12.5 语言模型采样
大语言模型的出现,彻底颠覆了NLP领域,甚至颠覆了整个人工智能领域。后边章节我们会讲如何训练大语言模型,本节我们先来讨论如果我们已经有了一个语言模型,如何利用它。本书后边讨论的语言模型都是指神经网络语言模型,不是统计语言模型。
12.5.1 计算文本序列的概率
语言模型的最初的作用就是生成文本序列的概率,比如我们给出两句读音相同的话:
“我每天都要洗澡”
“我每天都要洗枣”
输入语言模型后,语言模型会输出每个token出现在这句话中的概率值,我们只需要对这些概率值进行连乘就可以得到这句话合理性的概率。实际实现中因为每个token的概率都很低,连乘值太小,可以转化为每个概率值的log值的连加来代表整句话合理性的大小。
12.5.2 生成文本
大语言模型的成功正是直接利用了语言模型的生成能力。你可以给出一个文本序列的开头,比如:
“今天天气”
大模型通过计算在输入token后增加词典里任一token的概率值,然后根据某种策略选取一个token,加到原始文本后边,比如我们选择概率最大的token。它是“真”,于是现在的序列变为:
“今天天气真”
接着,计算以“今天天气真”为输入序列,后边增加任一token的概率,再取最高概率的token,假如这个token是“好”。那么更新后的序列就为:
“今天天气真好”
依次类推,语言模型就可以不断生成新的token。直到语言模型输出我们约定的序列结束符<eos>停止。
12.5.3 概率最大生成策略
语言模型生成时每次都取最大概率的token,这是贪婪策略。这可能是大家最容易想到的一种策略。你可能认为这可以生成语言模型认为概率最大的文本序列,但实际情况并非如此。因为我们的目的是生成整个输出序列的联合概率最大,而不是每一步最大。
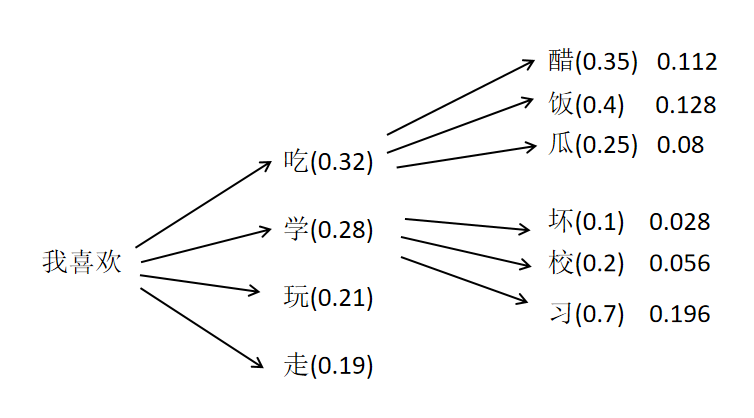 如果按照贪心算法,那么大模型输出为“我喜欢吃饭”。因为在每一步都选取当前步概率最大的token进行输出。但实际上,通过计算可以发现“我喜欢学习”的联合概率更高。
如果按照贪心算法,那么大模型输出为“我喜欢吃饭”。因为在每一步都选取当前步概率最大的token进行输出。但实际上,通过计算可以发现“我喜欢学习”的联合概率更高。
Beam Search 如何让大模型生成时可以找到这种整个序列概率最大的输出呢?贪心算法的问题是每一步都只选择概率最大的token,而丢弃了其他潜在序列概率最大的token。Beam Search,假如设置Beam为2,它会一直保留2个目前概率最大的序列,最终输出概率最大的那个序列。以下图为例,如果Beam为2,在第一个步,会保留“我喜欢吃”和“我喜欢学”两个序列,概率分别为0.32和0.28。接下来两个序列都会预测自己接下来的token,并计算联合概率。
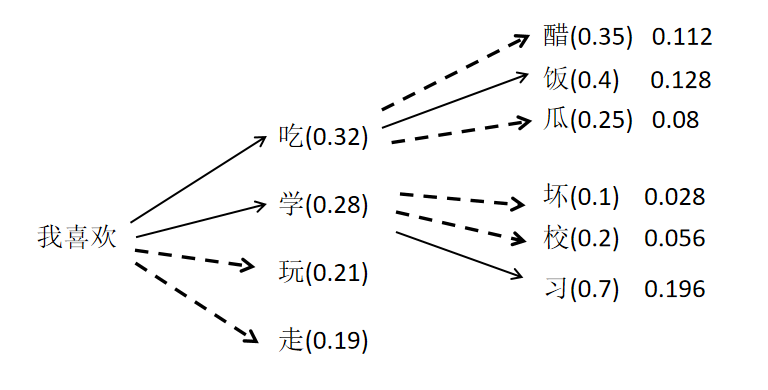
可以发现“我喜欢吃饭”的序列概率为0.128,“我喜欢学习”的序列概率为0.196。它们两个是第二步概率最大的两个序列。Beam Search会保留这两个序列,分别为它们生成下一个token。如果设置最大生成token数为2,也就是第二步就要输出。那此时输出的就是概率最大的序列:“我喜欢学习”。
你设置的Beam越多,越可能找到联合概率最大的输出序列。
12.5.4 随机生成策略
不论是贪婪生成策略,还是Beam Search, 语言模型生成的序列都是固定的,如果我们希望语言模型可以给我们生成笑话,我们希望它每次讲的笑话不一样。那么我们可以采取下边的策略:
Top_k 语言模型输出时,首先是输出每个token的logits的值,然后选取Top_k 个token保留他们的logits值,其他token的logits值设置为一个很大的负数。然后进行softmax(),这样,非Top_k的token被选择的概率就为0。然后按照token概率进行随机采样,生成下一个token。
Top_p 取概率最大的一批token,作为候选,它们的累加概率和必须刚好大于设置的参数Top_p。然后再对所有的候选token的概率值做softmax,让它们的概率和为1,然后按更新后的概率随机采样作为下一个token。
Temperature 控制语言模型生成随机性的还有一个重要的参数是温度值(Temperature)。当设置了温度值t后,大模型输出的logits会首先除以温度值。然后再进行后续的采样。温度值对softmax()最后生成的概率值的影响,如下图所示:

可以看到到温度值t取0.5时,最后每个token之间的概率差别较大。当t取2时,最后每个token之间的概率差别较小。也就是温度值越小,模型生成的序列越确定,温度值越大,模型生成的序列越不确定。