14.3 模型定义
这一节我们来具体定义翻译模型的架构。具体代码在translator.py里。 网络结构示意图如下:
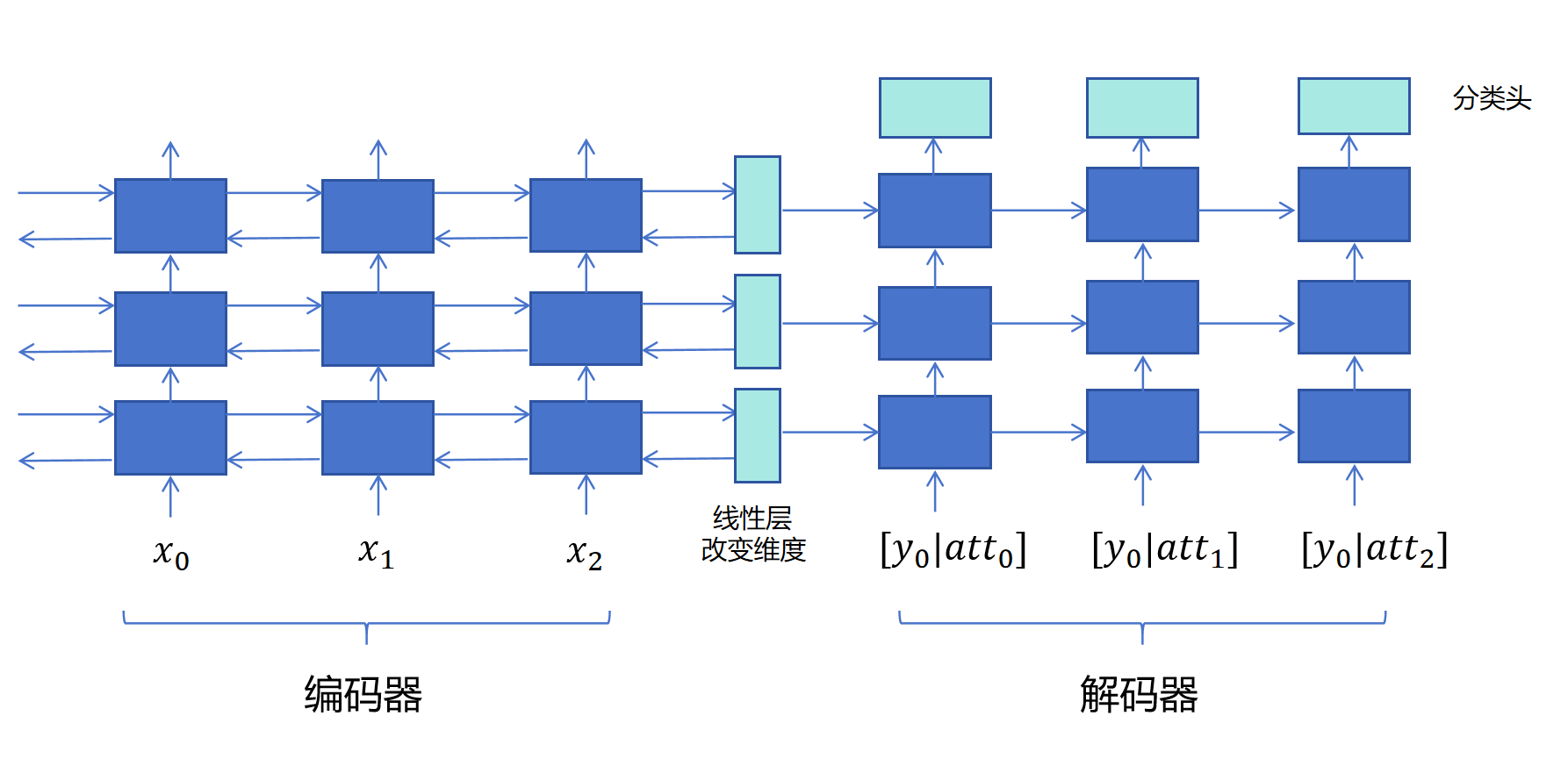
Encoder采用一个3层的双向LSTM,它输出每个英文token的最后一层隐状态。同时输出每层的双向隐状态和细胞状态。 Decoder采用一个3层的单向LSTM,它每层接收Encoder最后一个时间步的隐状态和细胞状态,因为Encoder状态为双向,此处需要每层一个的线性层转化维度。 Attention计算,Decoder每个token输入隐状态和Encoder所有英文token最后一层隐状态计算注意力,得到注意力上下文向量。 Decoder每个时间步将输入的中文token Embedding和当前时间步得到的注意力上下文向量拼接作为Decoder输入。
14.3.1 Encoder
class Encoder(nn.Module):
def __init__(self, vocab_size, emb_dim, hid_dim, n_layers=3):
super().__init__()
# 默认3个循环层
self.n_layers=n_layers
# 定义Embedding,可以将BPE分词输出的token id,转化为emd_dim的embedding向量。
self.embedding = nn.Embedding(vocab_size, emb_dim, padding_idx=PAD_ID)
# 定义双向LSTM模型
self.bi_lstm = nn.LSTM(emb_dim, hid_dim, n_layers, bidirectional=True)
# 定义线性层列表来降低维度。因为每个Encoder是双向的,隐状态和细胞状态为hid_dim*2,Decoder是单向的,隐状态和细胞状态维度为hid_dim。
self.fc_hidden = nn.ModuleList([nn.Linear(hid_dim * 2, hid_dim) for _ in range(n_layers)])
self.fc_cell = nn.ModuleList([nn.Linear(hid_dim * 2, hid_dim) for _ in range(n_layers)])
def forward(self, src, src_len):
embedded = self.embedding(src)
#将一个 padded sequence(已经填充到统一长度的 batch 序列) 转换为一个特殊的 PackedSequence 对象
#这个对象在传入 RNN 时能跳过 padding 部分的计算。
packed = nn.utils.rnn.pack_padded_sequence(embedded, src_len, enforce_sorted=False)
#outputs,形状为 (seq_len, batch_size, hid_dim*2),表示每个时间步、最后一层LSTM的双向隐状态拼接。
#(hidden, cell) ,形状都为(num_layers * 2, batch_size, hid_dim)表示每一层、每个方向在最后一个时间步的隐状态或细胞状态。
outputs, (hidden, cell) = self.bi_lstm(packed)
#将 PackedSequence 类型的输出还原成带 padding 的标准 Tensor,方便后续处理。
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs) # [src_len, batch, hid_dim*2]
# 重塑隐藏状态和细胞状态: [n_layers * 2, batch, hid_dim] -> [n_layers, 2, batch, hid_dim]
hidden = hidden.view(self.n_layers, 2, -1, hidden.size(2))
cell = cell.view(self.n_layers, 2, -1, cell.size(2))
# 为每一层处理前向和后向状态
final_hidden = []
final_cell = []
for layer in range(self.n_layers):
# 对每一层将正向和反向的隐状态,细胞状态合并,通过一个线性层将维度从hid_dim*2降低为hid_dim维度。
h_cat = torch.cat((hidden[layer][-2], hidden[layer][-1]), dim=1)
c_cat = torch.cat((cell[layer][-2], cell[layer][-1]), dim=1)
h_layer = torch.tanh(self.fc_hidden[layer](h_cat)).unsqueeze(0)
c_layer = torch.tanh(self.fc_cell[layer](c_cat)).unsqueeze(0)
final_hidden.append(h_layer)
final_cell.append(c_layer)
# 调整好维度为hid_dim的隐状态和细胞状态,可以传递给Decoder。
hidden_concat = torch.cat(final_hidden, dim=0)
cell_concat = torch.cat(final_cell, dim=0)
return outputs, hidden_concat, cell_concatEncoder 设计如下:
- 定义Embedding模块。BPE分词后会给每个token分配一个ID。Embedding模块给每个ID分配一个可学习的Embedding向量,在训练时可更新。
- 定义一个3层的双向LSTM。它的隐状态和细胞状态因为是双向的,所以维度都为hid_dim*2。
- 双向LSTM输出有三个变量:outputs,形状为 (seq_len, batch_size, hid_dim*2),表示每个时间步、最后一层LSTM的双向隐状态拼接。(hidden, cell) ,形状都为(num_layers * 2, batch_size, hid_dim)表示每一层、每个方向在最后一个时间步的隐状态或细胞状态。
- 进行英译中时,因为英文句子是完整输入的,Encoder可以看到完整的英文输入,所以可以定义为双向的,但是Decoder输出中文翻译时,只能单向逐个生成,所以是单向的。因此Decoder的隐状态和细胞状态维度为hid_dim。
- Encoder需要将自己最后一个时间步的隐状态和细胞状态传递给Decoder的第一个时间步,但是它们的隐状态和细胞状态向量的维度不同,所以,每个循环层都需要一个线性层来进行转化。每个线性层的输入维度为hid_dim*2,输出维度为hid_dim。
上边的代码进行了良好的注释,你可以逐行阅读和调试。
14.3.2 Attention
class Attention(nn.Module):
def __init__(self, hid_dim):
super().__init__()
#第一层输入维度为Encoder的输出隐状态(因为是双向的,所以维度为hid_dim*2,)和Decoder的输入隐状态(单向,维度为hid_dim)的拼接。
self.attn = nn.Linear(hid_dim * 2 + hid_dim, hid_dim)
#输出一个代表注意力的logit值。
self.v = nn.Linear(hid_dim, 1, bias=False)
def forward(self, hidden, encoder_outputs, mask):
# 调整Decoder当前时间步输入隐状态的维度: [1, batch, hid_dim] -> [batch, 1, hid_dim]
hidden = hidden.permute(1, 0, 2)
# 调整Encoder各个时间步输出隐状态的维度: [src_len, batch, hid_dim*2] -> [batch, src_len, hid_dim*2]
encoder_outputs = encoder_outputs.permute(1, 0, 2)
src_len = encoder_outputs.shape[1]
# 中文当前一个token需要和英文所有token计算注意力。所以需要把中文token的状态复制多份,以便进行统一拼接。
# 因为Decoder只有当前时间步输入的隐状态,复制到和Encoder输出隐状态同样的src_len。
hidden = hidden.repeat(1, src_len, 1) # [batch, src_len, hid_dim]
# 拼接Decoder当前输入的隐状态和Encoder在各个时间步输出的隐状态,然后经过一个线性层,tanh激活。
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2))) # [batch, src_len, hid_dim]
# 输出Decoder当前中文token与所有英文token的注意力值。
attention = self.v(energy).squeeze(2) # [batch, src_len]
# mask标志哪些位置为<pad>,对于填充的位置,注意力值为一个大的负值。这样经过softmax就为0。
attention = attention.masked_fill(mask == 0, -1e10)
# 利用softmax将注意力的值归一化。让生成当前中文token对输入的英文各个token的注意力之和为1。
return torch.softmax(attention, dim=1) # [batch, src_len]Attention类的实现通过一个两层的神经网络来计算Decoder生成每个中文token对输入英文的每个token的注意力的值。并且这个中文token对输入所有英文token的注意力的值加和为1。因为输入时,我们在有的序列后边增加了
计算Attention的两层神经网络会分别计算当前Decoder要生成的中文token对Encoder每个英文token的注意力。这个网络的输入就为Encoder每个token的输出隐状态(因为是双向的,所以维度为hid_dim*2,)和Decoder的输入隐状态(单向,维度为hid_dim)的拼接。输出为一个代表注意力的值。
上边的代码进行了很好的注释,你可以逐行理解并调试。
14.3.3 Decoder
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, attention, n_layers=3):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim, padding_idx=PAD_ID)
# 单向LSTM,输入维度为注意力加权后的,Encoder输出隐状态维度(hid_dim*2)加上输入token的embedding的维度emb_dim。
self.lstm = nn.LSTM(hid_dim * 2 + emb_dim, hid_dim,num_layers=n_layers)
# 最终分类头,输入为hid_dim,输出为字典大小
self.fc_out = nn.Linear(hid_dim, output_dim)
def forward(self, input_token, hidden, cell, encoder_outputs, mask):
# input_token: [batch]
# 输入单个字符,增加一个维度
input_token = input_token.unsqueeze(0) # [1, batch]
# 获取token的embedding
embedded = self.embedding(input_token) # [1, batch, emb_dim]
# 获取当前步的输入隐状态
last_hidden = hidden[-1].unsqueeze(0)
# 当前步对所有encoder输出的注意力
a = self.attention(last_hidden, encoder_outputs, mask) # [batch, src_len]
a = a.unsqueeze(1) # [batch, 1, src_len]
encoder_outputs = encoder_outputs.permute(1, 0, 2) # [batch, src_len, enc_hid_dim*2]
# 用矩阵乘法获取注意力上下文向量
weighted = torch.bmm(a, encoder_outputs) # [batch, 1, enc_hid_dim*2]
weighted = weighted.permute(1, 0, 2) # [1, batch, enc_hid_dim*2]
# 拼接输入token编码向量和注意力上下文向量
lstm_input = torch.cat((embedded, weighted), dim=2) # [1, batch, emb_dim + enc_hid_dim*2]
# 一次只执行lstm的一个时间步。
output, (hidden, cell) = self.lstm(lstm_input, (hidden, cell)) # output: [1, batch, hid_dim]
# 移除第0维(第一个维度)
output = output.squeeze(0) # [batch, hid_dim]
# 计算分类logtis
prediction = self.fc_out(output) # [batch, output_dim]
return prediction, hidden, cell, a.squeeze(1) # attention weights for visualizationDecoder的设计如下:
- 定义了中文token的embedding。
- 单向3层的LSTM作为Decoder,输入为注意力上下文向量拼接当前时刻输入token的embedding。
- 一个线性层作为分类头,输入为每个时间步的隐状态,输出为字典维度的向量,经过softmax后为字典每个token作为当前中文token输入的概率。
- Decoder的调用是逐步调用的,每次调用都输入前一个时刻的隐状态,细胞状态。以及注意力上下文向量和当前token的embedding的拼接向量。生成输出隐状态,细胞状态。然后用输出隐状态对字典里每个token进行分类。
- 这里我们实现的分类头输入只有当前时间步LSTM输出的隐状态,实际项目中有时也会把注意力上下文向量拼接上,一起作为最后分类头的输入,这样会提升模型性能。
14.3.4 Seq2Seq
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, src_len, trg):
batch_size = trg.shape[1]
max_len = trg.shape[0]
vocab_size = self.decoder.output_dim
outputs = torch.zeros(max_len, batch_size, vocab_size).to(self.device)
# 调用encoder
encoder_outputs, hidden, cell = self.encoder(src, src_len)
input_token = trg[0]
mask = (src != PAD_ID).permute(1, 0)
# 逐步调用Decoder
for t in range(1, max_len):
output, hidden, cell, _ = self.decoder(input_token, hidden, cell, encoder_outputs, mask)
outputs[t] = output
input_token = trg[t]
return outputsSeq2Seq将Encoder和Decoder组装在一起,输入为英文token id序列,一次性调用encoder,输出output、hidden、cell向量,然后逐步调用Decoder。需要注意的是每一步我们都是以Label数据token作为输入,而不是以Decoder上一步生成的token作为输入。
14.3.5 train方法
def train(model, iterator, optimizer, criterion):
model.train()
epoch_loss = 0
step_loss = 0 # 用于累计每个step的loss
step_count = 0 # 当前step计数器
for i, (src, trg, src_len, _) in enumerate(iterator):
src, trg = src.to(model.device), trg.to(model.device)
optimizer.zero_grad()
output = model(src, src_len, trg)
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
loss = criterion(output, trg)
loss.backward()
optimizer.step()
# 更新损失统计
step_loss += loss.item()
epoch_loss += loss.item()
step_count += 1
# 每100个step打印一次
if (i + 1) % 100 == 0:
avg_step_loss = step_loss / step_count
print(f'Step [{i + 1}/{len(iterator)}] | Loss: {avg_step_loss:.4f}')
step_loss = 0 # 重置step损失
step_count = 0 # 重置step计数器
return epoch_loss / len(iterator) # 返回整个epoch的平均loss上边代码是对Seq2Seq模型进行训练的方法,相信你应该可以看懂,我们不做解释。
14.3.6 main方法
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
dataset = TranslationDataset('data\\en2cn\\valid_en.txt', 'data\\en2cn\\valid_zh.txt', tokenize_en, tokenize_cn)
loader = DataLoader(dataset, batch_size=48, shuffle=True, collate_fn=TranslationDataset.collate_fn)
INPUT_DIM = sp_en.get_piece_size()
OUTPUT_DIM = sp_cn.get_piece_size()
ENC_EMB_DIM = 512
DEC_EMB_DIM = 512
HID_DIM = 1024
attention = Attention(HID_DIM).to(device)
encoder = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM).to(device)
decoder = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, attention).to(device)
model = Seq2Seq(encoder, decoder, device).to(device)
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index=PAD_ID)
N_EPOCHS = 1
for epoch in range(N_EPOCHS):
loss = train(model, loader, optimizer, criterion)
print(f'Epoch {epoch + 1}/{N_EPOCHS} | Loss: {loss:.4f}')
torch.save(model.state_dict(), f'seq2seq_bpe_attention_epoch{epoch + 1}.pt')上边代码是训练模型的入口,创建了模型,定义了优化器和loss函数,指定迭代次数,每个迭代保存一个模型。这里为了实验,可以设置为1个迭代。我在3090,24GB显存的机器上,训练一个迭代大概需要24小时。你根据你的情况可以调整batch_size和N_EPOCHS的设置。