13.1 RNN
循环神经网络(Recurrent Neural Network,RNN)是在Transformer架构出现之前,处理序列数据效果最好的网络结构。
序列问题,简单来说,就是处理数据之间存在顺序关系的问题,数据的顺序改变则代表含义改变。更正式一点的定义是:
序列问题是指输入、输出或两者都是有序的数据序列,元素之间存在时间上或位置上的依赖关系,模型在处理当前元素时需要考虑前面(或未来)元素的信息。
序列问题的特点是:
数据是按顺序排列的(顺序有意义)。
数据之间存在依赖关系(后面的值依赖前面的值)。
不能简单打乱顺序处理
典型的序列问题有:
自然语言处理(NLP)
时间序列预测(股价、天气)
语音识别
视频分析
机器人控制
13.1.1 序列到序列问题
我们以之前讲过的NLP相关问题为例,可以发现,序列到序列问题有以下几种输入和输入情况:
多对一
比如输入为一条评论文本,输出是一个二分类,判断是正面还是负面。输入是多个向量,输出是一个向量。
多对多
多对多任务分为两种,一种是输入token序列长度和输出token序列长度完全一样。比如命名实体识别(NER)任务。还有一种是输入token序列和输出token序列长度不一样的情况,比如对输入文本生成摘要,或者翻译任务。输入和输出都是多个向量
另外对于输入或输出的多个向量而言,他们的个数也是不固定的,我们不能像之前设计全连接神经网络那样,固定输入的神经元个数。
13.1.2 RNN网络结构
我们还是以之前举的NER任务为例,目标是识别输入句子里的人名。我们分别看两个输入:
“我的鞋是李宁的。”
“我叫李宁。”
一个好的NER模型应该能根据上下文识别出第一句里的“李宁”是品牌名,第二句的“李宁”是人名。
为了让RNN能够处理变长的输入,它被设计成循环调用的方式,每次只输入序列里的一个元素。对应到NLP任务里,每个元素就是一个token的embedding。
以第二个句子“我叫李宁”为例,目标是识别人名,所以对于每个token的输出是一个三分类(B-N:名字的开头,I-N:名字的后续,O:其他)。NER的输入Token序列长度和输出序列长度一样。

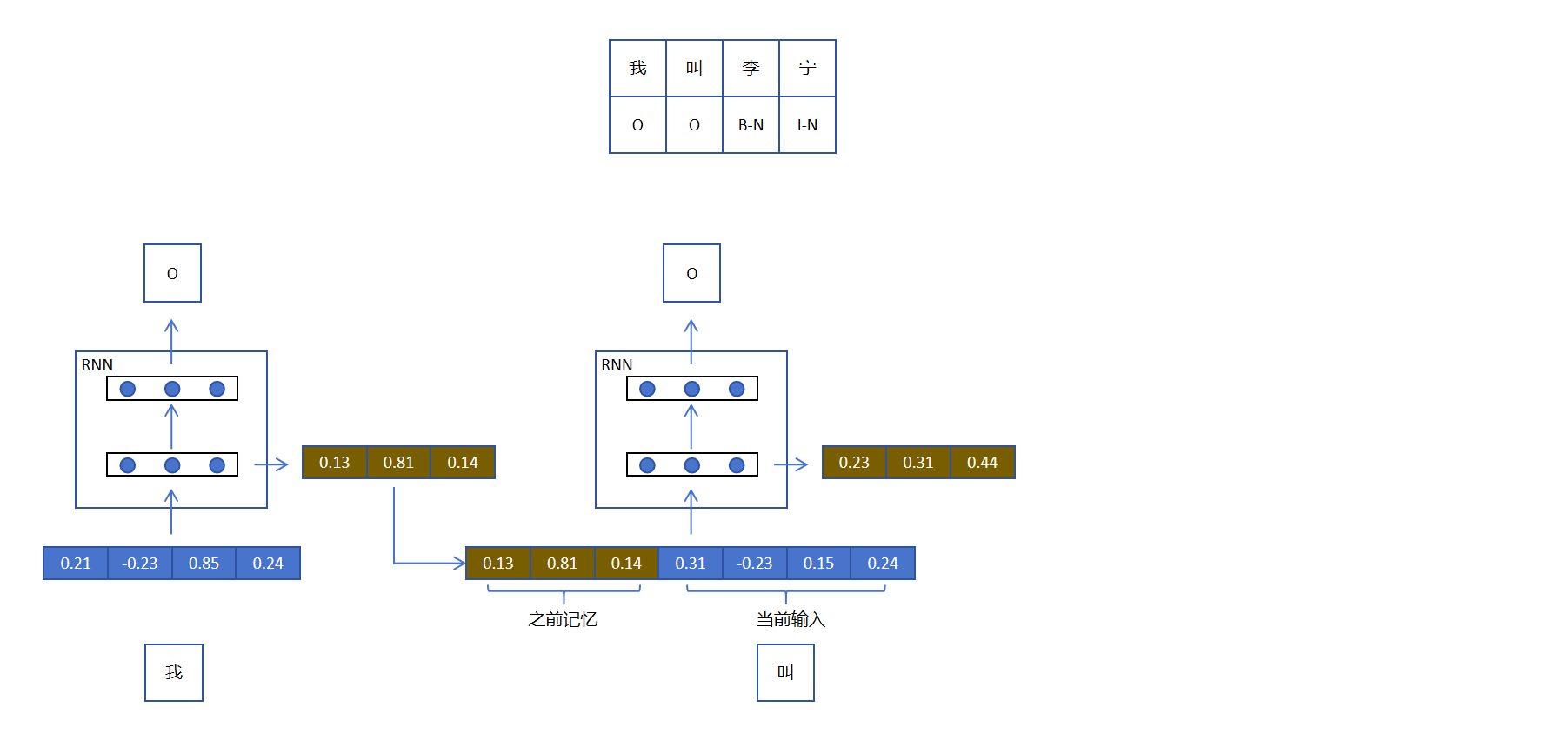
RNN对于第一个token,输入是它的embedding,经过两层,一个隐藏层(3个神经元)。一个是输出层,输出层有3个神经元,对用NER的三分类。这看起来和普通的神经网络没有区别。
RNN需要能为序列保留记忆,这样后边的token才可能判断自己是人名还是公司名。怎么保存记忆呢?RNN把隐藏层的输出作为记忆保存,如下图:

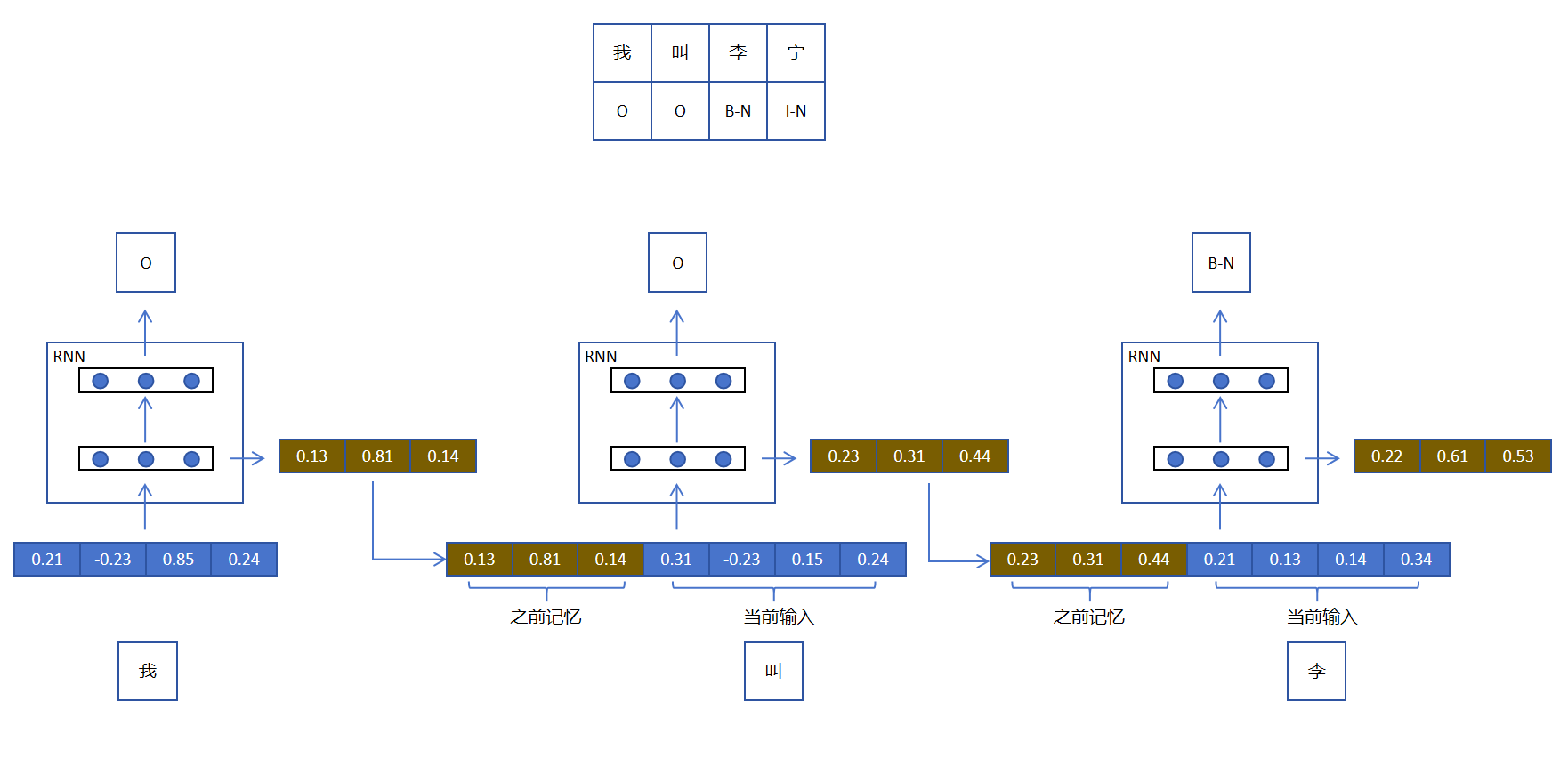
接下来我们看RNN如何处理第二个token,它将当前RNN的记忆与第二个token的embedding进行拼接作为输入,这样第二个token就有了上下文信息了。同时RNN在处理第二个token时会更新RNN网络的记忆,以便后用。特别需要注意的是:第一步和第二步RNN的参数是共享的,如下图所示:
第三步和第二步一样,拼接RNN的记忆和当前token的embedding,传入RNN,并用隐藏层的输出更新RNN的记忆。
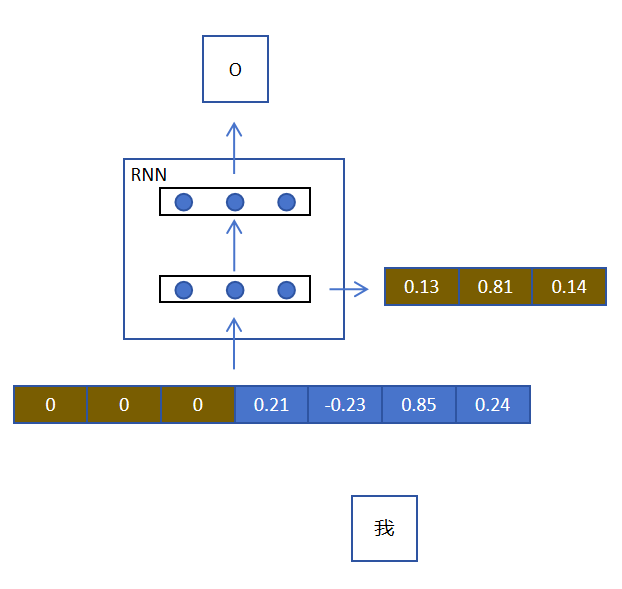
细心的你可能发现处理第一个token时,没有记忆怎么办?答案是即使是第一步,我们会用同维度的全零记忆向量表示当前RNN没有记忆。这样就保证了所有步网络结构和处理逻辑的统一。
下边我们用公式详细定义一下RNN的计算:
我们用表示第个时刻的输入。
我们用表示第个时刻的输出。
我们用表示第个时刻更新后记忆,人们更常把它叫做隐状态。
我们用表示隐藏层的权重。
我们用表示输出层的权重。
当前时刻的隐状态等于前一时刻的隐状态和当前时刻的序列输入,经过隐藏层线性变化和激活函数后的输出。
这里一般更常用tanh作为激活函数,也可以用ReLU。之前我们介绍过ReLU可以更好的缓解梯度消失,RNN用tanh做激活,是因为它有其他方法来应对梯度消失。我们后边会讲。
输出层是一个多分类,激活函数用softmax:
注意:你看其他教程里可能会把分拆为和。然后用这两个权重分别和进行线性变化,然后再把结果相加。。这个运算实际上和我上边讲的是完全等价的,而且我讲的应该更好理解一些。
13.1.3 循环层和普通层
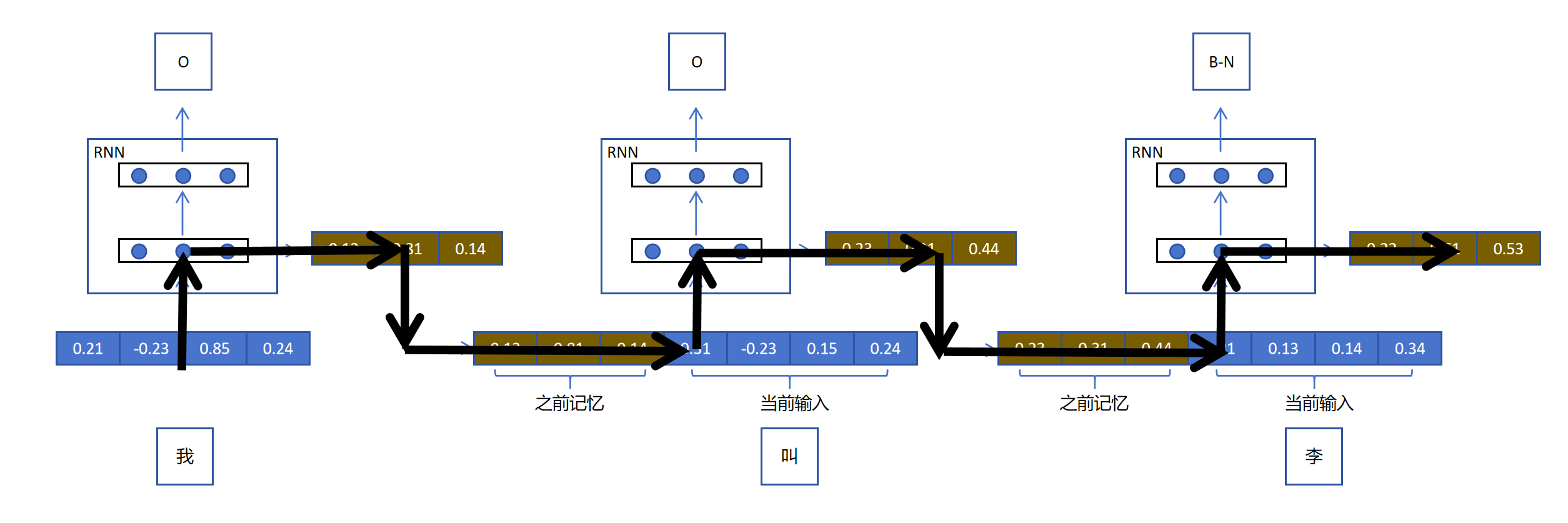
通过上图,我们观察RNN中的计算图,发现RNN中的循环实际上只发生在第一层,它是RNN的关键,是循环实际发生的地方,所以我们可以叫它循环层。每一个时间步对循环层的梯度更新会通过计算图递归调用到前边所有时间步的循环层。循环层的网络参数会被更新多次。
上图中的第二层是普通层,它不参与循环。每一个时间步对普通层的梯度更新,只会发生在当前步,普通层的网络参数只会被更新一次。这和普通神经网络没有区别。
所以说,循环层的递归调用才是RNN的本质。每一时间步通过对之前所有时间步的循环层的调用,输出关键的隐状态。对于普通层,可以看成是每一时间步利用向量作为输入,进行的额外的分类或者回归任务。普通层不是RNN的核心,它只是为了完成每一步的特定任务添加的任务层。
RNN重要的是循环层,以及循环层在每个时刻输出的隐状态,普通层利用隐状态完成每个时间步的任务。
13.1.4 RNN的优势
通过上边对RNN结构的讲解,不难发现RNN的优势:
通过隐状态机制,赋予模型记忆能力,能利用历史信息进行当前决策。
参数共享机制极大地提高了模型的效率和泛化能力。
能够应对任意长度的序列输入。