7.8泰坦尼克号生存预测
接下来几节,我们来做一个实际的例子,用逻辑回归对真实的泰坦尼克号乘客数据进行建模。你可以去这个地址下载数据。
下载后的数据包含了训练集数据和测试集数据。
在机器学习领域,数据清洗,数据准备是非常重要的一步。但这不是我们这门课的重点,今天我们针对这个示例数据,做一些简单的数据准备工作。
7.8.1查看数据
数据准备的第一步工作,是对数据进行探索,观察你要进行建模分析的数据。
打开其中的train.csv文件,我们对数据进行查看:
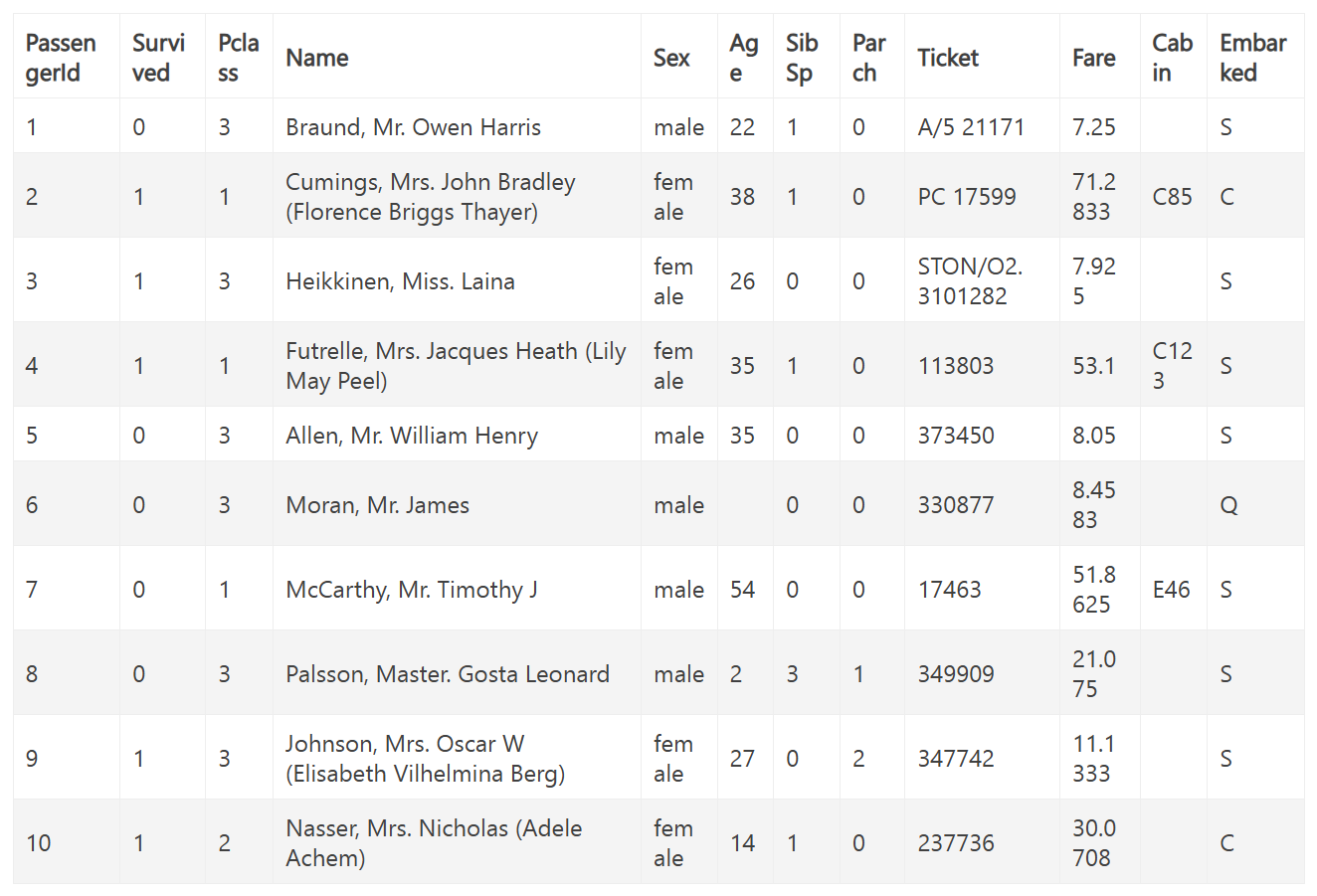
其中列的含义如下:
| 列名 | 含义说明 |
|---|---|
| PassengerId | 乘客的唯一编号(标识符),每位乘客对应一个 ID |
| Survived | 是否生还(0 = 没有生还,1 = 生还) |
| Pclass | 舱位等级(1 = 一等舱,2 = 二等舱,3 = 三等舱) |
| Name | 乘客姓名 |
| Sex | 性别(male = 男,female = 女) |
| Age | 年龄(单位:岁,部分为空表示未知) |
| SibSp | 同船的兄弟姐妹或配偶的数量(Siblings/Spouses Aboard) |
| Parch | 同船的父母或子女的数量(Parents/Children Aboard) |
| Ticket | 船票号码 |
| Fare | 船票价格(单位:英镑) |
| Cabin | 舱位号(可能缺失) |
| Embarked | 登船港口(C = Cherbourg,Q = Queenstown,S = Southampton) |
7.8.2去除列
首先我们识别哪些列对我们预测乘客是否存活无关,然后将它们从数据集中去除。其中PassengerId列,Name列,Ticket列这三列和乘客生存没有明显关系,可以去除。另外仓位号(Cabin)有大量缺失值,也从数据中去除。
7.8.3去除行
有很少部分的乘客的年龄是缺失的,我们去除这些数据样本,删除缺失年龄数据的样本。
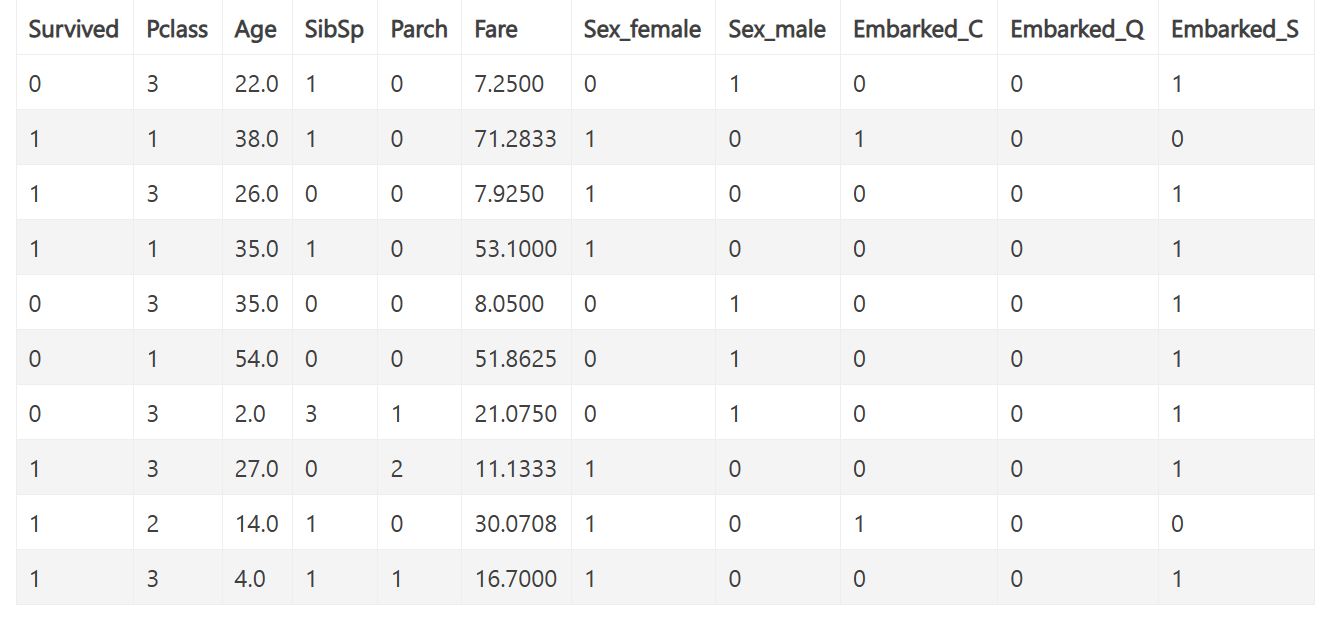
7.8.4独热编码
根据我们之前学习的逻辑回归,它只能处理连续变量。但是我们数据中的Sex(性别)和Embarked(登陆港口)两个特征列的取值都是从一组字符串中进行选择的。比如Sex是从[“male”,“female”]中选择的。这种特征,我们叫做离散特征。
我们今天介绍一种将离散特征转变成连续特征的编码方式,这就是独热编码。
独热编码的原理比较简单,原始离散特征有几个离散取值,就生成几个列。每个样本在这几个列的取值,只能是0或者1。比如原始Sex列,就转化为Sex_male和Sex_female两列,如果某个乘客是男性,则Sex_male列的值就是1,Sex_female列的值就是0。
同样对于Embarked列,就新生成Embarked_C,Embarked_Q,Embarked_S列。如果一个乘客是从Cherbourg登船的,则Embarked_C列值为1,Embarked_Q,Embarked_S列取值为0。
可以发现对于独热编码而言,每个离散列,假如有N个可能的取值,就新生成N列。而且对于每个样本,在这N个列里,只有一列取值为1,其他列取值都为0,这也是为什么它被叫做独热编码的原因。
7.8.5处理代码
使用pandas库可以方便的处理数据,你需要在你使用的conda env里安装pandas库。如果你不熟悉pandas也没有关系,后边的学习中不会再用到,这里你就按照这个代码来处理数据就可以。 处理的代码如下:
import pandas as pd
pd.set_option('display.max_columns', None)#打印时显示所有列。
# 从CSV文件读取数据(确保你有正确的路径)
df = pd.read_csv(r"<YOUR_DATA_PATH>\titanic\train.csv")
# 去除不需要的列
df = df.drop(columns=["PassengerId", "Name", "Ticket", "Cabin"])
# 去除 Age 缺失的样本
df = df.dropna(subset=["Age"])
# 对 Sex 和 Embarked 做独热编码
df = pd.get_dummies(df, columns=["Sex", "Embarked"],dtype=int)
print(df.head(10))7.8.6处理后的数据
处理后的示例数据如下: