16.4 GPT-3和GPT-4
从 GPT-1 到 GPT-4,OpenAI 一路走来,每一代模型都在参数规模、任务能力和实际应用中取得了飞跃。但与此同时, OpenAI越来越不Open,技术报告透露出来的技术细节越来越少。所以,我们把GPT-3和GPT-4放到一节来讲。
16.4.1 GPT-3
继 GPT-2 之后,OpenAI 开始研发更大规模的 GPT-3,其论文名为《语言模型是少样本学习者》(Language Models are Few-Shot Learners)。研究的出发点是模仿人类的语言能力:我们只需几个例子,就能理解并完成新任务,而不需要成千上万的数据。
传统模型(如 BERT 和 GPT-1)在处理特定任务时,通常需要大量标注数据进行微调。而 GPT-3 探索的是另一种方式:能否仅通过“提示”(prompt)和少量示例,就完成复杂任务,而无需调整模型参数。
GPT-3 沿用了 GPT-2 的结构,并将模型规模推向了新高度,最大版本拥有 1750 亿个参数,在 3000 亿个 token 的文本数据上进行了训练。

GPT-3 提出了三种上下文学习方式:
零样本(Zero-shot):直接通过一个提示命令完成任务,例如:“将 cheese 翻译成法语”。
单样本(One-shot):提供一个示例后,再要求模型完成类似任务。
少样本(Few-shot):给出多个例子后,请求模型做同样的任务。
这种方法不需要微调模型,仅通过输入上下文就能引导模型完成不同任务,效果尤其明显。
技术特点
模型结构:GPT-3 与 GPT-2 类似,但引入了稀疏注意力机制,即每个 token 不再对所有前文 token 做注意力计算,只关注部分 token,从而提升效率,便于模型扩展。
数据来源:主要使用清洗后的 CommonCrawl 数据,以及维基百科、书籍等高质量文本。其中,维基百科虽然数据量小,但权重较高。
训练细节
上下文长度提升至 2048 token
批处理大小达 320 万
GPT-3 在少样本学习中的表现非常优秀,甚至在某些任务上超越了需要微调的监督学习模型。它的文本生成质量也非常逼真,尤其在新闻生成方面,已达到“真假难辨”的程度,引发了社会对人工智能生成内容的广泛讨论。
16.4.2 GPT-4
随着 GPT-3 的成功,OpenAI 接着推出了 GPT-4。但与之前相比,GPT-4 的公开资料极为有限,社交媒体上甚至有评论戏称:“我帮你们读了GPT-4的技术报告,简而言之,就是‘我们使用了Python。’”。
GPT-4 最大的亮点是其多模态能力:它可以同时处理文本和图像输入(但输出仍为文本)。这意味着它不仅能理解文字,还能看懂图片。例如,它能够识别图像中的幽默点,具备基础的视觉理解能力。

GPT-4 在多个标准化考试中表现出色,不仅全面超越 GPT-3,甚至在一些领域超过了人类。例如,它成功通过了美国律师资格考试,得分高于大多数考生。
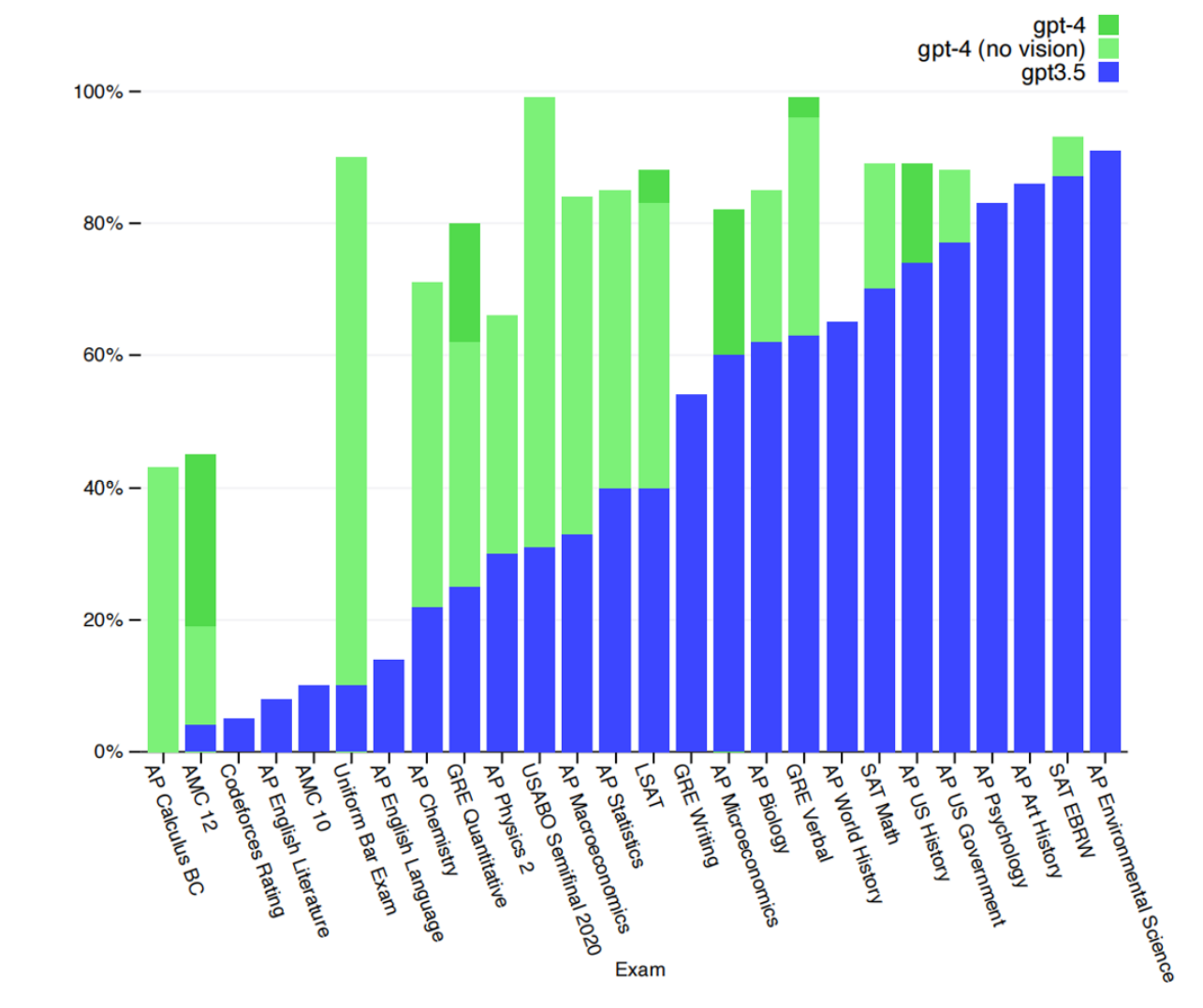
虽然 GPT-4 的报告透露的信息不多,但有一点值得注意:大模型的核心能力主要在预训练阶段就已形成。后期通过人类反馈进行的强化学习,主要是优化输出风格和可控性,而不是增强模型的基础认知能力。如果强化学习设计不当,反而可能削弱模型已有的能力。