16.1 GPT-1
2018 年,OpenAI 发布了 GPT-1,正式拉开了大语言模型发展的序幕。随着模型参数规模和训练数据量的持续扩张,这一系列模型展现出了卓越的语言理解与生成能力。特别是 GPT-3,其拥有 1750 亿参数,被广泛认为是第一个真正意义上的“大语言模型”;而 GPT-4 更进一步,不仅显著提升了性能,还支持多模态输入(图像+文本),为人工智能的发展带来了更多可能性。
16.1.1 研究背景与动机
GPT-1 的论文《Improving Language Understanding by Generative Pre-Training》(通过生成式预训练改进自然语言理解)旨在解决当时自然语言处理(NLP)领域面临的两大核心挑战:
- 多数 NLP 任务严重依赖大量人工标注数据;
- 面向特定任务设计的模型缺乏通用性,难以迁移到其他任务。
受计算机视觉中“ImageNet 预训练 + 微调”成功模式的启发,OpenAI 提出了一种新方案,希望通过通用的预训练机制提高模型的泛化能力,并便于迁移到多种下游任务中。
面临的主要问题包括:
- 数据问题: NLP 领域缺乏类似 ImageNet 的大规模标注数据集,原始文本虽多,但缺少标注;
- 架构问题: 需要一种能在多种任务中泛化良好的模型架构,理想状态是只需加一个简单的线性分类器即可适配不同任务。
OpenAI 的解决思路如下:
- 利用自回归语言模型进行无监督预训练,训练目标是预测下一个词,这样就能直接使用海量原始文本;
- 采用 Transformer 架构,在捕捉序列模式和迁移能力方面优于以往模型,因此选定其作为基础结构。
16.1.2 模型架构
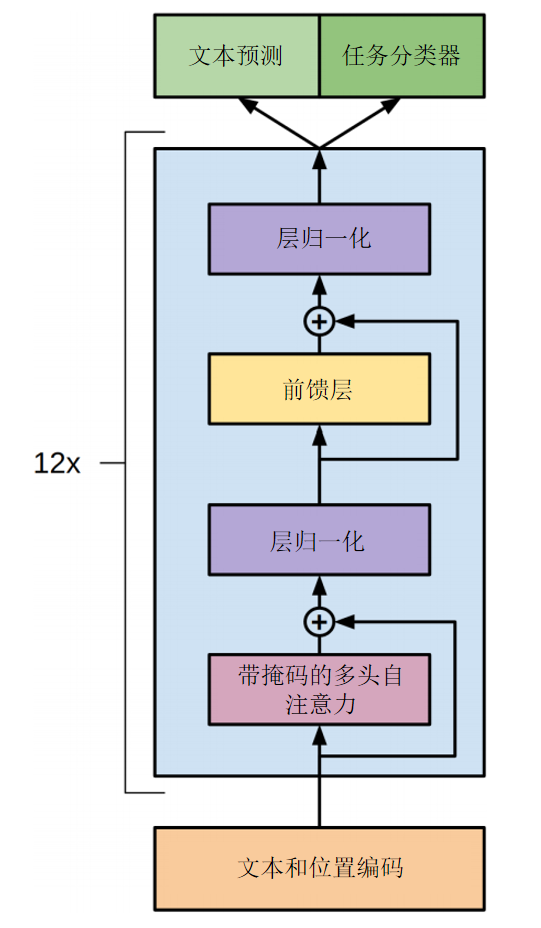
GPT-1 采用的是 Transformer 的 Decoder-only 架构,也就是说它省略了原始 Transformer 的编码器部分,进而也移除了与编码器相关的交叉注意力机制。
文本的处理流程如下:
- 分词与嵌入: 文本首先通过分词器切分成 token,再经过嵌入层转换为词向量,并添加可学习的位置编码,以引入位置信息。
- 掩码多头自注意力: 使用带掩码的多头注意力机制,确保模型在预测每个 token 时只能参考其前文,保持自回归性质。
- 残差连接与归一化: 每个模块使用残差连接与层归一化,随后通过前馈神经网络处理,再次进行残差与归一化。
- 堆叠结构: GPT-1 包含 12 层这样的解码器模块。
模型参数细节如下:
- 解码器层数:12
- 隐藏层维度:768
- 注意力头数:12
- 总参数量:1.17 亿
- 激活函数:GELU(Gaussian Error Linear Unit)
- 位置嵌入:采用可学习参数(非正弦函数)
- 词嵌入与输出层权重共享
GPT-1 将词嵌入矩阵(形状为
[vocab_size, hidden_size])与输出线性层的权重(形状为[hidden_size, vocab_size])共享,从而减少了参数量。这种策略在小模型中尤为重要,因为嵌入矩阵在总参数中占比很大。
16.1.3 下游任务适配方式
预训练完成后,OpenAI 采用极简的方式对 GPT-1 进行微调来适配不同下游任务,只需在文本中加入特殊 token。把组合好的序列输入预训练好的GPT-1。并拿出最后一个Token对应的输出向量, 然后接上一个简单的线性层来完成不同的任务。
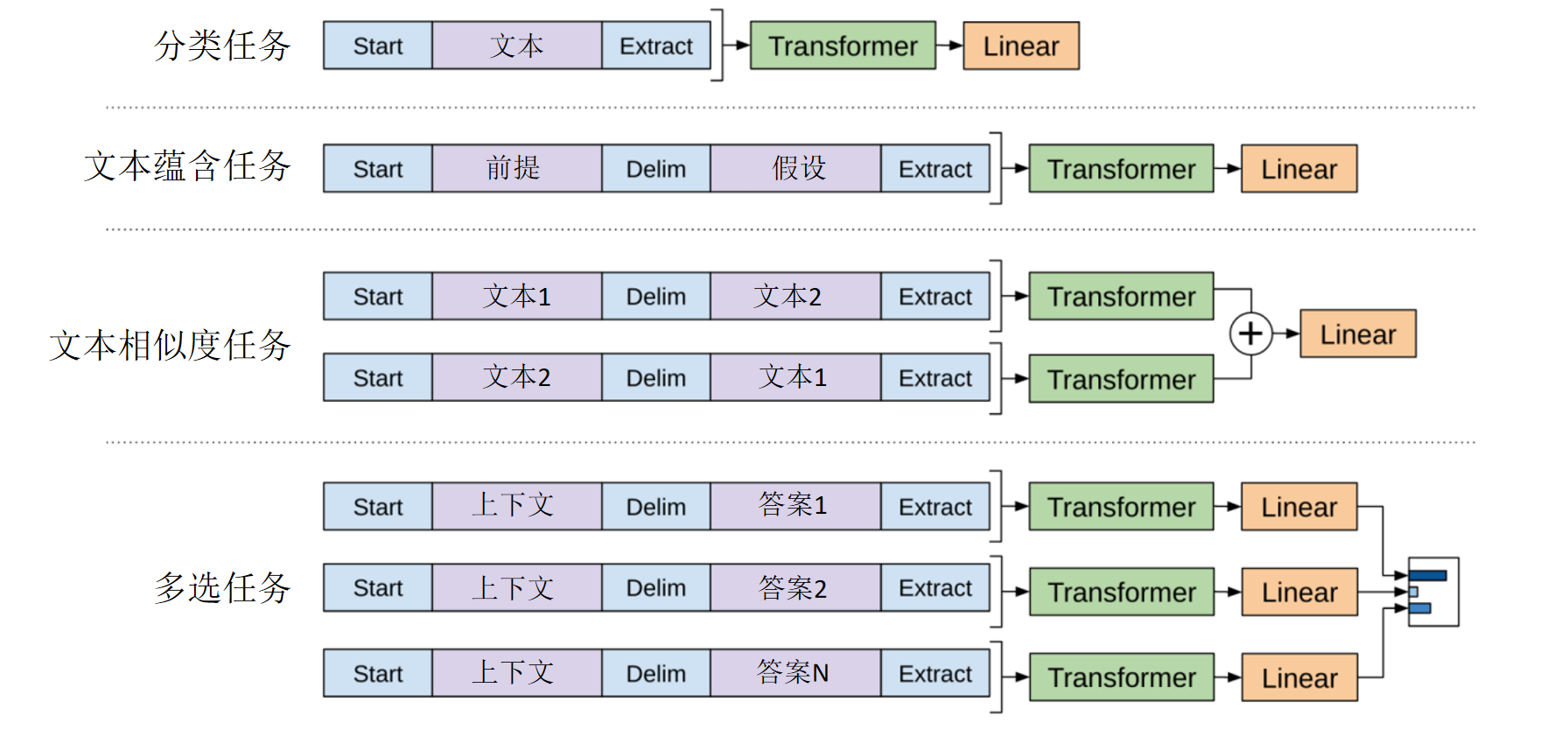
文本分类任务
- 在文本前后加入表示开始和结束的 token;
- 最后一个token的输出向量接入一个线性分类器,直接进行分类。
文本蕴含任务(Textual Entailment)
- 输入为两句话:前提 + 假设;
- 结构为
[开始][前提][分隔符][假设][结束]; - 输出为三分类:“支持”、“反对”或“不相关”。
语义相似度评估
- 同样使用
[开始][句子1][分隔符][句子2][结束]的输入格式; - 因任务对称,交换句子位置进行两次推理,将输出向量相加后输入到线性层中做分类。
多项选择题
- 将每个问题与每个选项组合为独立序列;
- 每个序列送入 GPT-1 得到得分,通过 softmax 计算每个选项的概率。
这种将任务指令融入输入序列的策略使 GPT-1 能以极少的结构修改适应不同任务,并充分利用其在预训练中学习到的语言能力。
16.1.4 多任务联合训练
在下游任务微调时,GPT-1 同时执行两个目标:
- 特定任务的分类目标;
- 自回归语言模型任务(预测下一个词)。
通过为这两个损失函数设置不同的权重,实现多任务学习,有助于模型保持语言建模能力的同时提升特定任务性能,增强泛化能力。
16.1.5 训练数据与设置
GPT-1 的预训练使用了 BooksCorpus 数据集:
- 包含约 7000 本未出版图书;
- 总词量约为 8 亿;
- 上下文窗口长度:512 个 token;
- 批处理大小:32。
16.1.5 效果
GPT1通过“预训练+微调”的范式,用通用的模型架构,通过对不同人物设计不同的输入的方式下,不对模型结构进行大幅修改,在12个NLP任务中,有9个刷新了当时的最好成绩,显示出其强大的通用性和迁移能力。
GPT-1 的发布,标志着以无监督预训练为核心的大模型路线正式确立。它证明了即使使用最基础的“预测下一个词”的目标,也能学到强大的语言表示能力,并且易于迁移到多种 NLP 任务中。这为后续如 GPT-2、GPT-3 和 GPT-4 等更强大的语言模型奠定了坚实的基础。