18.2 DeepSeekMOE
上一节我们讲了普通的MOE大模型的架构,这一节我们就来学习DeepSeekMOE。DeepSeekMOE的论文题目为:迈向让专家更加专精的MOE语言模型(DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models)。可以看到DeepSeekMOE的改进点是让专家更加专精。
18.2.1 架构改进
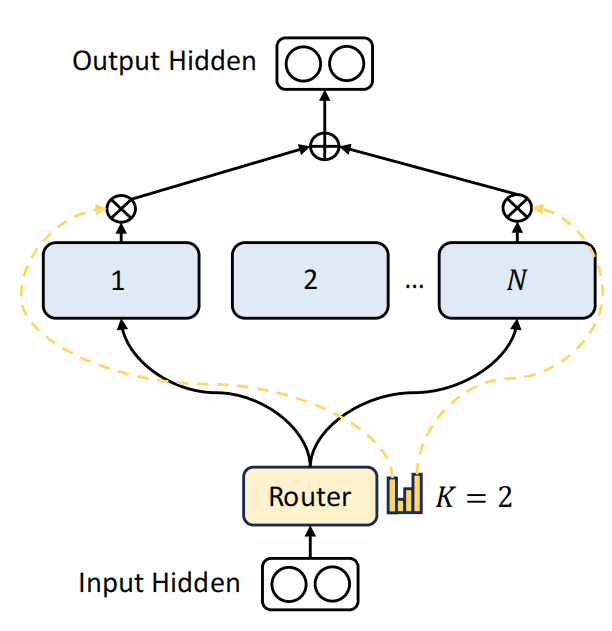 基础的MOE实现如上图,假设有N个专家,每次选择2个专家。DeepSeek认为传统的MOE设置的专家数太少了,导致每个专家学习了过多,彼此不相关的知识,从而不够专精。比如一个医院里只有2名医生,一个内科一个外科,那每个医生要掌握的医学领域就很广。不利于医术的精进。
基础的MOE实现如上图,假设有N个专家,每次选择2个专家。DeepSeek认为传统的MOE设置的专家数太少了,导致每个专家学习了过多,彼此不相关的知识,从而不够专精。比如一个医院里只有2名医生,一个内科一个外科,那每个医生要掌握的医学领域就很广。不利于医术的精进。
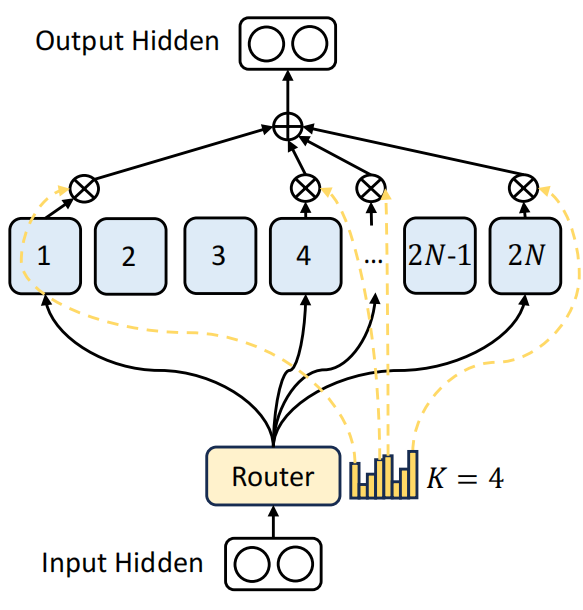
DeepSeek想到的办法就是将专家进行更进一步的细分,同时每个专家的网络也变小。比如这里,将原来N个专家变为2N个专家。每个专家网络参数量也为原来专家的一半。这样在网络前向传播时,维持和之前网络同样计算代价的前提下,就可以激活4个专家。
假如原来有8个专家,激活2个专家,现在细分为16个专家,激活4个专家。原来8个里边选2个,有28种可能的组合,现在是16个专家里边选4个专家,就有1820种可能的组合。这种组合方式更灵活。就像医院里分了各个科室,每个专家负责的东西变少,也有利于让每个专家学习到更加专精的内容。
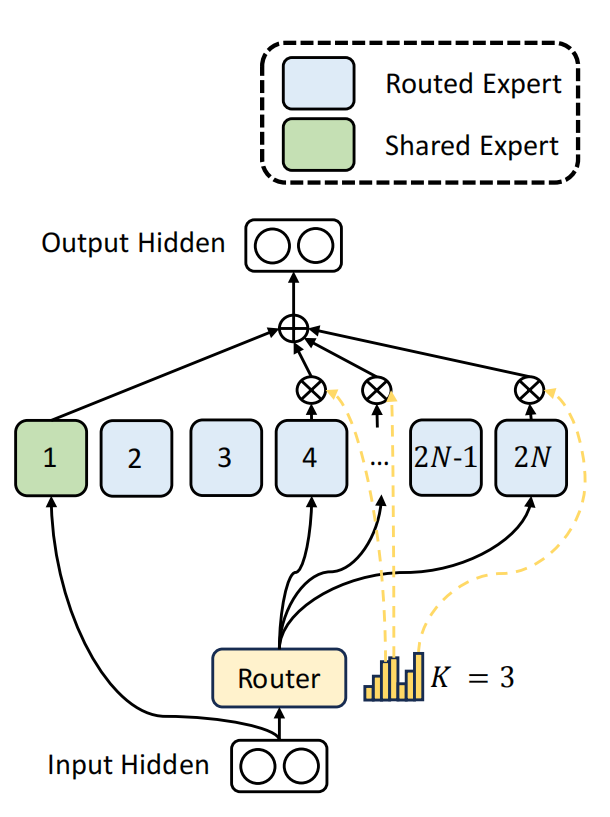
DeepSeek又进一步想所有专家,可能都要学习一些基础的能力,是否可以将所有专家都要学习的通用基础能力提取出来,作为一个共享专家。共享专家保证每次都被激活,负责所有专家原来都需要的通用能力。你可以理解为医院里的各个科室都需要验血。那就把验血作为一个共享科室,所有科室都可以利用。
比如这里在细分的2N个专家里,提取出一个专家作为共享专家,他每次都被激活,然后再从后边2N减1个专家里选择3个专家。这样保证路由专家和共享专家总数不变,还是4。和原来选择2个共享专家的原始MOE网络计算代价是相同的。
18.2.2 模型效果
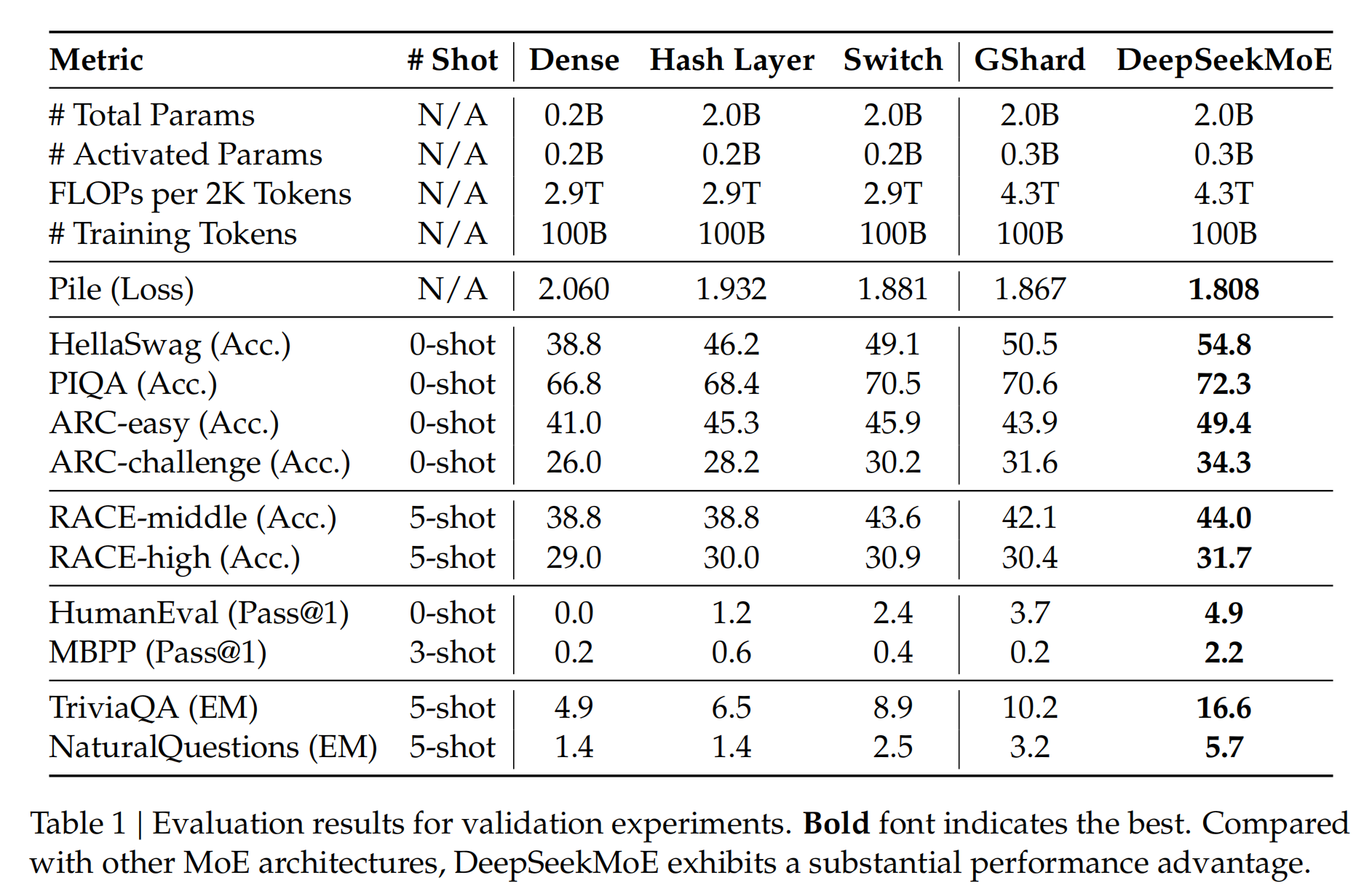
通过这些改进,可以看一下DeepSeekMOE的效果,它在同等计算代价的情况下比稠密网络和普通MOE的效果都有很大的提升。
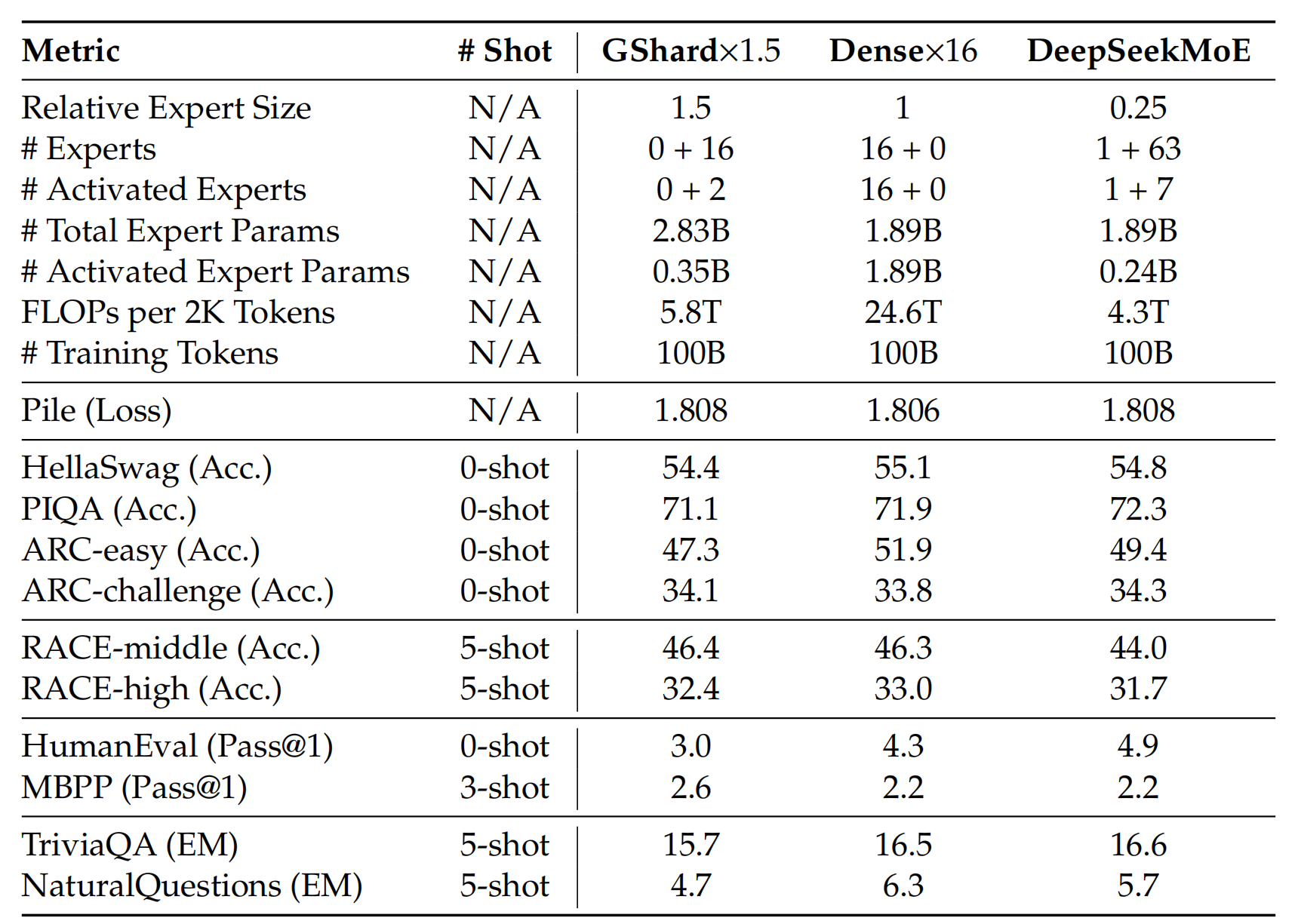
而且DeepSeek也做了实验,就是DeepSeekMOE的性能已经达到MOE模型的极限,也就是基本与每次全部激活的稠密网络性能相当。
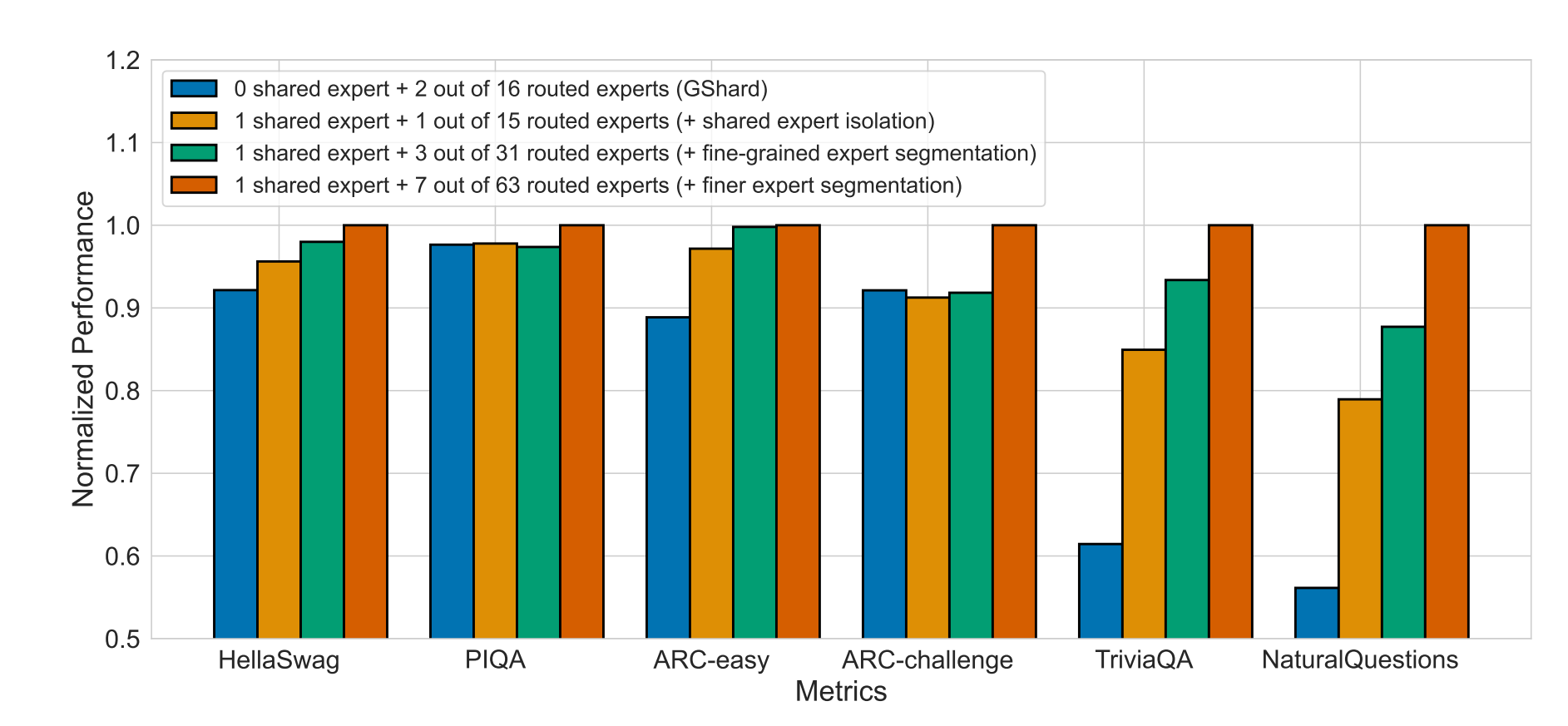
上边这张图,通过消融实验,验证了DeepSeek对模型进行细分,以及抽取出共享专家的作用。横坐标是不同的测试集,每个测试集上的四个表现是四种不同的网络结构。前提是保证这四种网络结构他们的网络总参数,运行时激活的参数量都是相等的。从左到右依次是:第一个从16个专家里激活2个专家的表现。第二个,从16个专家里提取一个共享专家,运行时每个token再选择一个路由专家。第三个,细分为32个专家,其中1个共享专家,运行时路由3个专家。第四个,更细分为64个专家,其中1个共享专家,运行时路由7个专家。可以看到,提取共享专家和对专家进行细分都是有利于模型性能提升的。
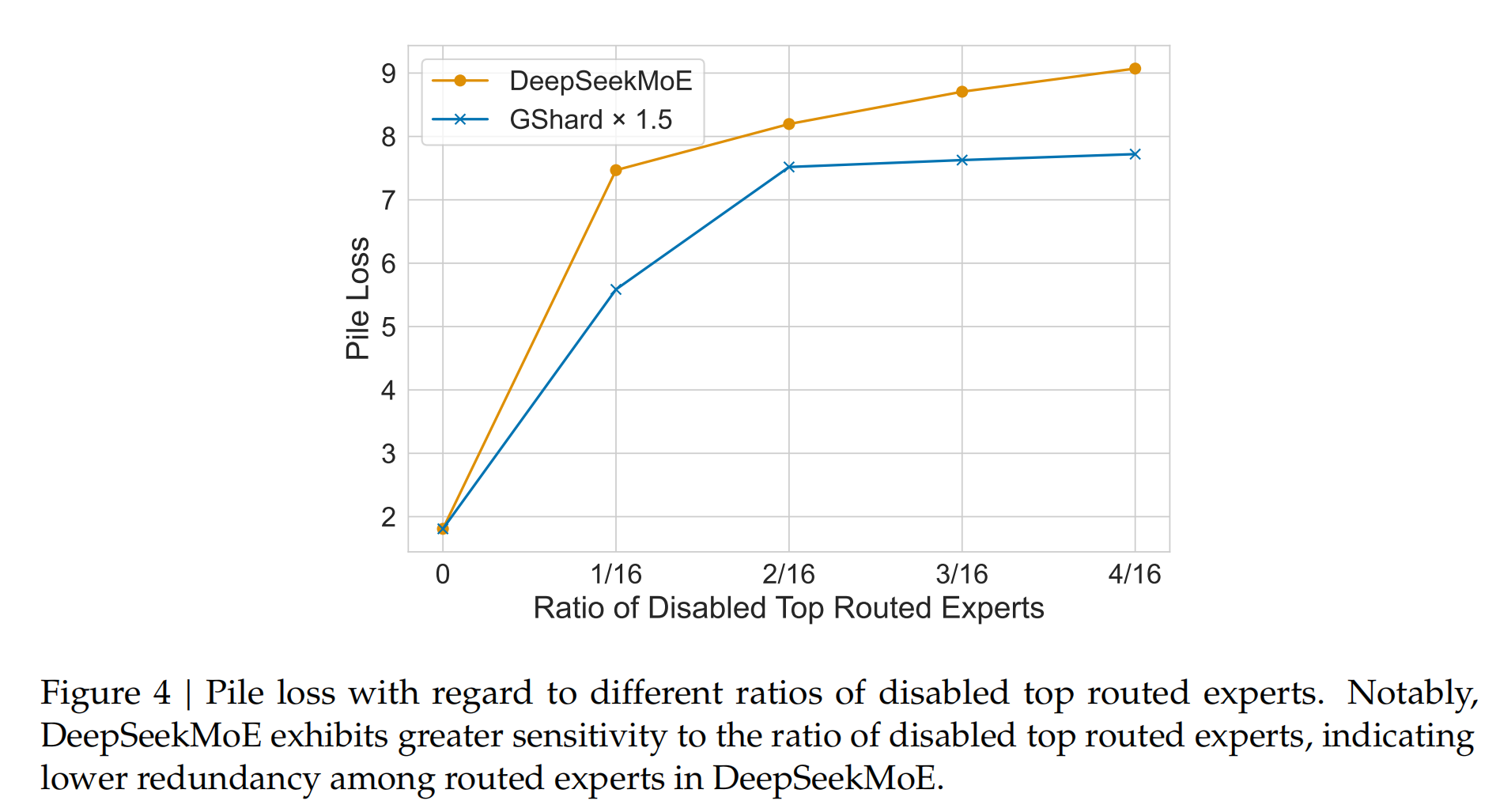
这张图是DeepSeekMOE和同等规模的GShard在禁用掉不同比例最高权重专家后Loss的改变,可以看到禁用掉同样比率的最高权重专家后,DeepSeek的性能下降更明显,这也证明了DeepSeek的专家专业性更强,与其他专家之间不能互相替代。
这些实验都足以证明DeepSeek MOE架构的优越性。