13.3 GRU
上一节我们讲了LSTM,它确实有些复杂,门控循环单元(Gated Recurrent Unit,GRU)是对LSTM的简化版,实验表明,GRU的性能基本和LSTM相当。
13.3.1 GRU的网络结构
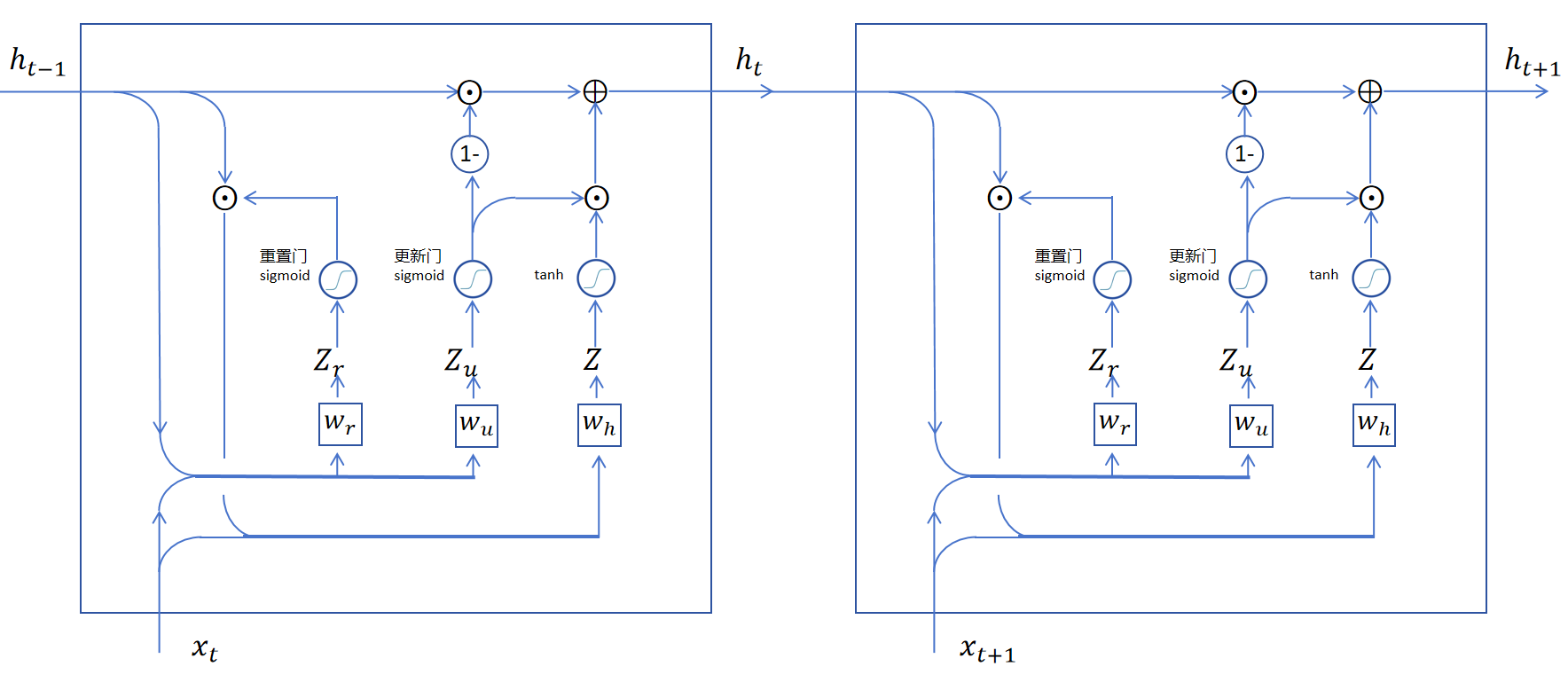
GRU去掉了LSTM中的记忆细胞状态,仅用隐状态就解决了长期记忆和梯度消失的问题。我们来一步步看一下GRU循环层的设计逻辑。
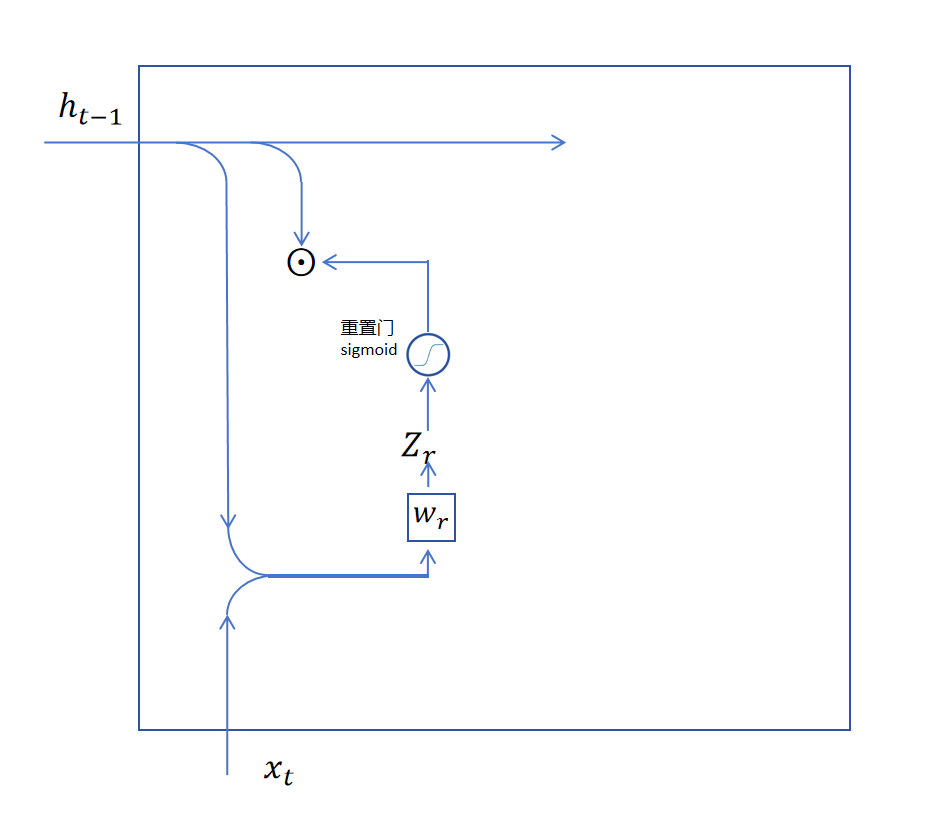
首先我们看如何从隐状态中读取信息,GRU里也通过一个遗忘门来决定从长期记忆里去掉一些信息。不过GRU里叫做重置门,。重置门也是用simgoid函数,它的输入是上一时刻的记忆和当前时刻的输入进行拼接,然后经过一个线性层得到的。线性层的权重为。
于是就是经过重置后的长期记忆。
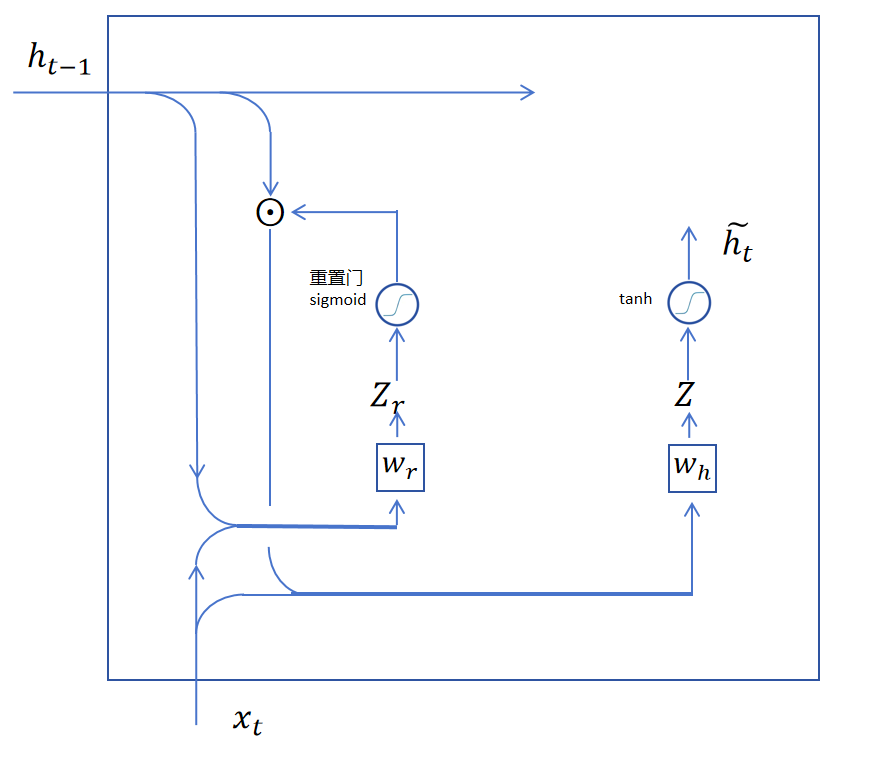
重置后的长期记忆和当前输入合并,然后经过一个线性层(权重为),加tanh激活,就得到当前层的备用输出。
此时,备用输出还是不能直接输出,因为GRU就只能靠隐状态来传递长期记忆,这里需要将需要长期保留的记忆加进来再作为当前时间步的隐状态作为输出。怎么决定哪些维度保留长期记忆,哪些维度更新为备用输出的隐状态呢?答案还是用一个门函数来控制。不过这个门函数同时决定保留多少长期记忆,更新多少当前步产生的记忆。
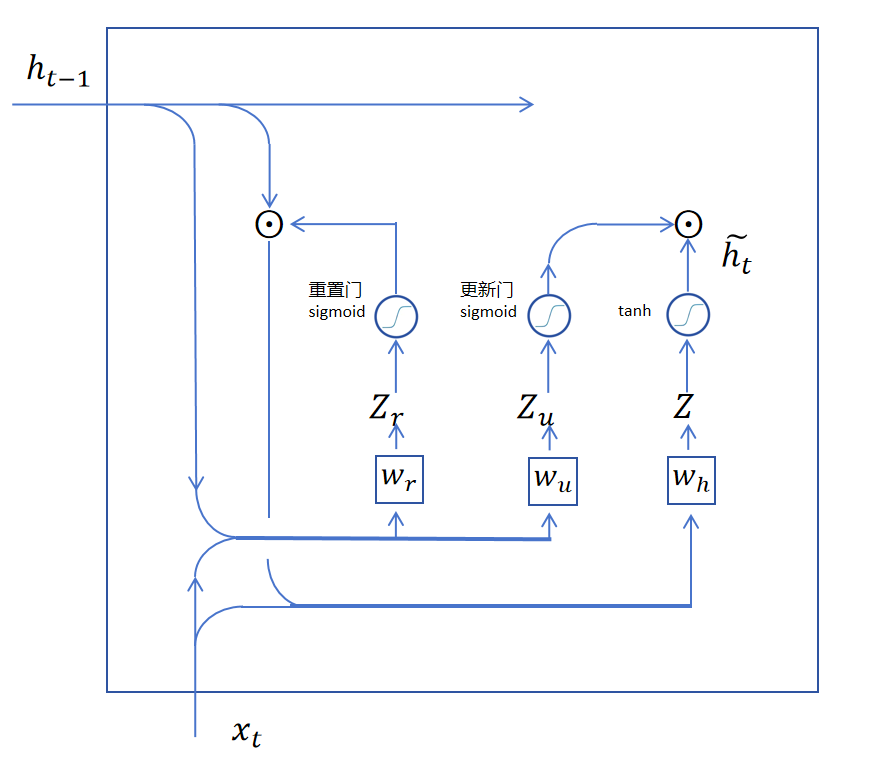
首先用一个sigmoid更新门,生成一个更新向量,它和备用输出按位相乘,获得要更新到长期记忆里的信息。然后用1减去更新向量里的每一维,这样就得到了对长期记忆的保留向量。用保留向量与长期记忆按位点乘,就得到了保留的长期记忆,在和更新信息相加,就得到了这一步输出的长期记忆,。
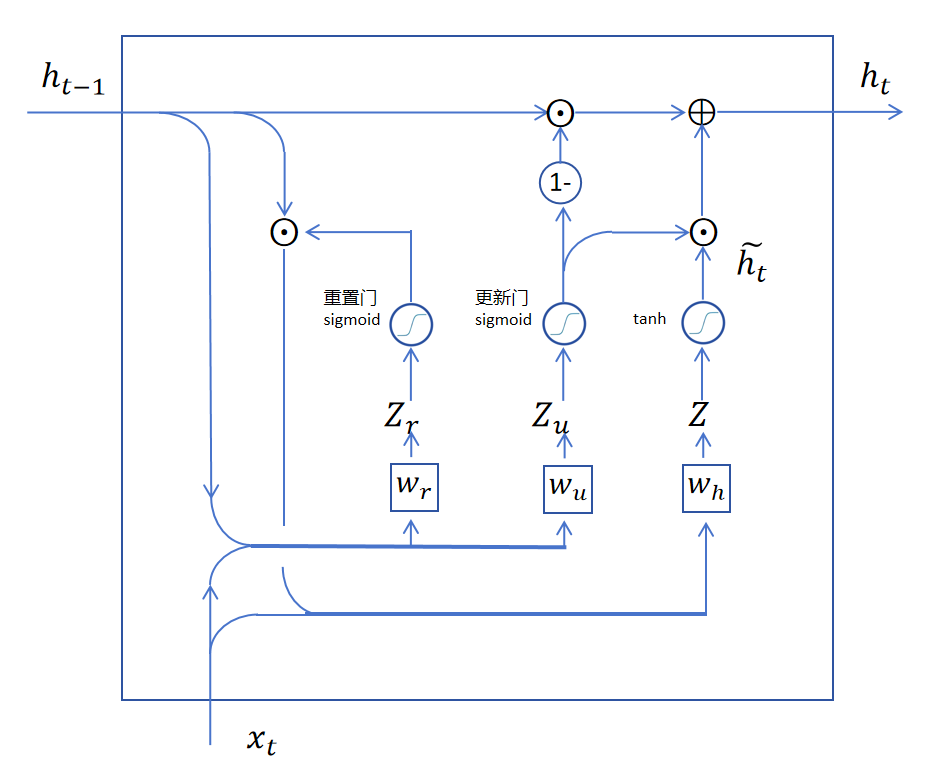 我们将两个GRU相连,可以发现它也和LSTM类似,实现了隐状态的相连,可以长期保留记忆,也可以让梯度更容易传递到前边的时间步。
我们将两个GRU相连,可以发现它也和LSTM类似,实现了隐状态的相连,可以长期保留记忆,也可以让梯度更容易传递到前边的时间步。
13.3.2 用GRU和LSTM
LSTM一般更常用,效果更好,用的人更多。但是LSTM因为更复杂,参数更多训练成本会更高一些。如果你更在意训练成本可以用GRU。