的token拼接到原始输入,再生成下一个token。但是因为序列前边的token,在mask机制的限制下是看不到后边token的。所以后边新生成的token,并不会改变之前token在Transformer Block里每层的计算。但是后边生成新的token时,是可以看到它前边的token的。需要和前边的token的k,v向量进行注意力计算,生成新token的上下文表示向量。所以,就将每个token各层的k和v向量进行存储,避免每次重复计算,并可被新生成token时计算注意力时使用。
18.3.3 MQA,GQA,MHA
随着序列的生成,KV Cache会逐渐增大,导致显存不足,不能进行更长序列的生成。之前我们介绍过有一种技术可以减少KV Cache,那就是多查询注意力(MQA)和分组注意力机制(GQA)。这种技术通过在多头之间共享k,v向量的方式相比多头注意力机制(MHA)减小了KV Cache,同时也减少了生成k,v向量时的计算量。
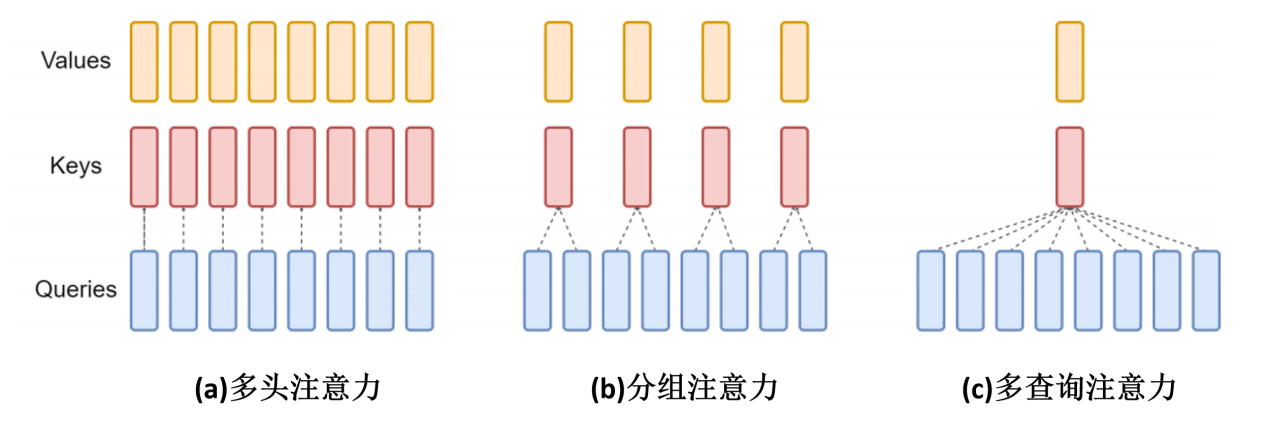
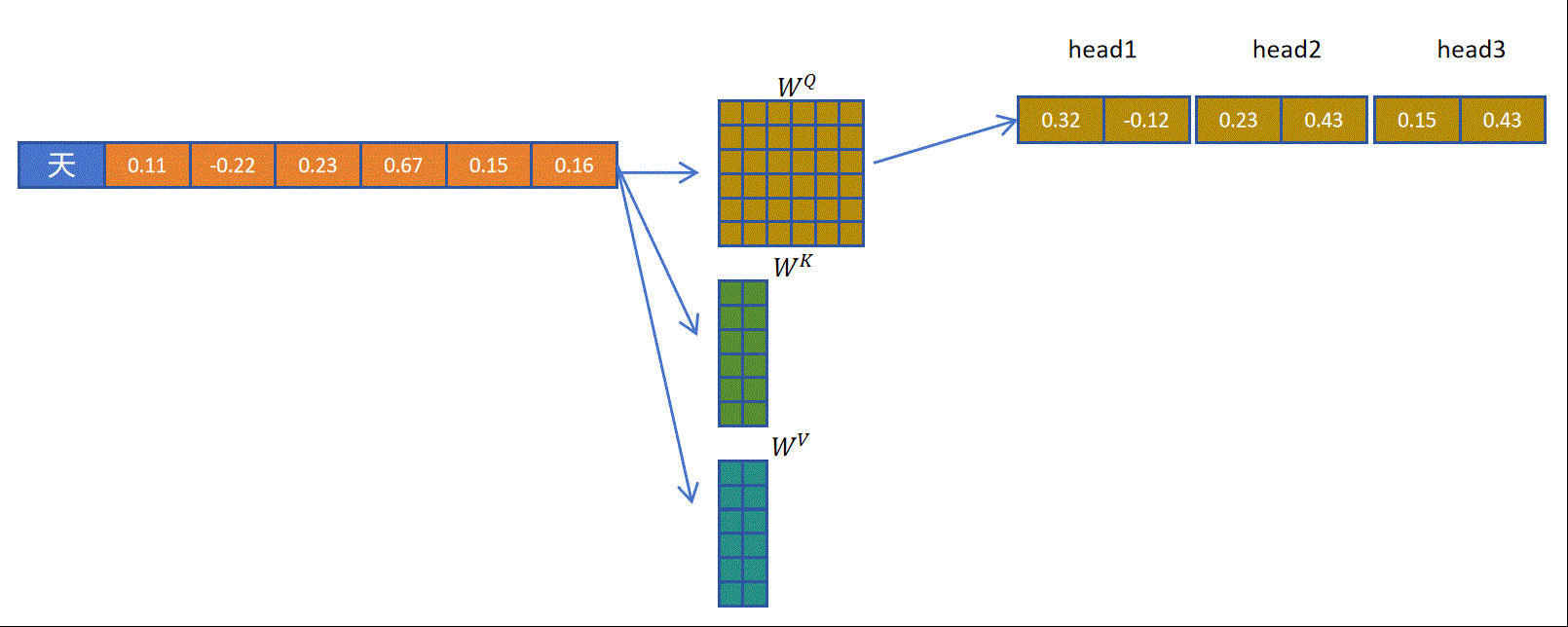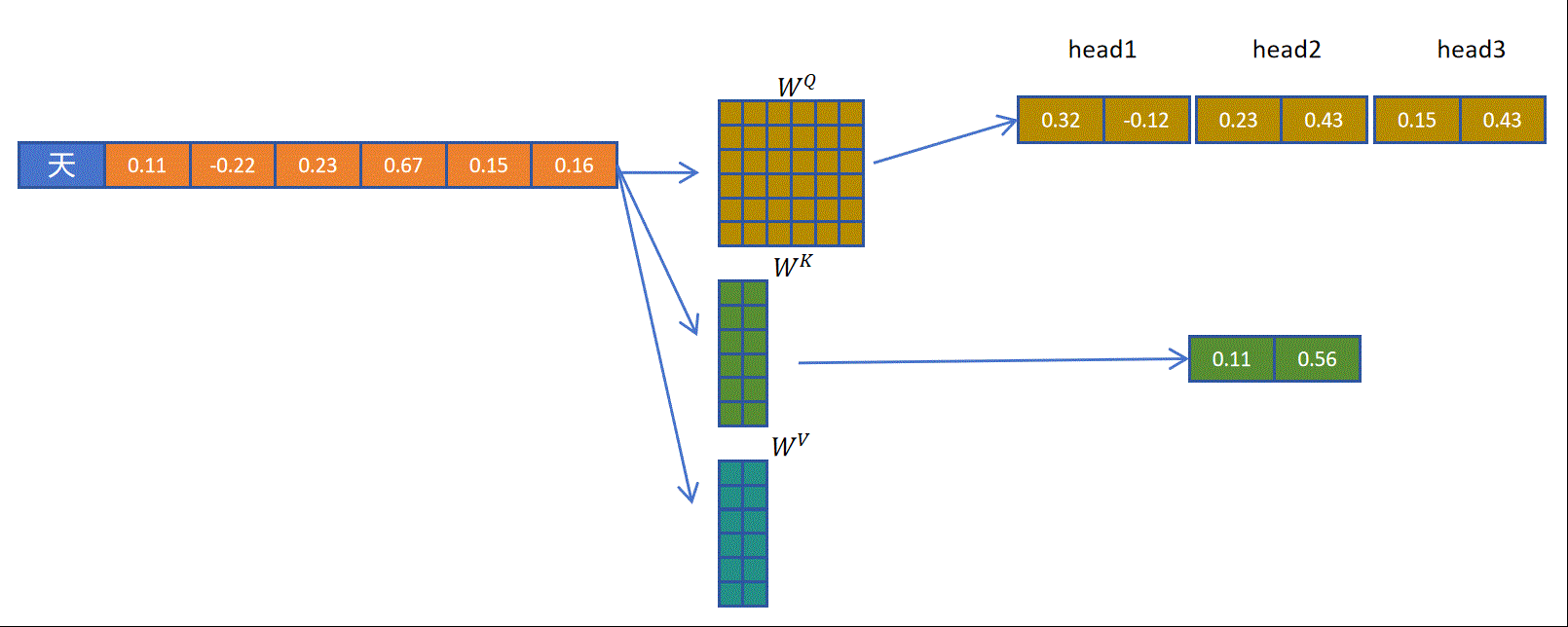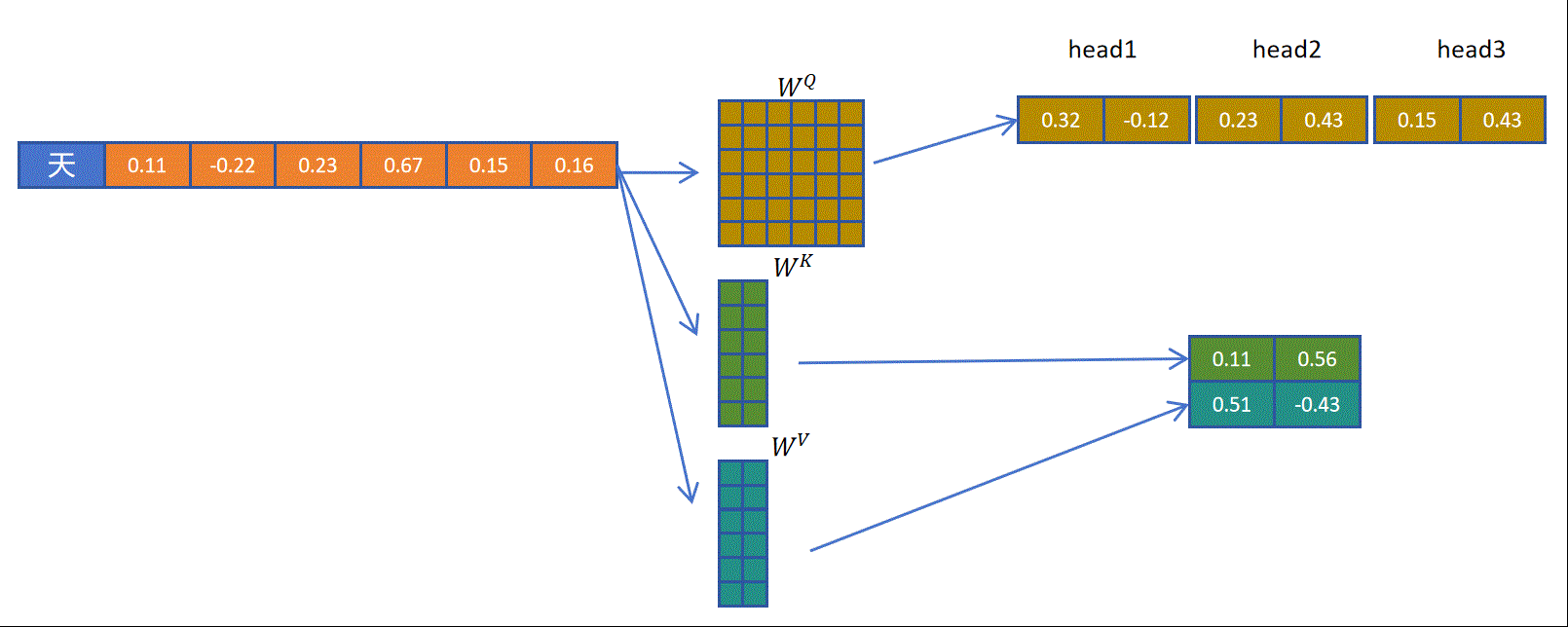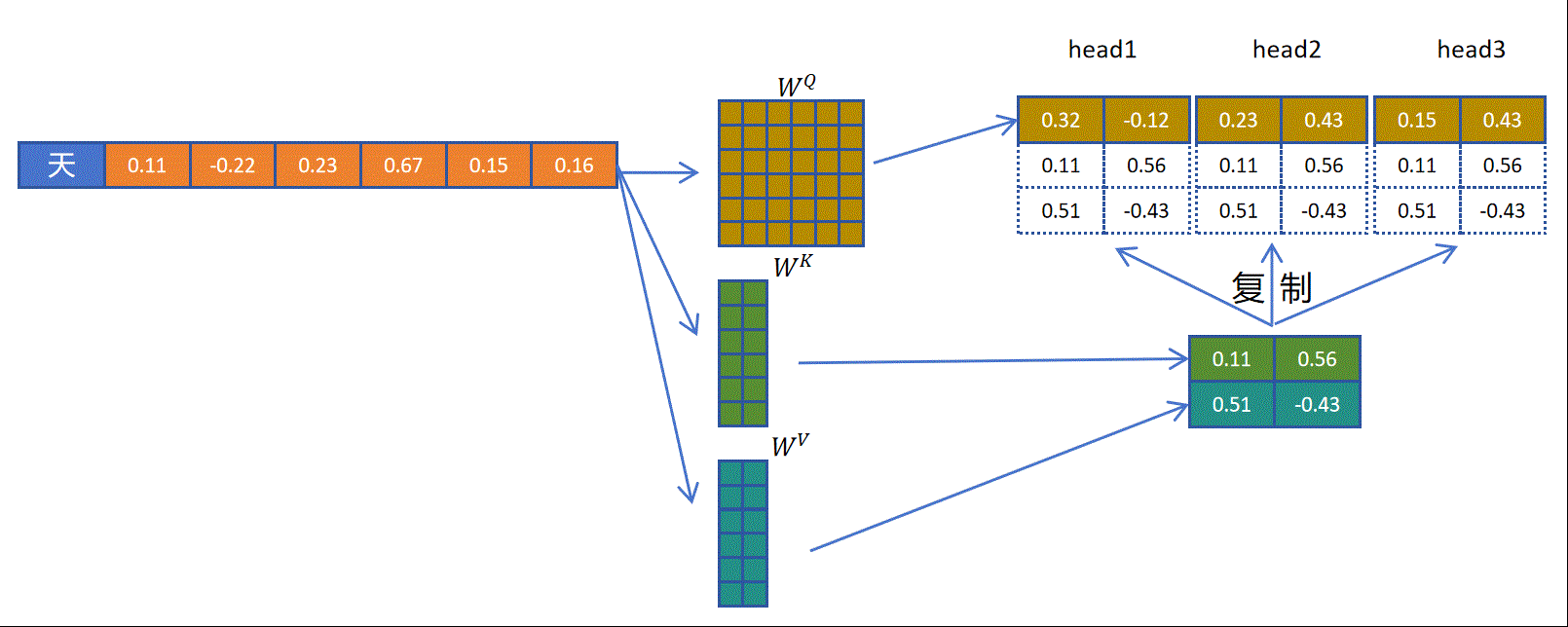 以多查询注意力机制为例,对于一个token而言,通过一个完整的权重矩阵,生成多头的q向量。然后通过一个小的矩阵生成一个头大小的k向量,再通过一个小的向量生成一个头大小的v向量,然后将一个头大小的k,v向量共享给多个头。这样可以达到多个效果,减少了的参数量,减少了生成k,v向量的计算量,减少了KV Cache的缓存量,减小了缓存占用。
以多查询注意力机制为例,对于一个token而言,通过一个完整的权重矩阵,生成多头的q向量。然后通过一个小的矩阵生成一个头大小的k向量,再通过一个小的向量生成一个头大小的v向量,然后将一个头大小的k,v向量共享给多个头。这样可以达到多个效果,减少了的参数量,减少了生成k,v向量的计算量,减少了KV Cache的缓存量,减小了缓存占用。
但是DeepSeek经过试验表明,这种多个头之间共享k,v向量的做法是以性能衰减为代价的。
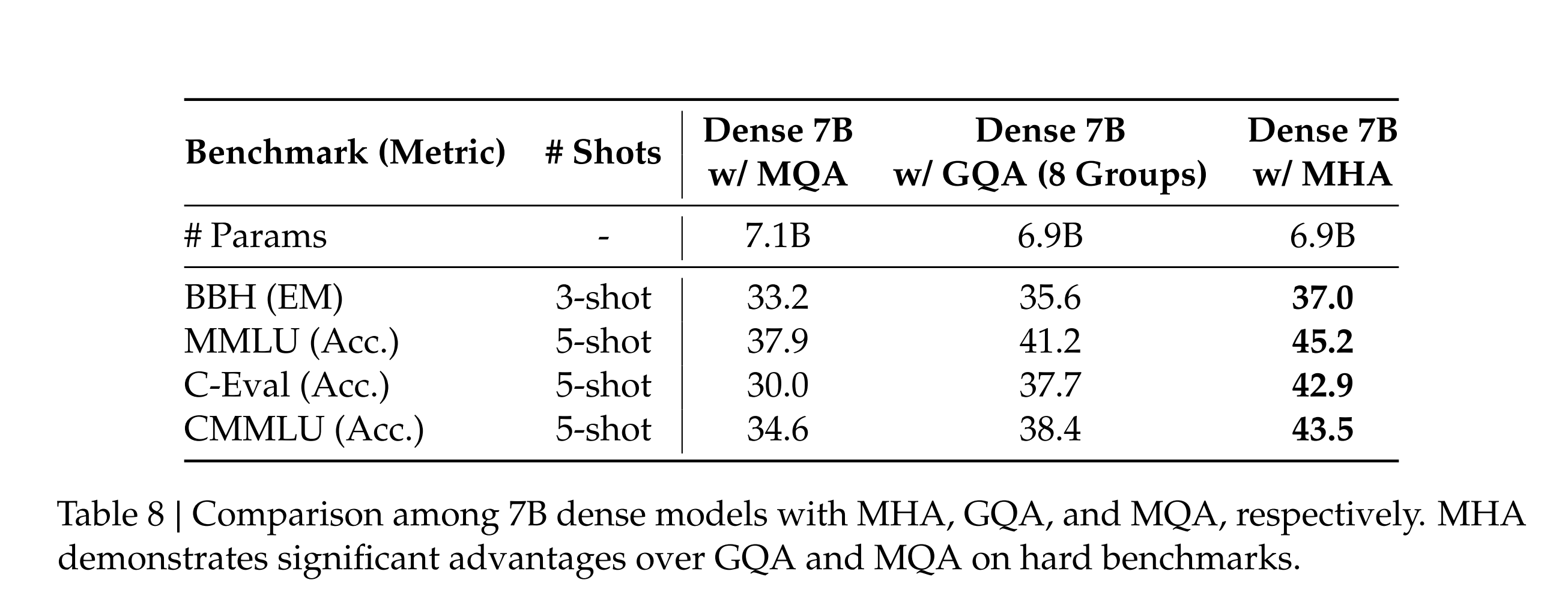 可以看到同等参数量的MQA,GQA,MHA,还是传统的多头注意力机制(MHA)效果最好,MQA共享最多,性能也最差。
可以看到同等参数量的MQA,GQA,MHA,还是传统的多头注意力机制(MHA)效果最好,MQA共享最多,性能也最差。
18.3.4 MLA
DeepSeek找到一种可以减少参数量,计算量,缓存量,并且不影响模型性能,甚至模型性能还能提升的方法,那就是多头潜在注意力机制,MLA (Multi-Head Leitent Attention)。

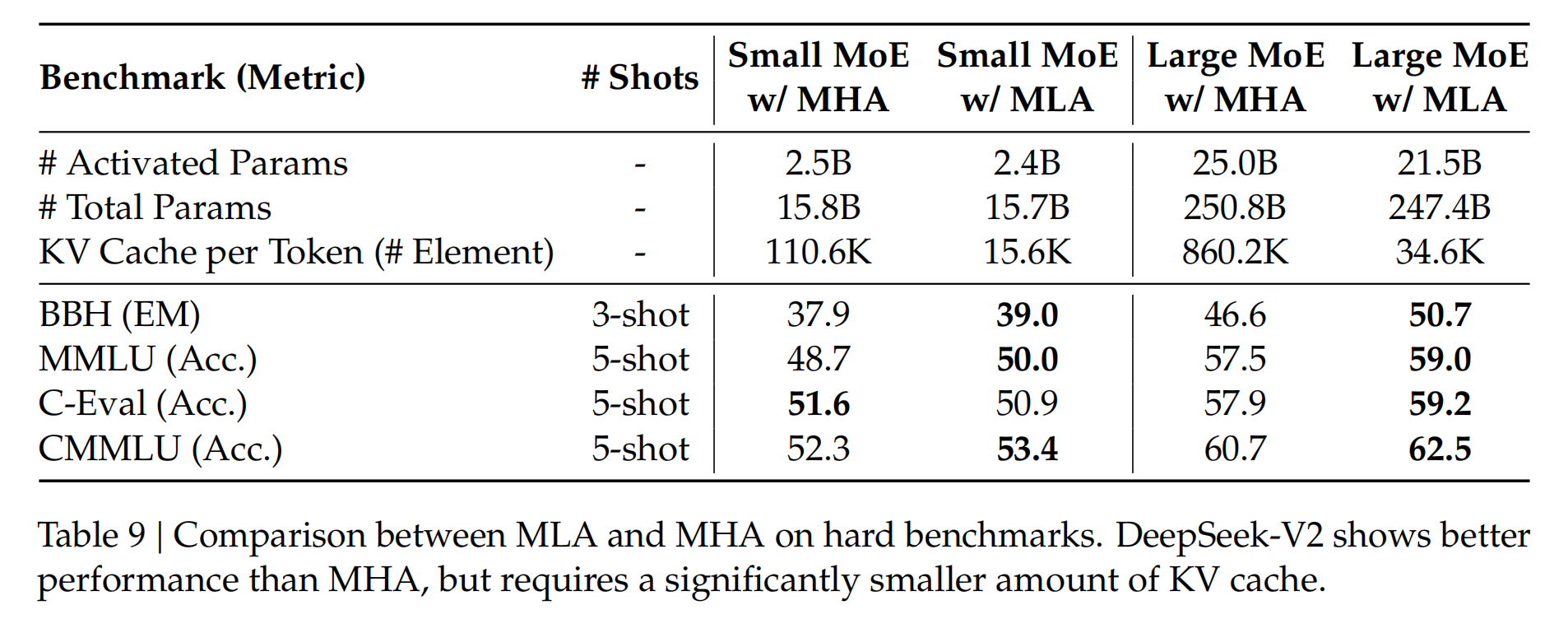
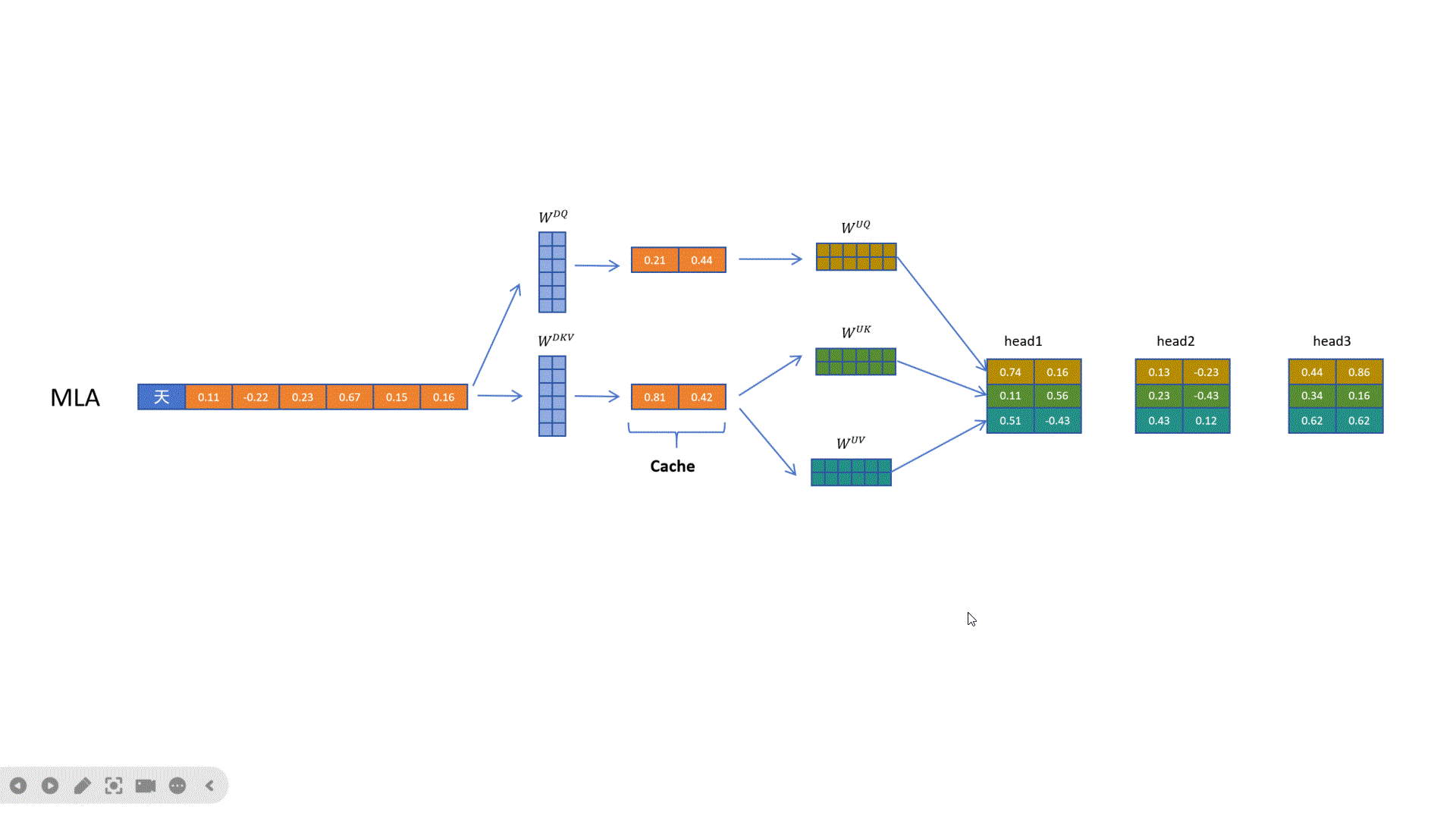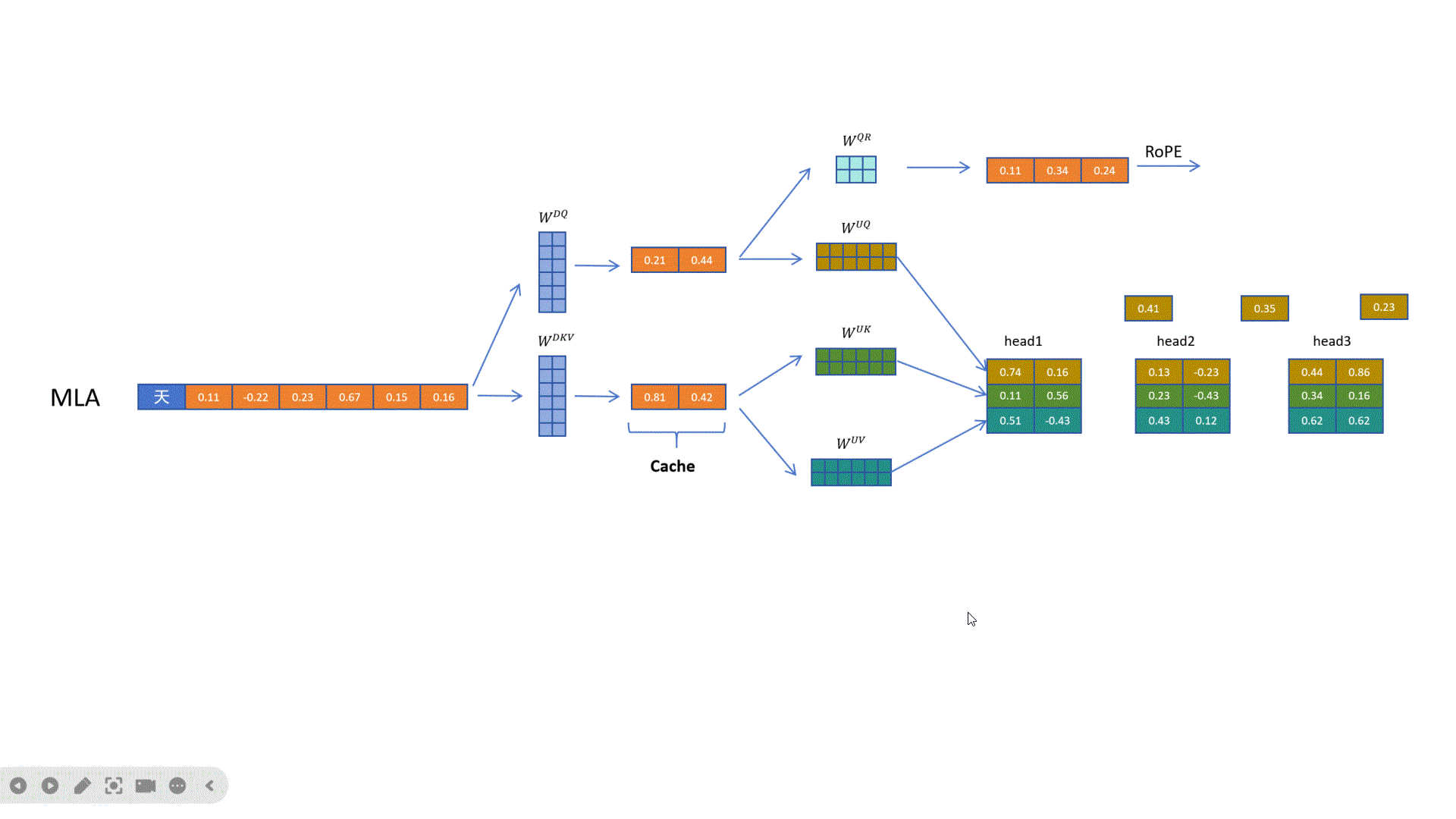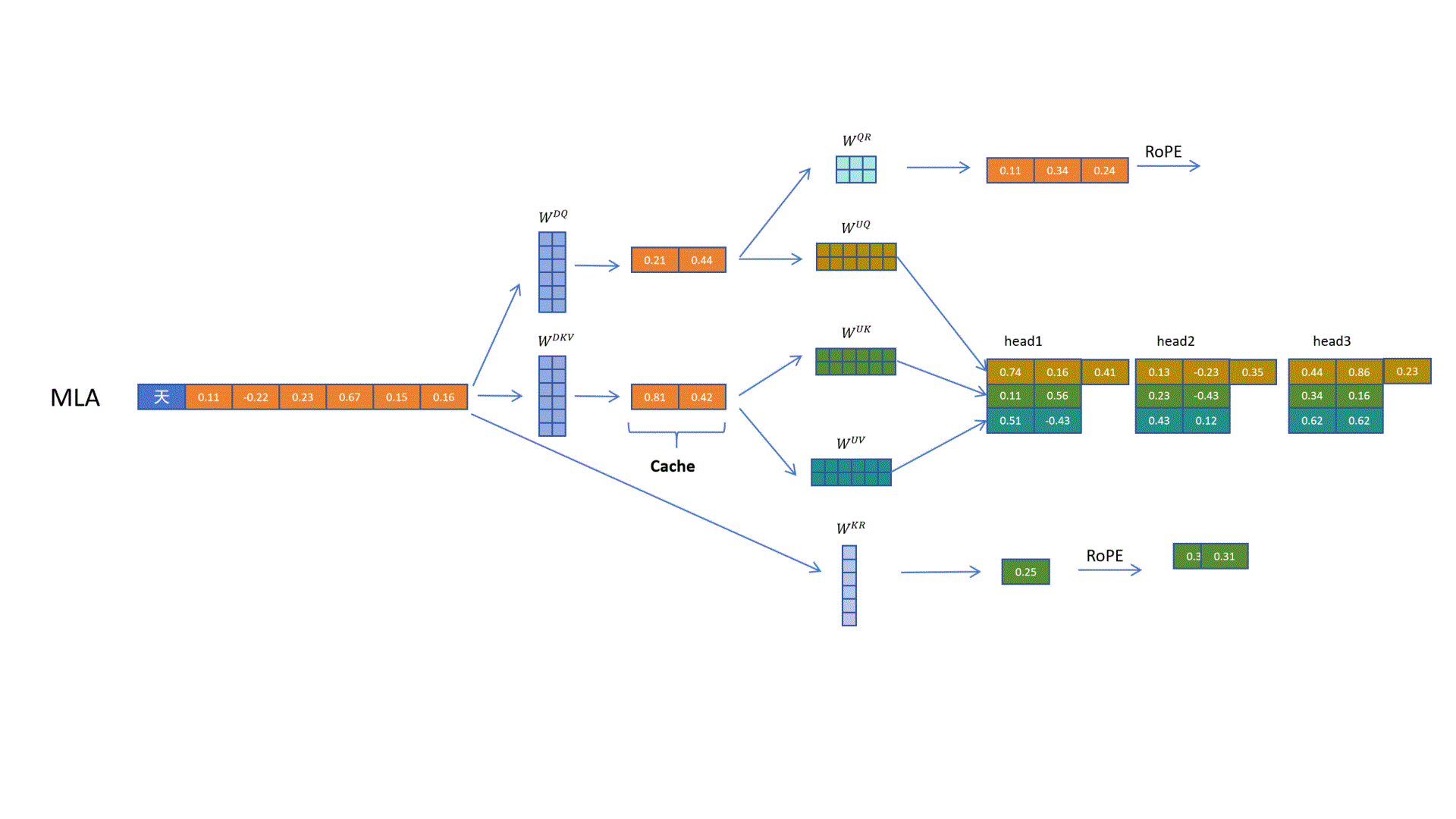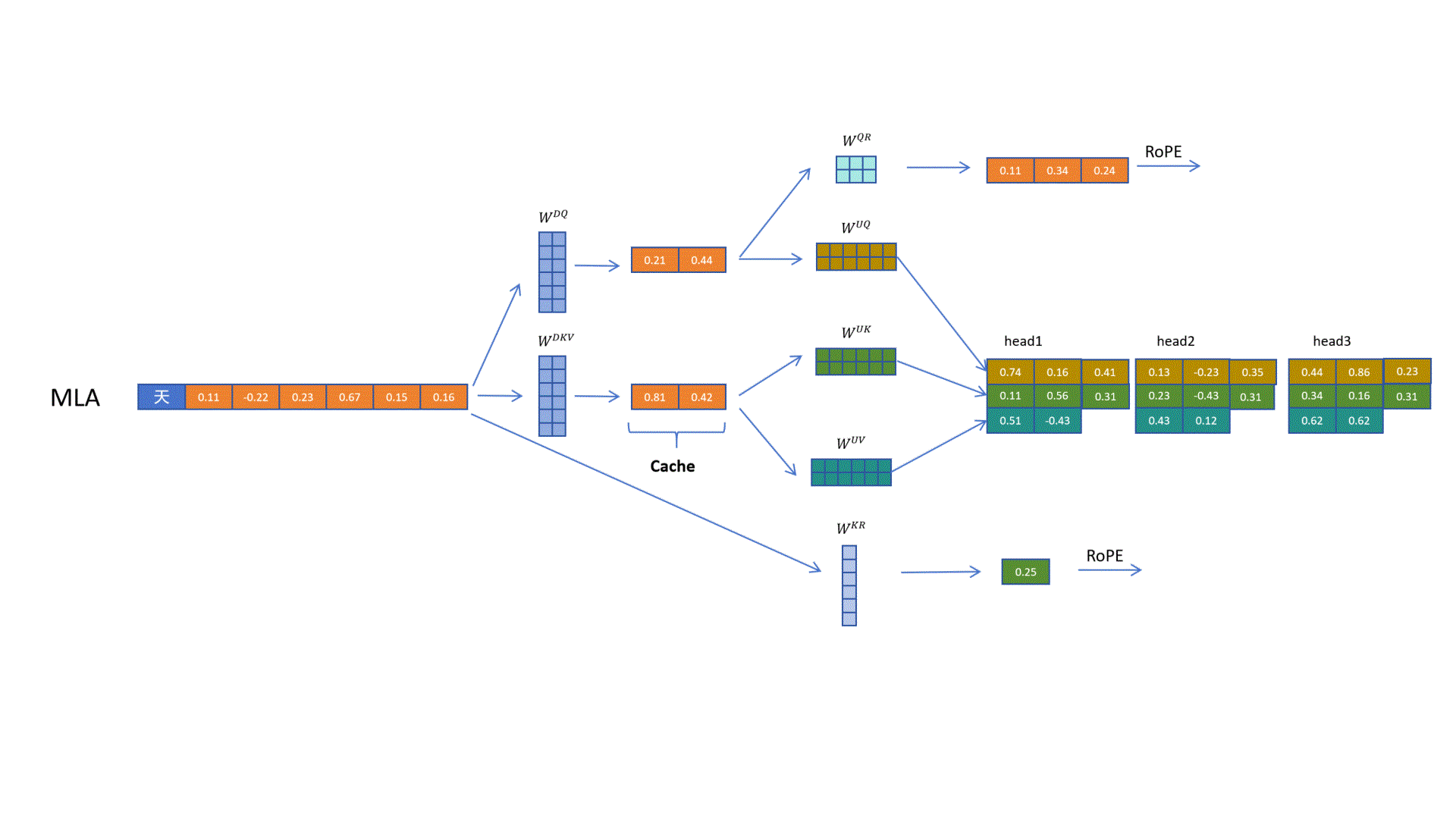
它的原理非常简单,就是对token的特征向量首先通过一个参数矩阵进行压缩转化,这个参数我们把它叫做,上标中的D是down的意思,是向下压缩的意思,KV,就是k向量和v向量的意思。比如这里原来特征维度为6,经过,压缩到2维。然后缓存时只需要缓存这个2维的kv压缩特征。在进行计算时,需要用到真实的k和v向量时,再从KV压缩向量通过两个解压矩阵转化为原来的维度就可以了。把KV压缩向量进行解压,投影到实际K向量维度的参数矩阵叫做,上表中的U代表up的意思,向上升维,k代表k向量。同理,对v向量进行解压升维的参数矩阵叫做。
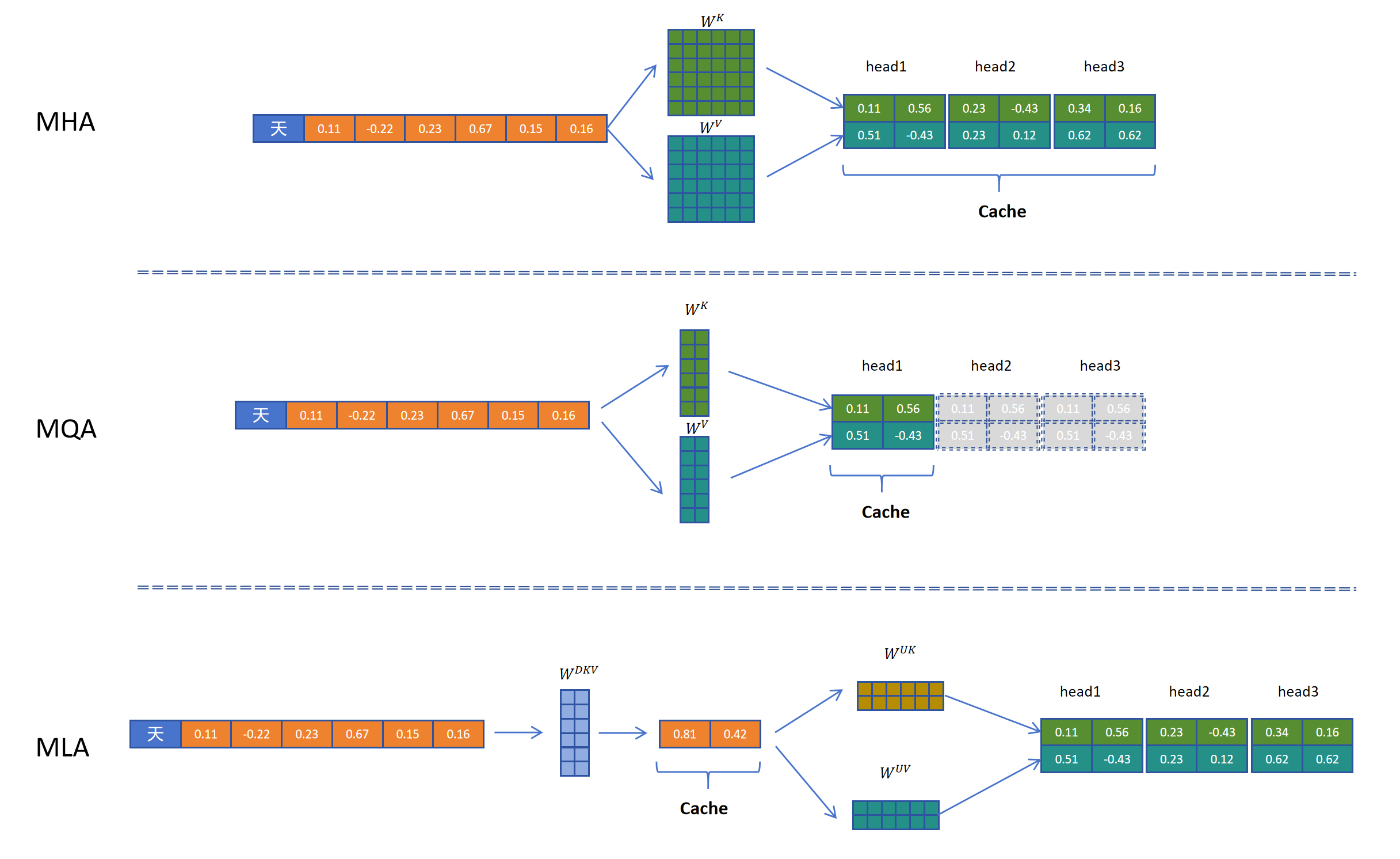
通过上边的图可以看到通过与MHA,MQA相比,MLA是缓存量最小的一种技术。同时DeepSeek也在小参数量模型(15.8B)和大参数量(250B)做了测试,MLA的模型性能竟然比MHA好要好,如下图所示:
18.3.5 计算合并
这一切看起来都非常不错,但是KV Cache的本意是什么呢?它是为了减少推理时对之前token k和v向量的计算而产生的。MLA因为缓存了压缩的KV Cache而减少了KV Cache的显存占用,但是在取出缓存后,不能直接用,还要经过解压计算才可以。这不是在推理时又引入了额外的计算吗?这和KV Cache的初衷相悖。

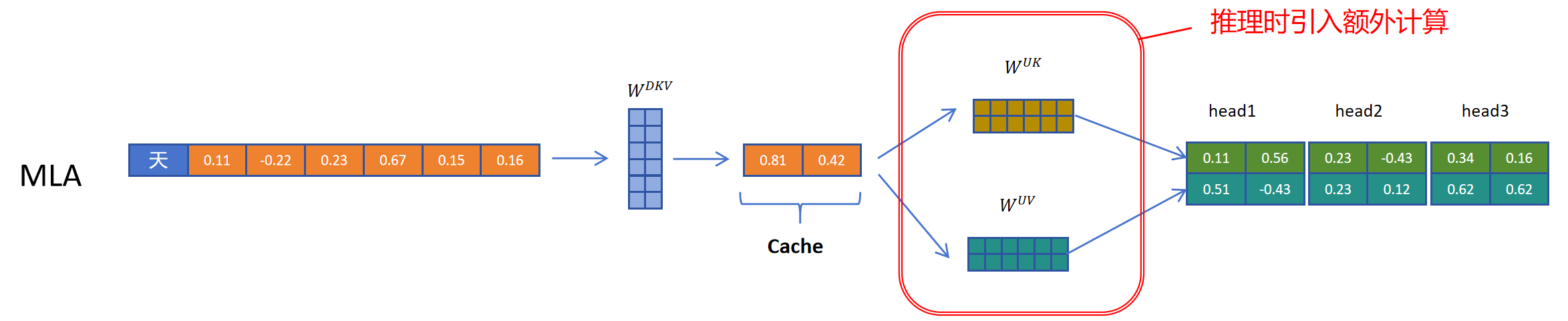
我们看一下带KV Cache的推理过程,如上图,对于标准的MHA,对于当前的token,计算Q,K,V,然后存储KV,对于之前的token,直接从缓存取出K和V向量就可以,然后进行attention的计算。

对于MLA,当前token的计算,Q的计算不变。但在K和V的计算时,先通过参数矩阵进行压缩,然后生成压缩的KV的隐特征。并将存储KV Cache。K,V向量通过将KV压缩隐特征与K向量的解压参数矩阵,V向量的解压参数矩阵进行相乘,得到当前token,可用于注意力集散的K和V向量。 对于之前的token,则从KV Cache里取出压缩的隐特征向量C^{KV},然后经过k,v向量的解压参数矩阵投影,得到可以计算的k,v向量。
所以进行注意力计算时,它的公式如上图右边所示,我们主要关注这里Q和K的转置进行的矩阵计算,代入, K 等于。然后将这个转置符号代入括号里的两个矩阵,交换顺序,得到表达式。可以发现,对K进行解压操作的矩阵可以和矩阵融合,这个融合矩阵可以提前计算好,这样在推理时就不用额外进行对K的解压计算了。
这样我们通过矩阵相乘的结合律,对矩阵提前进行融合,就可以规避MLA引入的推理时因为解压隐特征带来的额外计算了。刚才我们详细看了可以和进行融合,同样对V向量进行解压的也可以和注意力模块计算出来的注意力加权向量最后经过的那线性层权重进行融合。
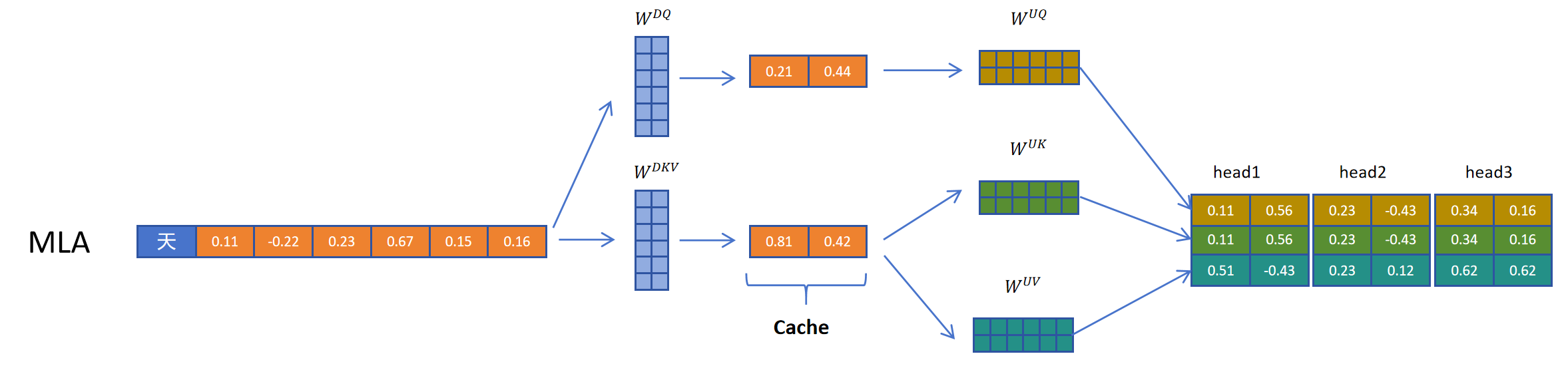
MLA除了对K和V进行压缩外,对Q向量也进行了压缩,这样的好处是降低了参数量,而且可以提高模型性能。可以看到这里通过WDQ对q向量进行压缩,通过WUQ对Q向量进行解压。但是Q的隐向量并不需要缓存,只需要缓存KV共用的KV压缩隐向量。
18.3.6 增加旋转位置编码
很好,现在似乎什么问题都解决了,KV Cache减小了,模型表现还得到提升。但是好事多磨,刚才我们一直没有讨论位置编码,确切的说是旋转位置编码。我们知道旋转位置编码需要对每一层的q向量和k向量进行旋转。而且根据token位置的不同,旋转矩阵的参数也不同。这里以第i个token的q向量和第j个token的k向量进行点积运算为例,图示如下:
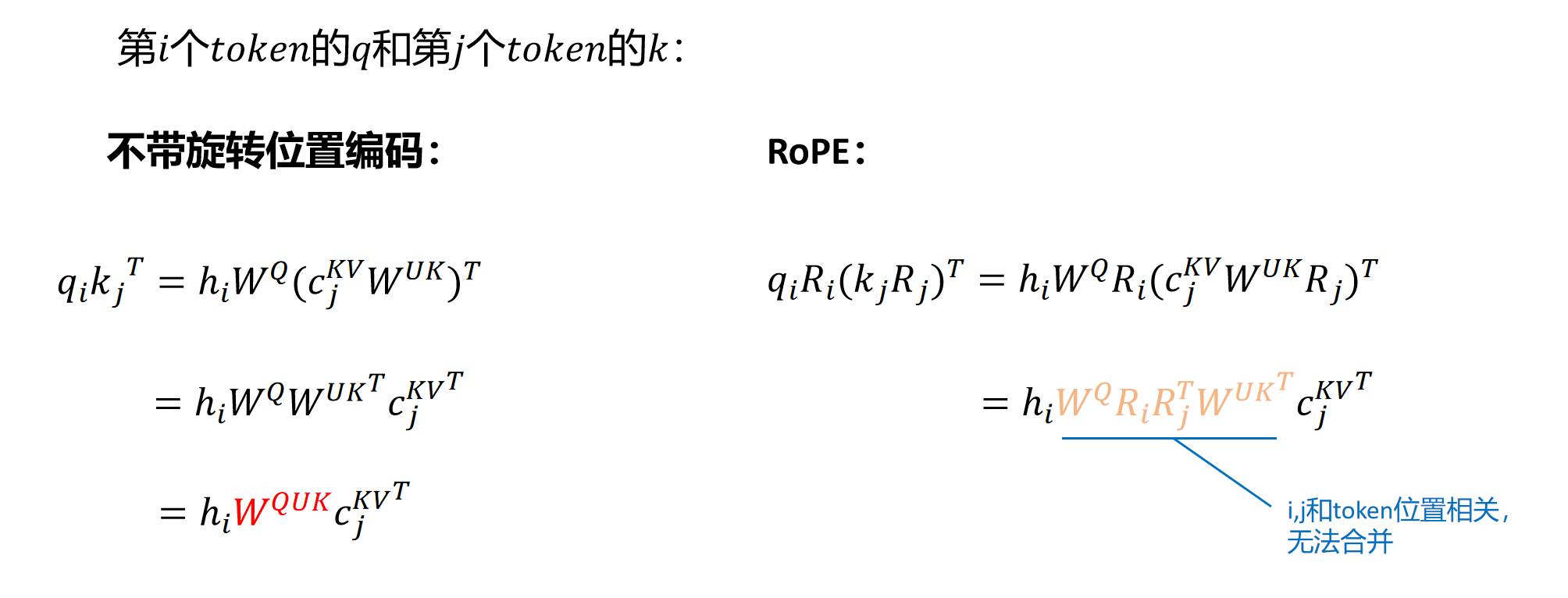 如果不考虑旋转位置编码,就是之前我们讲过的,对K进行解压的矩阵可以和矩阵融合。但是如果考虑旋转矩阵呢?因为不同位置旋转矩阵不同,这里我们用和代表第i和第j个token位置的旋转矩阵。可以发现如果增加了旋转矩阵,它就出现在了和之间,而且因为和和位置相关无法一起融合。所以它破坏了之前想到的推理时矩阵提前融合的方案。
如果不考虑旋转位置编码,就是之前我们讲过的,对K进行解压的矩阵可以和矩阵融合。但是如果考虑旋转矩阵呢?因为不同位置旋转矩阵不同,这里我们用和代表第i和第j个token位置的旋转矩阵。可以发现如果增加了旋转矩阵,它就出现在了和之间,而且因为和和位置相关无法一起融合。所以它破坏了之前想到的推理时矩阵提前融合的方案。
DeepSeek最终想到了一个方案,就是给Q和K向量额外增加一些维度来表示位置信息。
对于Q向量,它通过权重(这里上标Q代表Q向量,R代表旋转位置编码)为每个头生成一些原始特征。然后通过旋转位置编码增加位置信息,再把生成的带位置信息的特征拼接到每个注意力头的q向量。
对于K向量,通过矩阵生成一个头,共享的特征,然后通过旋转位置编码增加位置信息,然后复制到多个头,共享位置信息。这里多头共享的带位置编码的额外增加的k向量也需要被缓存,以便计算时拼接完整k向量时用到。
可以看到最终处理完后,q和k向量一样长,它们和v向量不一样长。这没有关系,q和k进行点积运算。最后生成对v向量的权重,对v向量进行加权求和即可。
最后,我们再来看一下原始论文里的MLA的示例图。
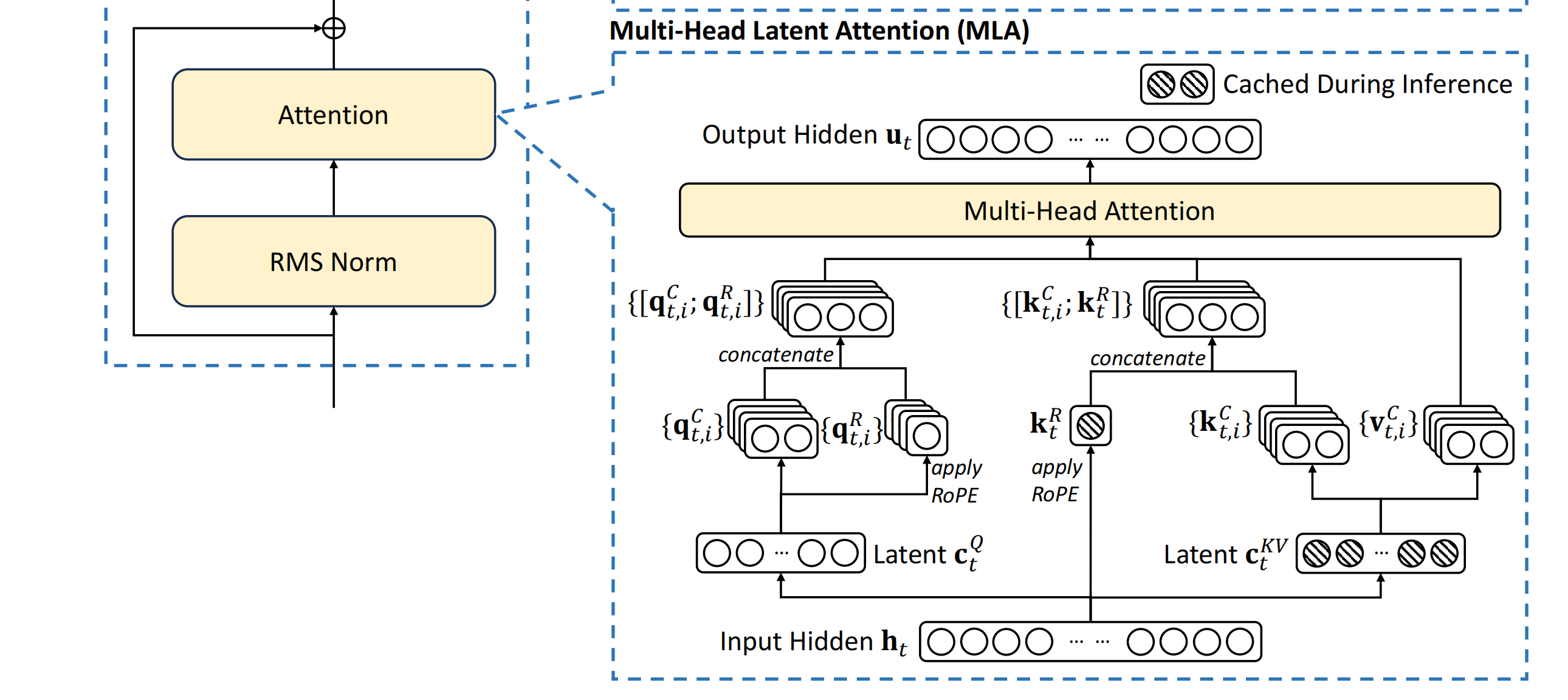
注意图中阴影部分为需要缓存的中间变量,其中需要缓存的只有KV共用的压缩隐特征,以及K的多头共享的带位置编码的额外向量。