12.4 Token编码
我们主要关注如何用神经网络来解决NLP问题,根据之前我们的学习,我们知道神经网络只能处理数字。而句子的输入是一些Token。如何让神经网络来处理这些Token呢?那就是对Token进行编码。
12.4.1 独热编码
之前我们介绍过独热编码(one-hot encoding),它是一种最简单、最直观的Token编码方式。其核心思想是将每一个不同的Token映射为一个长度为词汇表大小(Vocabulary Size, 通常记作V)的向量。在该向量中,只有与当前Token对应的位置为1,其余位置均为0。 例如,假设我们的词汇表是:
["我", "喜欢", "学习", "深度"]
词汇表大小V = 4,那么:
"我" 的独热编码是 [1, 0, 0, 0]
"喜欢" 的独热编码是 [0, 1, 0, 0]
"学习" 的独热编码是 [0, 0, 1, 0]
"深度" 的独热编码是 [0, 0, 0, 1]
通过独热编码,神经网络可以接收数字向量作为输入。然而,独热编码也存在明显的缺点:
维度高:词汇表越大,独热向量的维度越高,计算和存储成本增加。假如一个词典有15万的词,那么每个Token的维度就为15万,这个计算代价就太大了。
稀疏性强:大部分位置为0,信息利用率低。
无法表达词之间的关系:不同Token之间的独热编码是正交的(即内积为0),无法体现它们之间的语义相似性。比如“土豆”和“马铃薯”两个词本来是同一个意思,但是它们的编码却毫无关系。
因此,在现代NLP系统中,我们通常不会直接使用独热编码来表示Token。
12.4.2 词嵌入
词嵌入(Word Embedding)是一种将Token编码成低维、稠密向量的技术。词嵌入的目标是通过学习,将语义相似的词映射到空间中相近的位置上。这里的词指的就是Token。
举例来说,假设词嵌入的维度为4,我们得到如下的词嵌入:
| Token | 性别 | 可食用性 | 重量 | 尊贵性 |
|---|---|---|---|---|
| 国王 | 0.93 | 0.13 | 0.3 | 0.98 |
| 皇后 | -0.91 | 0.11 | 0.23 | 0.97 |
| 男人 | 0.97 | 0.19 | 0.28 | 0.20 |
| 女人 | -0.93 | 0.17 | 0.21 | 0.19 |
| 土豆 | 0.01 | 0.98 | 0.05 | 0.04 |
| 马铃薯 | 0.01 | 0.97 | 0.05 | 0.04 |
可以发现,每个维度都有具体的含义,土豆和马铃薯在各个维度上的值都基本相等,这表明它们两个在物理世界中代表同样的含义。国王和皇后的尊贵性都高于男人和女人。国王和男人的性别维度都为正值,而皇后的女人的性别维度都为负值。
更神奇的是,通过良好的词嵌入甚至具有一些推理的能力,比如在上边这个例子里。我们发现对Token的向量在嵌入空间里做运算,有如下的结果:
国王 - 皇后 ≈ 男人 - 女人
有了这个推理能力,假如我们知道中国的首都是北京,但是不知道柬埔寨的首都在哪里,就可以生成一个向量:
北京 - 中国 ≈ ?- 柬埔寨
?≈ 北京 - 中国 + 柬埔寨
经过计算得到一个向量,然后我们就在所有的词嵌入里找哪个词的Embedding和这个计算出的Embedding最接近。你会发现找到的词是:金边。
相较于独热编码,词嵌入具有如下优势:
低维稠密:大大降低了计算和存储成本。比如大语言模型里一般只用几千维的向量来表示一个Token。
语义表达能力强:向量之间的距离、方向能够体现词的相似性、关系等语义特征。
可迁移性好:预训练好的词嵌入可以迁移到不同的下游任务中使用,提升模型效果。
词嵌入有这么多好处,那我们该如何得到Token的Embedding呢?答案是它们都是通过神经网络训练得到的。上边我们例子中的“性别”、“可食用性”、“重量”、“尊贵性”等属性都是为了方便大家理解人为设定的,具体神经网络学到的每个维度是什么含义,完全是由神经网络决定的。可能有物理含义,也可能没有。
Google在2013年提出的Word2Vec,是最著名的词嵌入实验。它通过大规模的数据,训练出来的Embedding具有很强的语义能力(“国王 - 皇后 ≈ 男人 - 女人” 这样的向量推理现象)。很快推动了词嵌入的普及。Word2Vec用了两种训练方法,分别是CBOW(Continuous Bag of Words)和 Skip-gram。
这两种训练方法的目标相同:从大量无标签文本中学习高质量的词向量,这些向量能够捕捉词语的语义和语法信息。但它们的实现方式和侧重点有所不同。
核心思想:
两者都基于分布式假设:一个词的语义由其出现的上下文决定。
它们都是浅层神经网络模型(通常只有一个隐藏层)。
它们都采用无监督学习,只需要大量的原始文本。
训练完成后,隐藏层的权重矩阵(或其特定形式)就是我们需要的词向量。
12.4.3 CBOW
是一种通过上下文预测中心词的词向量训练模型。其核心思想是用上下文词向量的平均值预测中心词。这里的词指的就是Token。
假设我们取中心词前后各2个词来预测中心词。但在句子边界处可动态缩减。
输入句子为“I love natural language processing”
则对于CBOW模型的输入和输出如下:
| 输入 | 输出 |
|---|---|
| ["love","natural"] | "I" |
| ["I","natural","language"] | "love" |
| ["I","love","language ","processing"] | "natural" |
| ["love","natural","processing"] | "language" |
| ["natural","language"] | "processing" |
接着对每个Token生成独热编码:
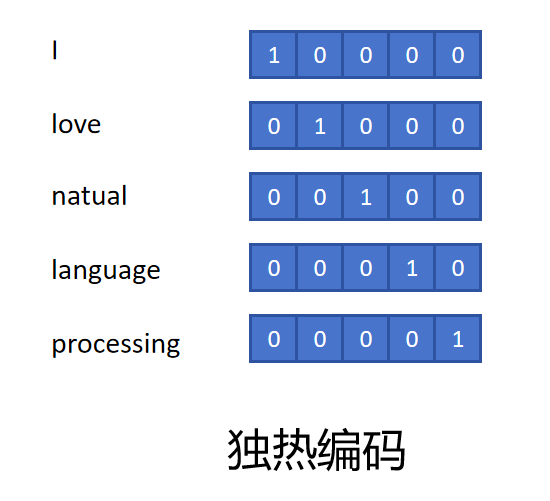 然后给每个Token随机初始化一个Embedding,假设Embedding的维度为4,所有Token的Embedding形成一个Embedding矩阵。
然后给每个Token随机初始化一个Embedding,假设Embedding的维度为4,所有Token的Embedding形成一个Embedding矩阵。
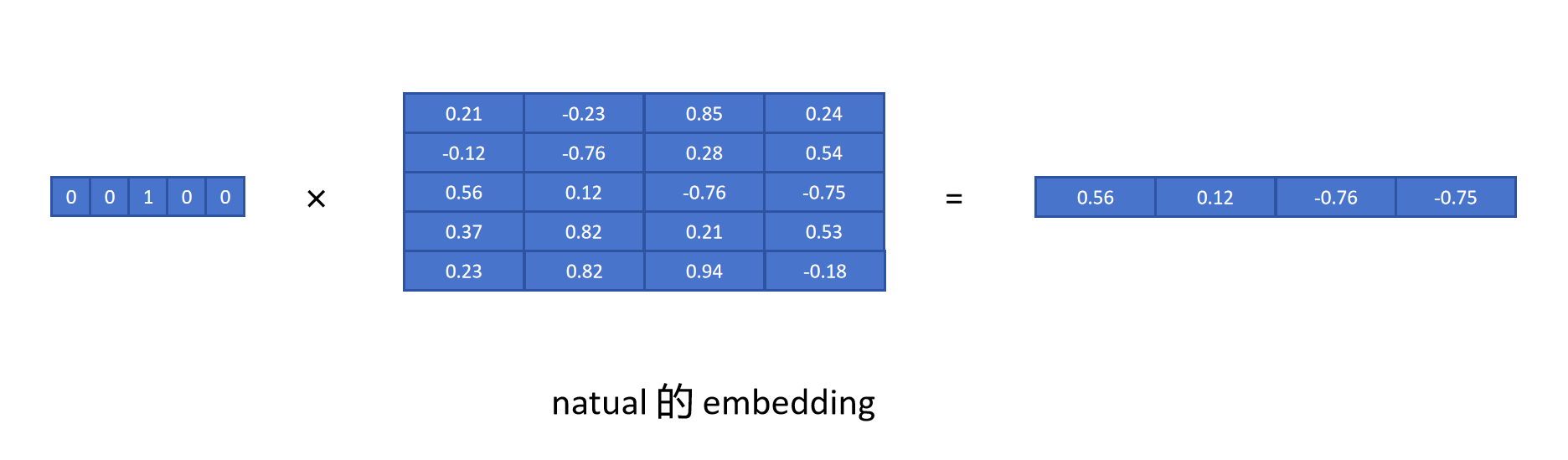
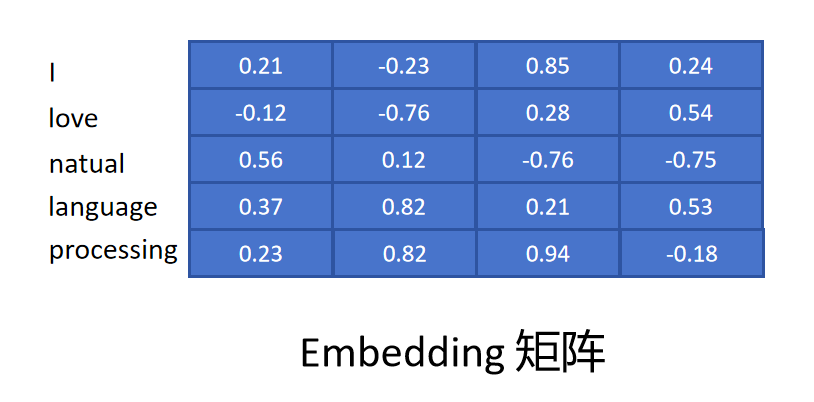 这样,我们想取得一个Token的Embedding时,只需要用Token的独热编码乘以Embedding矩阵即可。
这样,我们想取得一个Token的Embedding时,只需要用Token的独热编码乘以Embedding矩阵即可。
CBOW的网络结构非常简单: 对于中心词为“natural”,它的输入有4个词。首先获得这四个词的Embedding,然后取平均值,再接一个线性层,这个线性层神经元的个数为词典的大小,比如上边的例子,我们词典大小为5。然后用softmax做分类,Label为“natural”。利用交叉熵损失函数训练模型。
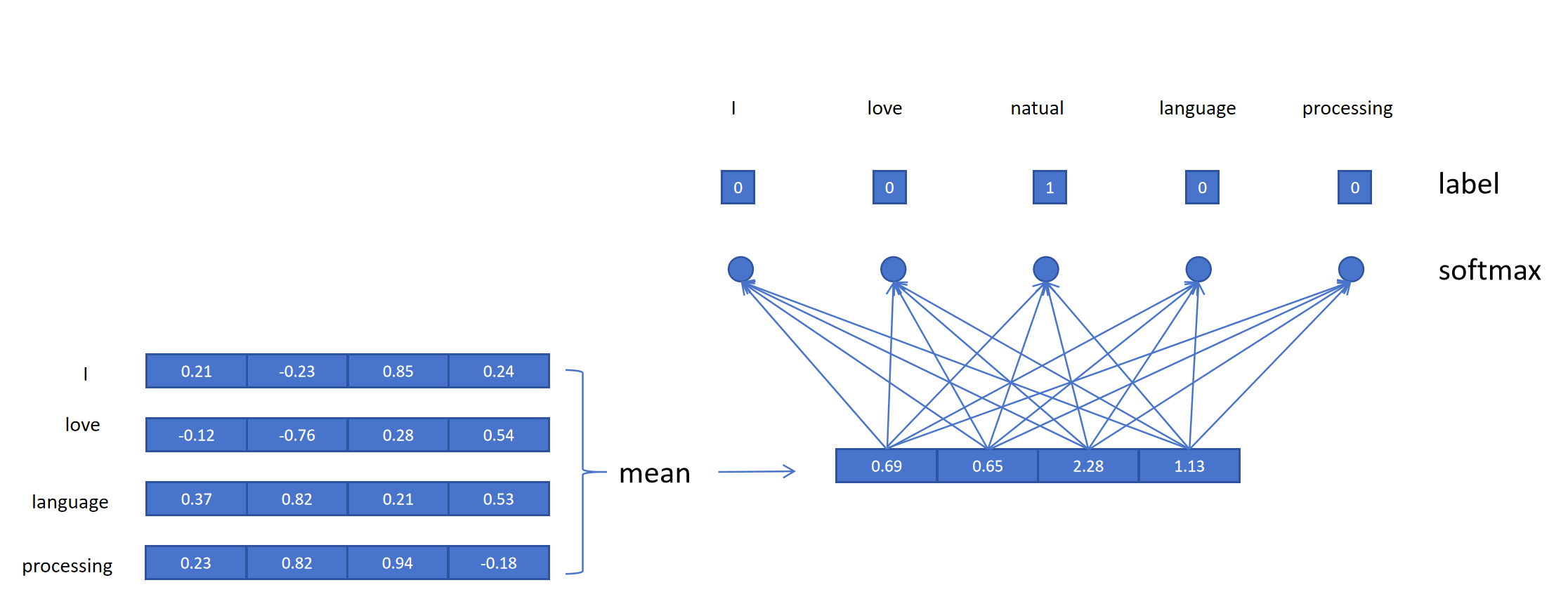
需要特别注意的是这里的Embedding矩阵里是可学习的参数,每次训练过程都会更新Embedding矩阵的值,同样网络的分类线性层的参数也是被更新的。但是最终我们训练的目的是得到Embedding矩阵的值,这个矩阵里每一行的向量代表了一个Token的Embedding。
经过大量训练后,我们得到的Embedding矩阵就是所有Token很好的词向量。
12.4.4 Skip-gram
Skip-gram与CBOW刚好相反,它是利用中心词来预测上下文的词。同样它需要对Token进行独热编码,和构建Embedding矩阵。 假如每个中心词需要预测它前后2个词,则对于上边的例子,它的输入输出为:
| 输入 | 输出 |
|---|---|
| "I" | "love" |
| "I" | "natural" |
| "love" | "I" |
| "love" | "natural" |
| "love" | "language" |
| "natural" | "I" |
| "natural" | "love" |
| "natural" | "language" |
| "natural" | "processing" |
| "language" | "love" |
| "language" | "natural" |
| "language" | "processing" |
| "processing" | "natural" |
| "processing" | "language" |
Skip-gram模型的输入只有一个Token,所以不需要进行多Token Embedding的平均,直接用输入Token的Embedding作为输入,然后和CBOW一样接一个线性分类头,预测输出Token。经过大量训练后也可以得到很好的Embedding矩阵。
值得注意的是在训练CBOW和Skip-gram算法时,需要平衡常见词和罕见词的影响。可以对常见词进行下采样,或者对罕见词进行上采样。
12.4.5 现代大模型
现代大模型会随机初始化每个Token的Embedding,然后随着大模型本身任务的训练,一起同步训练Embedding。这样就会得到更适合任务本身的Token Embedding。