10.1 视觉问题的特点
我们通过一个例子来了解一下视觉问题有什么普遍的特点。
10.1.1 识别猫
假设我们想判断一张图片里是否有猫。

输入特征多
图片是由像素构成,现在的手机拍摄的相片都有几千万像素。黑白图片每个像素只有一个灰度值。彩色图片每个像素有(R,G,B)三个值,分别代表红、绿、蓝。 如果一个图片长宽为1000x1000个像素的彩色图片,输入特征也有300万个,如果隐藏层也为1000个神经元,输出层为1个神经元,那么这个网络将有30亿个参数,以Float32来存储,模型大小为12GB。这么大的模型推理一次的运算代价是非常大的。
局部性
在图像里局部区域内的像素构成了重要的特征,每个像素和它周围局部区域内的像素关系紧密。比如我们识别一只猫,只要观察这个猫在图片里的区域就可以确定,无需依赖其他地方的像素信息。如果我们用全连接神经网络,每个神经元都是和所有输入像素相连的。但其实判断一个特征,只需要局部像素就可以,没有必要用全部的像素。这些没有必要的连接浪费了大量的权重参数。
平移不变性
不论一只猫在图片的左上角还是右下角。都不改变它是一只猫的语义信息。在计算机视觉中,语义信息(semantic information)是指图像中所表达的高层次、具有人类可理解意义的内容。如果我们训练了一个神经元,它可以接入局部的像素信息,识别一个猫,那么它就可以被复用,识别图片任意区域的猫。
10.1.2 步兵扫雷
我在学习卷积神经网络时,想到一个很好的类比,那就是步兵扫雷,它和我们在视觉问题里遇到的问题非常类似。
输入特征多 雷区可能很大,你不能造一个和雷区一样大的探测器,那样成本太大。
局部性 一个地雷只在一个雷区的局部。探测一个地雷,只需要探测一个局部地区就可以确定。
平移不变性 不论一个地雷在雷区的哪个位置,都是一样的。地雷的属性不会改变。
那现实中步兵是如何探雷的呢?
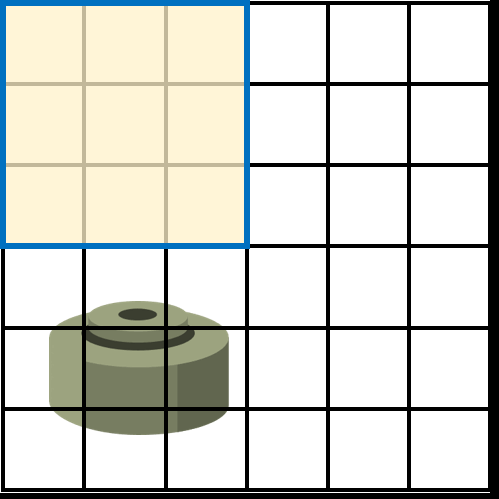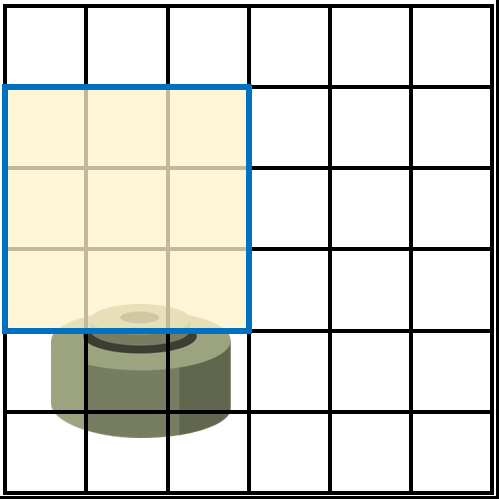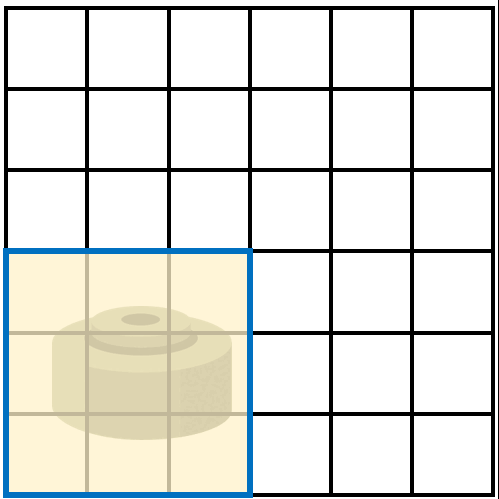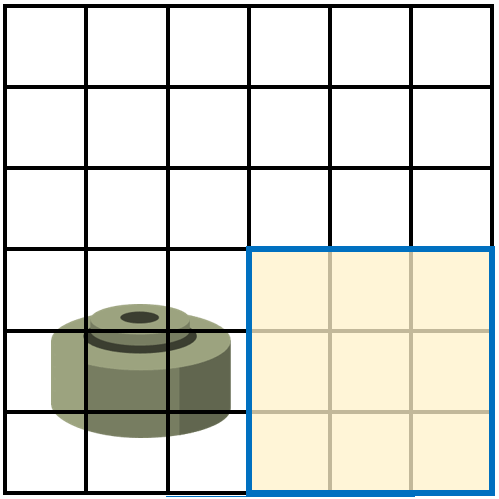
 假设雷区是一个6x6的区域,而探雷器能探测的区域为3x3,那么步兵会用探雷器在整个雷区做从上到下,从左到右的扫描,来检查每一个3x3的区域是否有地雷。
假设雷区是一个6x6的区域,而探雷器能探测的区域为3x3,那么步兵会用探雷器在整个雷区做从上到下,从左到右的扫描,来检查每一个3x3的区域是否有地雷。