12.3 词典生成
在进行NLP任务时,因为输入的是文本序列。文本是由多个词构成的,词是有意义的最小单元,所以在NLP任务中,一般处理的基本单元是词,或者叫做Token。也有以单个字(中文)或者单个字母(英语)作为最小处理单元的NLP模型,但是比较少见,我们这里不做讨论。
既然NLP任务以Token作为处理的最小单元,那么NLP模型需要支持多少Token呢?NLP模型支持的所有Token就构成一个词典。不同NLP模型的词典是不同的,比如ChatGPT的词典和DeepSeek是不同的。
那么NLP模型的词典是怎么产生的呢?
12.3.1 利用现成的词典
最简单的办法就是找一本词典,比如《汉语大辞典》或者《四六级单词表》,然后再加上一些常用的其他符号,构成模型可以处理的词典。 有了词典后,对于一句话,可以根据词典来进行分词,分词的一般原则为:最大匹配优先,也就是说尽量使用词典中长度最长、匹配优先级最高的词。例如,“自然语言处理”在词典中如果有“自然语言处理”这个词条,则整体作为一个Token;如果没有,则可能拆成“自然语言”和“处理”两个Token,或者进一步拆成更小的单元。
这种方法的优点是简单、易于理解、词典可控,缺点是词典覆盖率有限,对于新词、专有名词、拼写错误、口语表达等,容易出现无法分词或分词不合理的情况。因此,很多现代NLP模型通常不会完全依赖于人工编制的词典。
12.3.2 特殊的Token
在为NLP模型构建词典时,为了模型训练,会增加一些特殊的Token,它们并不是来自人类语言。
<UNK>:Unknow,代表所有未在词典中出现的Token。如果模型输入的句子中包含了不在词典里的Token,都会被映射到<UNK>这个特殊的Token。
<BOS>: BeginOfSequence,表示序列的开头。有的NLP模型在处理输入时,会在句子前加上这个Token,代表一句话的开始。
<EOS>: EndOfSequence, 表示序列的结束。NLP在进行输出时,如果模型输出了<EOS>这个Token,则代表模型输出结束了,我们就终止模型的输出。
<SEP>: Separation,有的NLP模型需要输入两个序列,为了区分两个序列,会在中间添加<SEP>这个特殊Token。
上边只是举了一些例子,NLP模型可以根据自己的需要设计一些特殊Token。比如带思考的大模型会在输出时用<think>...</think>这两个特殊Token代表它们之间的Token是模型思考的内容。
12.3.3 词典大小的设计
像早期的NLP模型一般词典大小为几万,它们可能只能处理一两种语言。到了大语言模型时代,模型的词典大小一般都是十几万。它们可以处理大部分的语言。
词典设计太小,在实际处理文本时,可能会出现大量的<UNK> Token。导致模型能力差。但是词典设计太大,又会增加模型参数量、计算开销和存储成本,造成训练和推理效率下降。
12.3.4 字节对编码
字节对编码(Byte Pair Encoding,BPE)是一个常用的,用于NLP模型词典的方法。进行BPE编码前,需要提前指定:
语料。也就是模型将来要处理的大量文本。
词典的大小。指定一个数字,词典包含多少个Token。
英文单词数量就有几十万个,而且还不断有新的词汇产生。把这些单词都加入词典就太多了。人类会根据词根来推断单词含义。比如认识了high这个单词,就知道higher、highest的含义。同样知道了low就知道了lower、lowest的含义。如果让模型也可以利用词根来认识单词,则可以减少词典大小。模型只要学习low、high、er、est这四个token的含义。根据词根来划分token可以获得更多针对每个token的训练样本,从而让训练后的模型拥有更好的泛化效果。
下边看一个对英文利用BPE编码构造词典的例子。我们收集了一批语料,并对其中的单词进行了统计。得到每个单词出现的次数。同时,我们规定了词典大小为15。
算法初始化时,首先给每个单词后边加上</w>表示这是一个单词结束的位置。然后按照字母对每个单词进行切分,将切分后的字母和</w>放入词典:
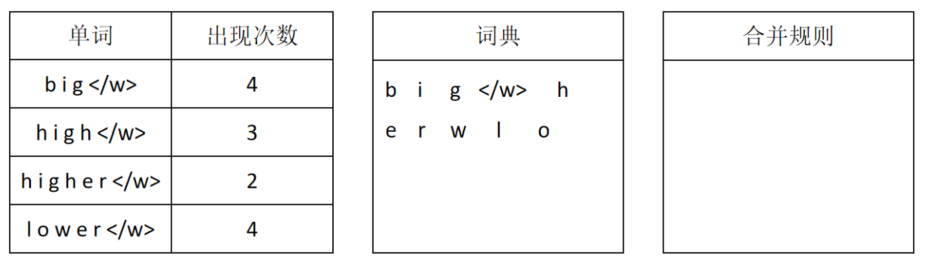
接下来对所有相邻token进行统计,找出出现最多的两个token组合,将它们合并为一个新的token,放入词典。同时记录合并规则。如果同时有多个token对出现次数一样且都是最大,则任选一对进行合并。这一步被合并的是i和g,它们一共出现了9次。同时,i与g的合并规则也被记录下来。
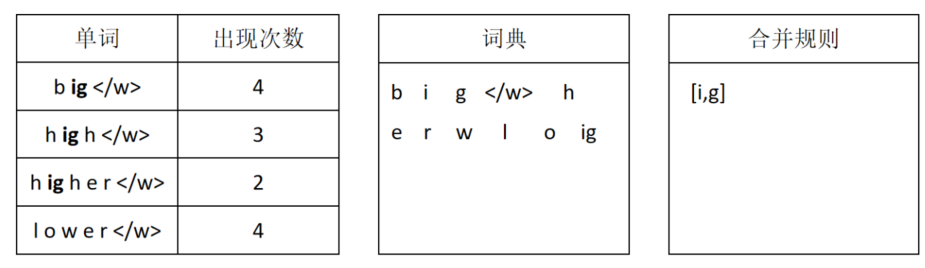
经过第一次合并后,ig被作为一个token,然后统计所有单词里相邻token出现最多的组合。e和r的组合出现了最多次,所以这次将e和r进行合并,并记录合并规则。
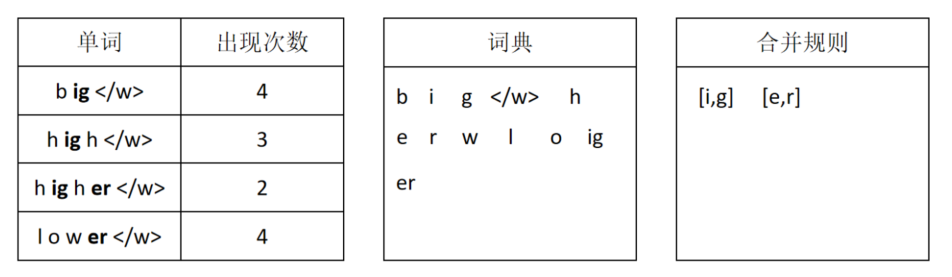
第三次合并将er和</w>进行合并。
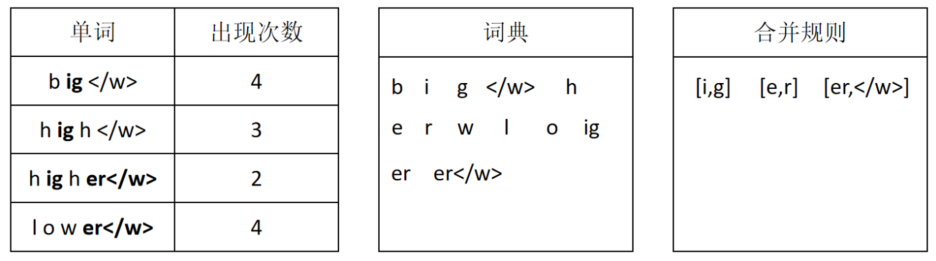
第四次合并将hi和g进行合并。
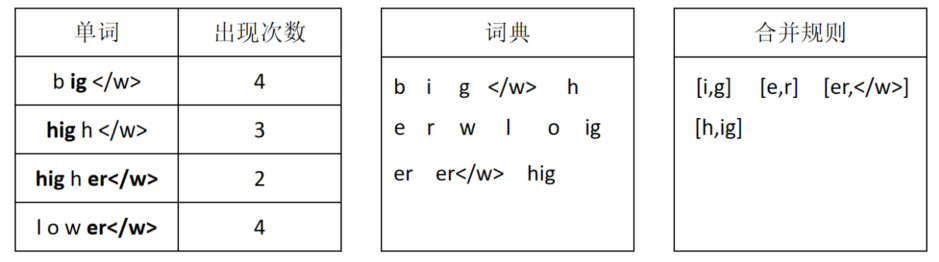
第五次合并将hig和h进行合并。经过五次合并后,词典内的token数量达到了预设的15个,所以停止合并。此时,算法产生了一个字典,同时有一组合并规则。

有了通过BPE算法生成的词典和合并规则,对于一句话的分词过程为先将单词按字符拆分,再应用合并规则进行token合并,最终返回token在字典里的序号。这就完成了对句子的分词。比如,如果输入higher lower,则分词完的结果为[14,12,8,9,7,12]。