11.2 AlexNet
2012年,深度学习迎来了历史性的一刻:AlexNet在ImageNet图像识别比赛(ILSVRC)中大放异彩,以压倒性优势击败传统计算机视觉方法,开启了深度学习在视觉领域的黄金时代。
11.2.1 ImageNet
2009 年,斯坦福大学的李飞飞教授(Fei-Fei Li)及其团队提出了 ImageNet 项目,旨在构建一个大规模、标注详尽的图像数据库。当时,计算机视觉领域的研究大多依赖于小规模、手工收集的数据集(如 CIFAR-10、MINIST 等),图像种类有限,标注数量稀缺,严重制约了深度学习模型的训练与泛化能力。ImageNet 最初收集了约 1,400 万张图像,并在其中挑选了 1,000 类常见物体进行精细标注,每类约 1,000 张图像。
2010 年起,ImageNet 大规模视觉识别挑战赛(ILSVRC,ImageNet Large Scale Visual Recognition Challenge)每年举办,成为深度学习领域的重要风向标。受到学者和企业的广泛关注。
在2012年之前,图像识别主要依赖手工特征和浅层模型,如SIFT特征、HOG描述符、支持向量机(SVM)等。然而,ImageNet比赛的复杂性(1000个类别、百万级图像)对传统方法提出了巨大挑战。
卷积神经网络虽然早已提出,但由于计算能力和数据量的限制,长期未能发挥优势。随着GPU的普及和大规模数据集的出现,训练深层卷积神经网络成为可能。AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年提出的卷积神经网络架构,专为图像分类任务设计。它在ImageNet 2012挑战中将Top-5错误率从26%降低到了15%,领先第二名10个百分点,震惊业界。
11.2.2 网络架构
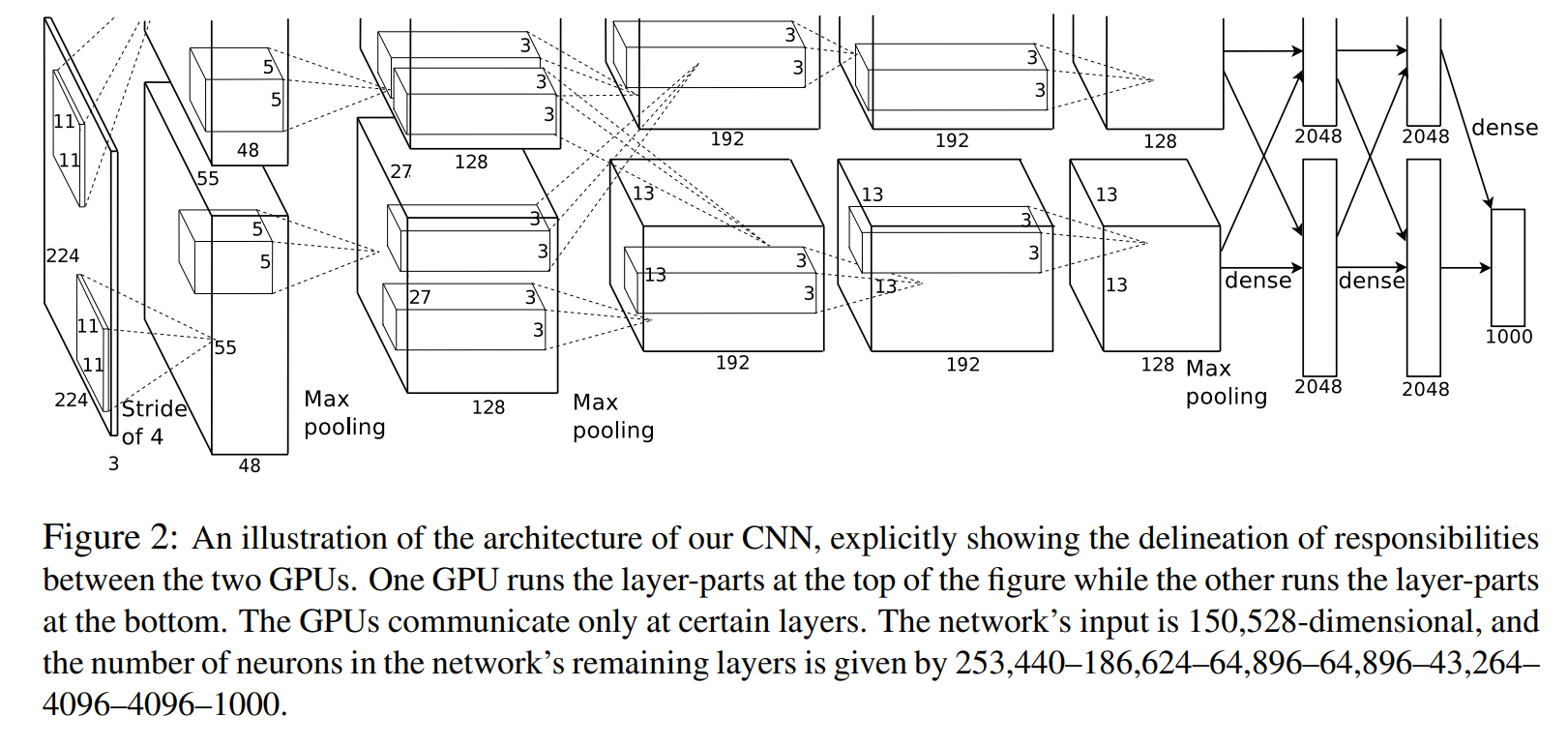
可以看到上图分为上下两部分,这是因为它当时使用了两块GPU来进行并行计算,两个GPU只在特定层进行通讯。
| 层次 | 类型 | 输出尺寸 | 说明 |
|---|---|---|---|
| 输入层 | - | 224×224×3 | RGB图像输入 |
| 第1层 | 卷积层(11×11, stride 4)+ ReLU + LRN + MaxPool | 55×55×96 | 较大卷积核用于初始特征提取 |
| 第2层 | 卷积层(5×5, stride 1)+ ReLU + LRN + MaxPool | 27×27×256 | 局部响应归一化提高泛化能力 |
| 第3层 | 卷积层(3×3)+ ReLU | 13×13×384 | 更细粒度的特征提取 |
| 第4层 | 卷积层(3×3)+ ReLU | 13×13×384 | 与第3层配合提取复杂模式 |
| 第5层 | 卷积层(3×3)+ ReLU + MaxPool | 6×6×256 | 下采样提取语义信息 |
| 第6层 | 全连接层 + ReLU + Dropout | 4096 | 用于分类的高级特征 |
| 第7层 | 全连接层 + ReLU + Dropout | 4096 | 防止过拟合 |
| 第8层 | 全连接层 + softmax | 1000 | 输出1000类概率分布 |
11.2.3 网络实现
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2), # 输出: 96x55x55
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2.0),
nn.MaxPool2d(kernel_size=3, stride=2), # 输出: 96x27x27
nn.Conv2d(96, 256, kernel_size=5, padding=2), # 输出: 256x27x27
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2.0),
nn.MaxPool2d(kernel_size=3, stride=2), # 输出: 256x13x13
nn.Conv2d(256, 384, kernel_size=3, padding=1), # 输出: 384x13x13
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1), # 输出: 384x13x13
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # 输出: 256x13x13
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2) # 输出: 256x6x6
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
11.2.4 AlexNet的关键创新点
- 使用ReLU激活函数
在当时,Sigmoid或Tanh是主流激活函数。AlexNet大胆采用了ReLU。相比Sigmoid,ReLU训练更快,不易梯度消失。
- 使用Dropout防止过拟合
在全连接层引入Dropout技术,训练时随机丢弃部分神经元,大大减少了过拟合风险。
- GPU并行训练
AlexNet使用两个GPU训练网络的不同部分,这在当时是很创新的做法,大大提升了训练效率。
- 局部响应归一化(LRN)
在前两层使用了LRN来增强ReLU的响应效果,尽管这一技术后来被Batch Normalization取代,但在当时有效提升了模型性能。
- 应用了图像增强技术
AlexNet进行了数据增强,随机从256_256的原始图像中截取224_224大小区域,并以50%的概率做水平翻转,并且进行了光照扰动图像增强。
11.2.5 AlexNet的意义
AlexNet的成功展示了“更深的网络 + 大量数据 + 强大计算力”三位一体的重要性。它的成功让深度学习从学术走向工业,促使Google、Facebook等巨头全面转向神经网络。它在ImageNet上的优异表现开启了CNN黄金时代,其后更多深层次卷积神经网络纷纷涌现,形成CNN快速迭代浪潮。并且它催生了硬件发展,让GPU成为训练深度模型的标配。