18.4 DeepSeekV3
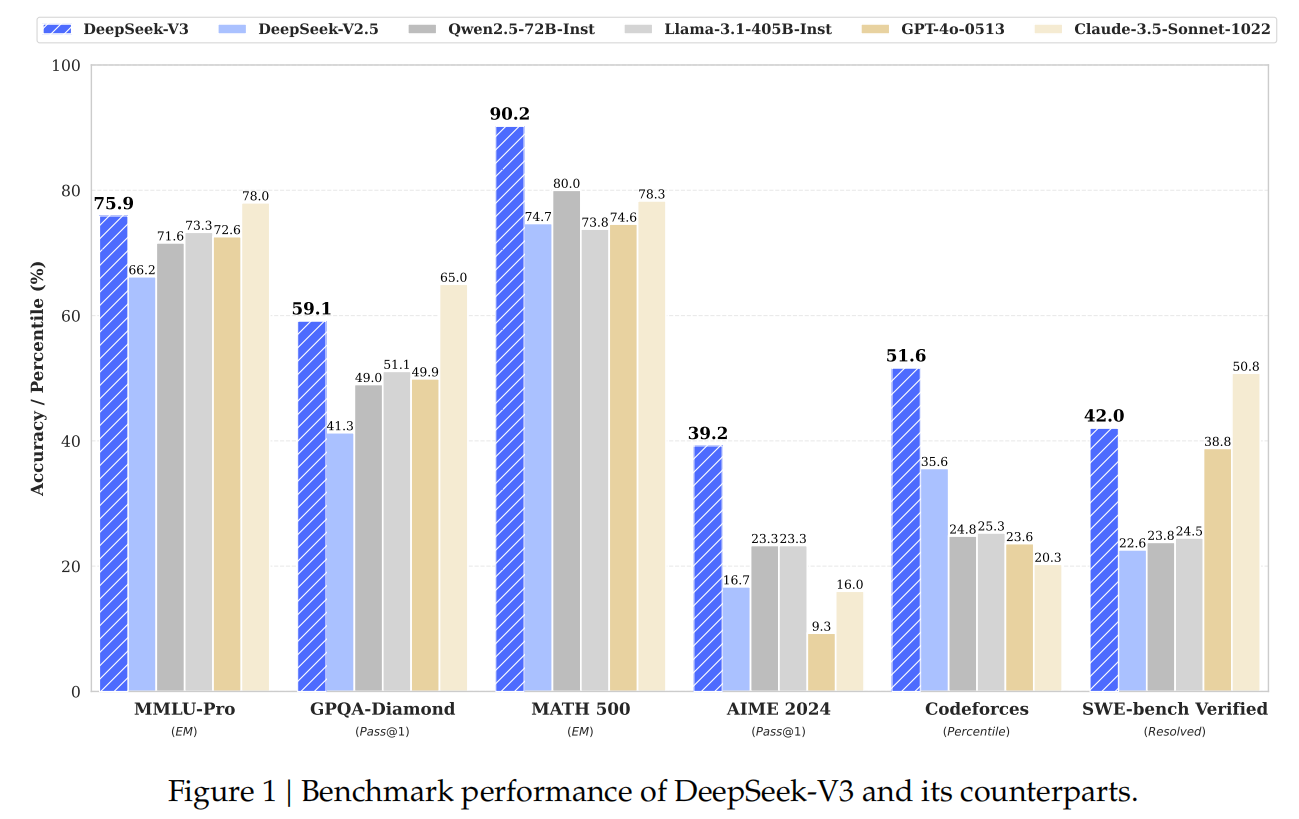
首先我们来看一下DeepSeekV3和其他模型的性能对比,可以看到它在各项测评中都超过了闭源的OpenAI的GPT-4o模型。这一点就足以在业界引起轰动,然而更让大家惊叹的是,它的训练成本只有500多万美元。
Llama3 405B模型用H100,训练了3080万GPU小时。而DeepSeekV3 671B模型,用的是性能不如H100的H800GPU,训练了279万GPU小时,在性能超过Llama3的同时,训练花费还不到Llama3的十分之一。所以这让DeepSeek火出了圈。也否定了之前无脑堆算力来提升模型性能的做法,引起了英伟达股票的大跌。
DeepSeekV3除了在模型架构方面做了一些优化和改进外,也在训练框架方面也做了非常多的改进,比如是业界首次使用FP8混合精度训练超大参数量模型。但今天我们主要讲DeepSeekV3在模型架构方面的一些改进点。
18.4.1 模型架构
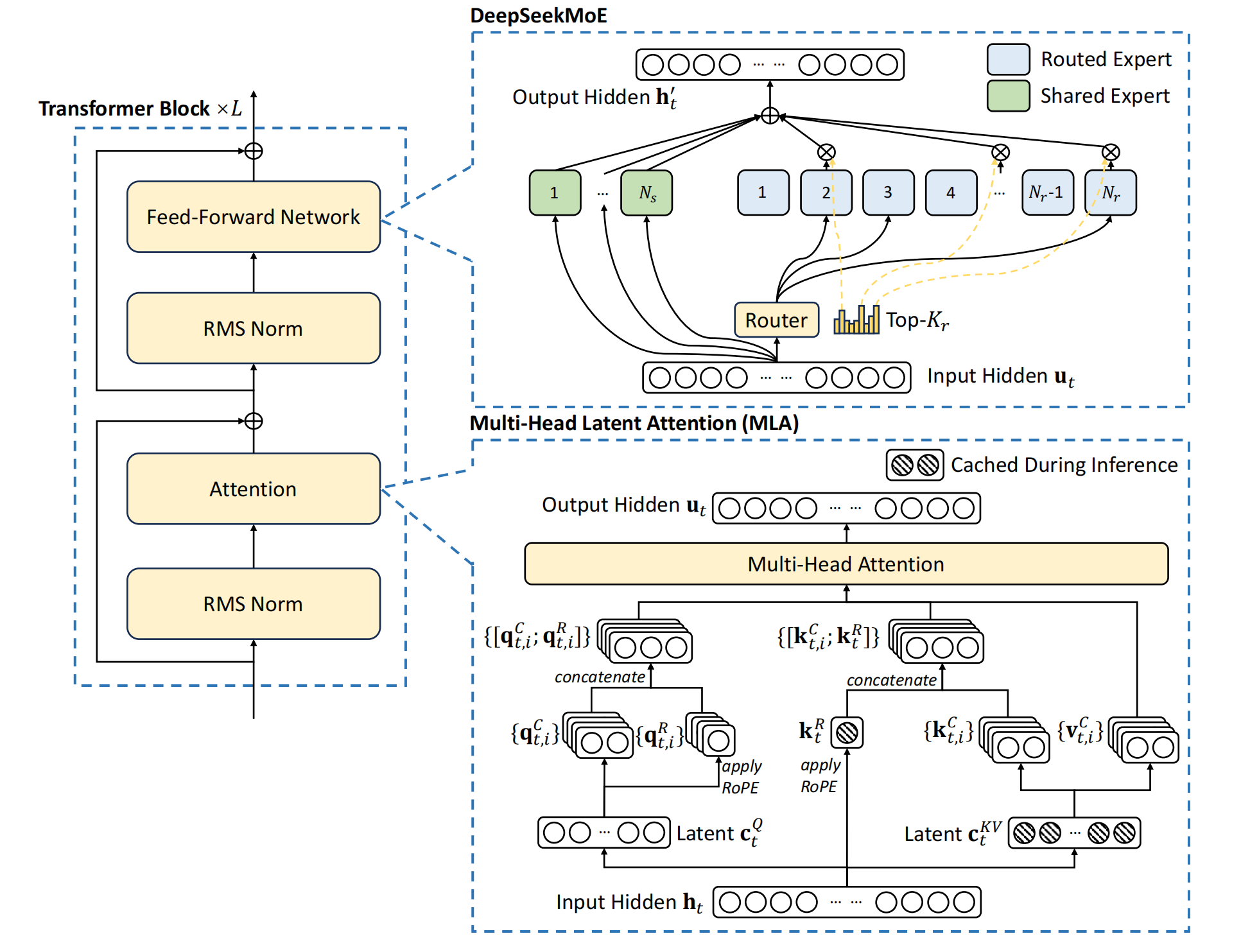
首先我们看一下DeepSeekV3的模型架构图,它采用了我们之前讲过的DeepSeekMOE,和MLA,这两点都没有变化。但在实现细节上有一些小的变化。在DeepSeekV2里,路由网络出来对各个专家的权重logits用softmax作为激活函数,这样让所有专家的权重加和为1。但是因为最终只选择TopK个专家,选择TopK个专家后,对权重还要再做一次归一化,所以这里也不必一定用softmax。在DeepSeekV3里,就改成对每个专家的权重的logits用Sigmoid激活函数,然后对选择的topK个专家,再进行归一化,做为最终的专家权重。
接下来是负载均衡的修改,之前我们讲MOE时讲过针对batch的辅助负载均衡损失函数,在DeepSeekV3里去掉了针对Batch的辅助负载均衡损失函数,而是训练时,在每个step,监控每个专家的负载,如果某个专家负载过高,就自动调整减小它对应的权重。如果专家负载过低,就自动调整增加它的权重。需要注意的是,这个修改只在专家路由时起作用,在和最终专家输出相乘时,还是采用原来的权重值。DeepSeek也做了消融实验,发现去掉Batch的辅助负载均衡损失函数,通过动态调节每个专家的权重的方法可以获得更好的模型效果。并且同时在不同大小的模型下做了实验,效果都是一致的。
另外DeepSeekV3增加了针对序列的负载均衡损失函数,这个损失函数的形式和我们讲MOE时针对batch的负载均衡损失是一样的。都是用各个专家被选择的频率值乘以平均概率值再求和。之所以要增加序列负载均衡损失函数,是防止在序列内部专家的负载不均衡。如果专家仅仅是在batch内负载均衡,那么有可能是按照序列划分的专家的,有的专家可能擅长回答某一类问题。这样当模型部署后,如果用户在某一时间问多个同一方向的问题(比如数学问题),就会出现专家负载不均衡的现象。
DeepSeek V3最大的改动就是训练时采用了多token预测,即 Multi-Token Prediction MTP。
18.4.2 MTP
之前我们学的大语言模型都是每次只能预测一个token。但实际上想Google,Meta等公司的研究人员一直在研究让大语言模型一次预测多个token。
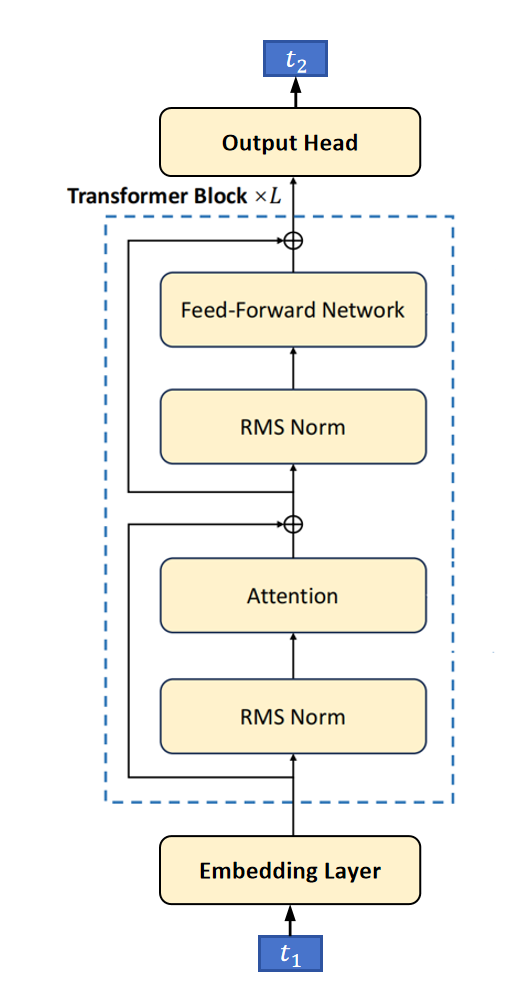
普通的大模型结构如上图所示。
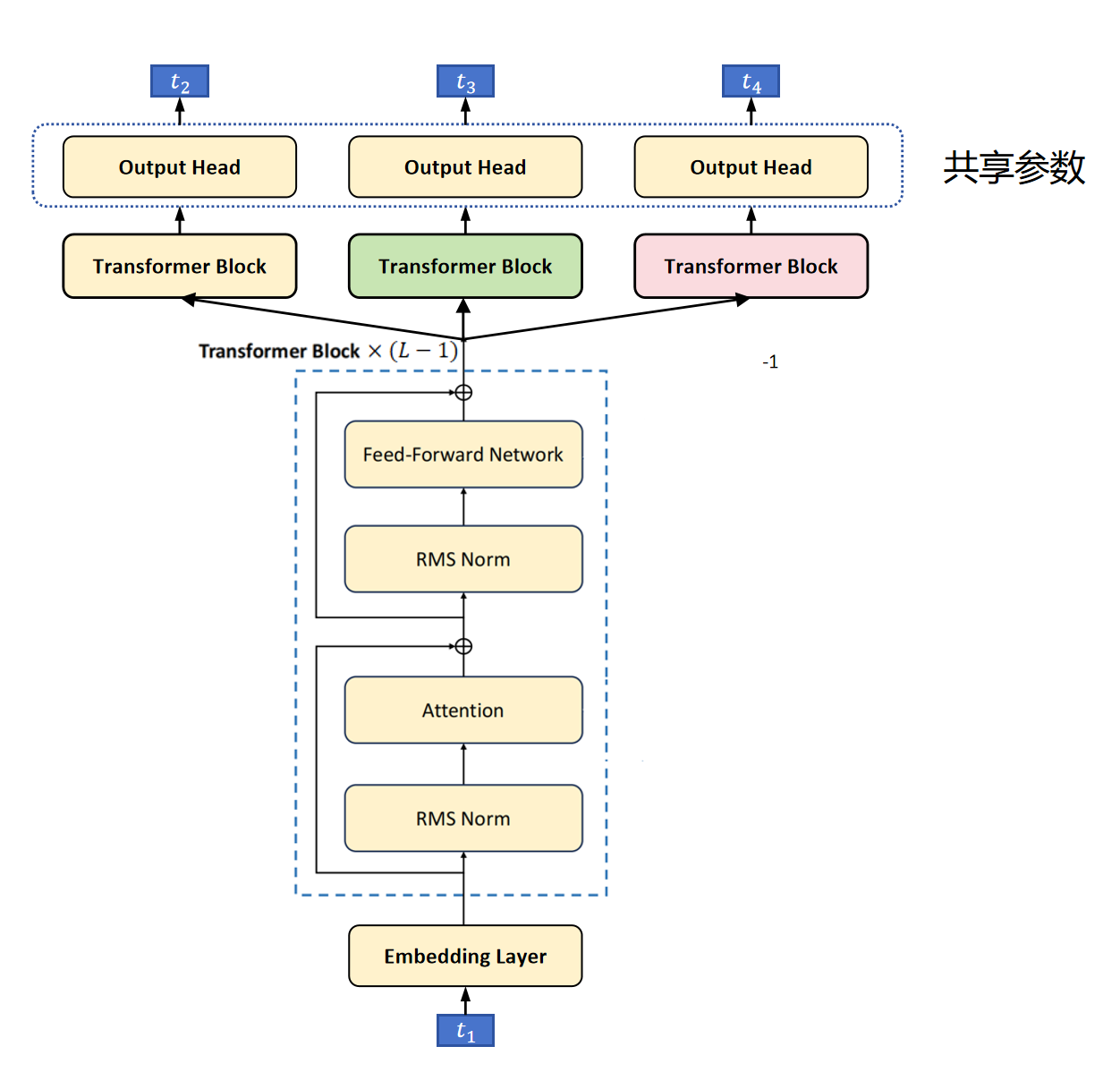
上图是DeepSeek V3出现之前的多token预测模型架构。首先是L-1层的共享的Transformer Block,为什么这里是L-1层呢?因为把最后一层的Transformer Block提出来,放在上边最左边,作为主要的一个头,它的作用并没有变,还是预测下一个token。然后又额外增加了其他的头,它们从第L-1层接入token的特征,经过额外增加的一个Transformer Block,再经过分类头,分别预测后边第2个token,第3个token。比如这里输入是t1,原始的输出头预测T2,下一个MTP头需要预测T3,再下一个MTP头需要预测T4。注意,这里的分类头是共享参数的。在计算Loss时,会分别考虑T2,T3,T4的交叉熵损失。其中T2的损失权重会大一些,T3和T4的损失权重会小一些。
这样做也是有一定道理的,那就是我们人在说一句话时,大脑并不是一个字一个字生成,有可能一下子就思考出一个语义片段。
具体到模型训练上,对骨干网络的训练监督信号由原来的一个token,变为多个token,可以增加训练信号,提高数据的利用率。另外,这样迫使模型可以提前规划它需要提取的特征,提取的特征需要能更好的预测未来的多个token。
多Token预测还有一个好处就是可以加速预测。它的加速预测不是简单的直接用多个头来生成接下来的多个token。因为预测最准确的还是预测下一个token的那个头。预测越远的token,越不准确,需要进行修正。
下边我们看一下利用MTP进行预测加速的方案: 首先,假如输入是三个token:“天”、“生”、“我”,模型有4个头,每个头并行预测接下来第一个,第二个,第三个,和第四个token。假设它们为“才”,“必”,“有”,“人”。这里“才”用深颜色表示,因为这是用第一个头预测的下一个token,它是最准确的了。我们就认为它是最终的输出,但是后边几个token肯定没有第一个头预测的下一个token准确。所以用浅颜色表示,表示不确信。那么对于后边这几个不确信的token怎么办呢?那就是让第一个头再去验证一下。
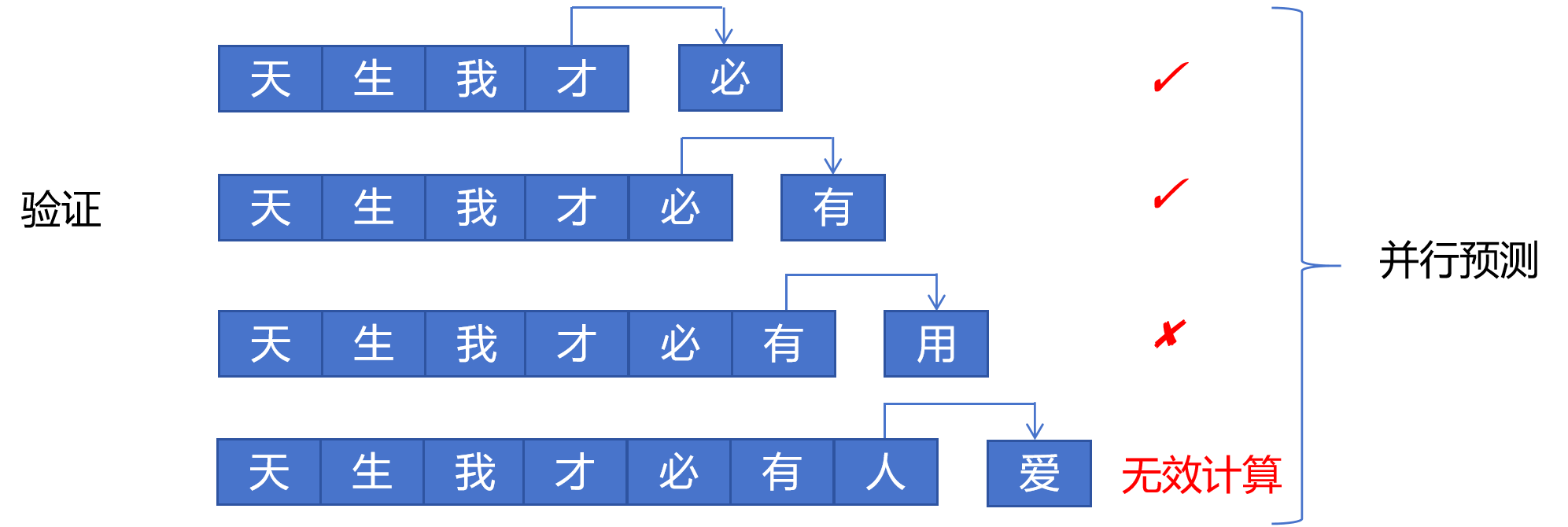
所以我们构造了这样的一个batch,用第一个头来预测下一个token。对不确定的token逐个进行确认。比如这里第一个头的输出分别为“必”,“有”,“用”。前两个预测对了,第3个错了。需要注意的是,这里3个序列是通过一个batch并行进行验证的。因为GPU擅长并行计算,主要时间开销是显存访问。所以认为这一个batch的3个序列的验证时间和一个序列的生成时间差不多。

第三步就是接受最长的正确序列了。最后一个虽然第四个头预测错了,但是验证时第一个头给出了正确答案,最终接受时就接受第一个头给出的预测。
可以看到通过预测和验证两步运算,就预测出来4个token。原来这要通过4步运算才可以。所以MTP可以加速推理,但是你可以看到这是以增加GPU的计算量为代价的,因为在第二步要同时对3个序列进行预测。
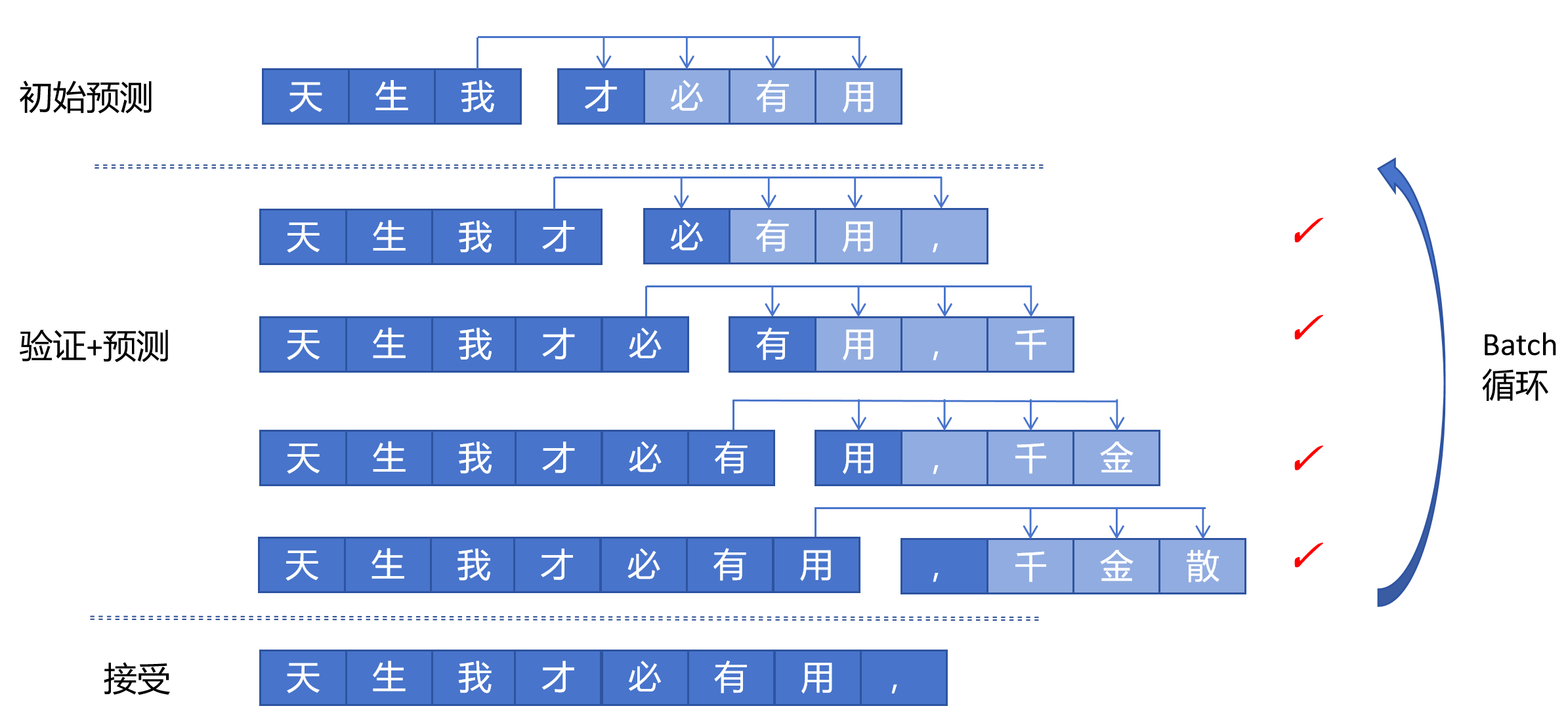
更进一步,可以将验证和预测放在一起。比如初始时一样,根据输入:“天”,“生”,“我”,用四个头分别预测,假如理想情况下四个头都预测正确了,预测为“才”,“必”,“有”,“用”。接下来在验证时,我们之前是只让第一个头工作,现在我们让4个头同时工作,那就会生成后边的预测。比如验证时以4个序列为一个batch。则在验证完成后,又可以进入下一步的验证了。这样就只要不断进行验证+预测的循环就可以。在每个batch结束后输出接受的序列。这样效率更高。
MTP预测加速只在生成单个序列时有效,就是整个推理集群只为你一个人做推理服务,那确实可以加速推理。 但是我们知道,现在像vLLM这样的推理框架,支持动态batch,可以支持多用户同时访问大模型。它会自动的将多个不同请求组合成batch进行预测。这时MTP的预测加速就没有优势了,反而会因为验证不通过而浪费计算。所以DeepSeek MTP,它只是在训练时利用MTP来提升模型的性能,在推理部署时,一般就丢弃其他几个预测多步的头,就只用第一个头做下一个token的预测。和普通单头的大模型没有区别。
18.4.3 DeepSeekMTP
DeepSeekMTP也在模型架构上进行了修改。原来的多token预测有个问题。就是跨多步的token不知道它前面的几个token,从而让预测正确概率变低,不利于模型的收敛。比如对于第四个头的预测,它要在不知道它前边3个token的前提下预测出下一个token,这样难度非常大。
SeepSeekMTP就是给每个头传入了额外的信息。帮助多token预测的头能更好的预测自己接下来的token。
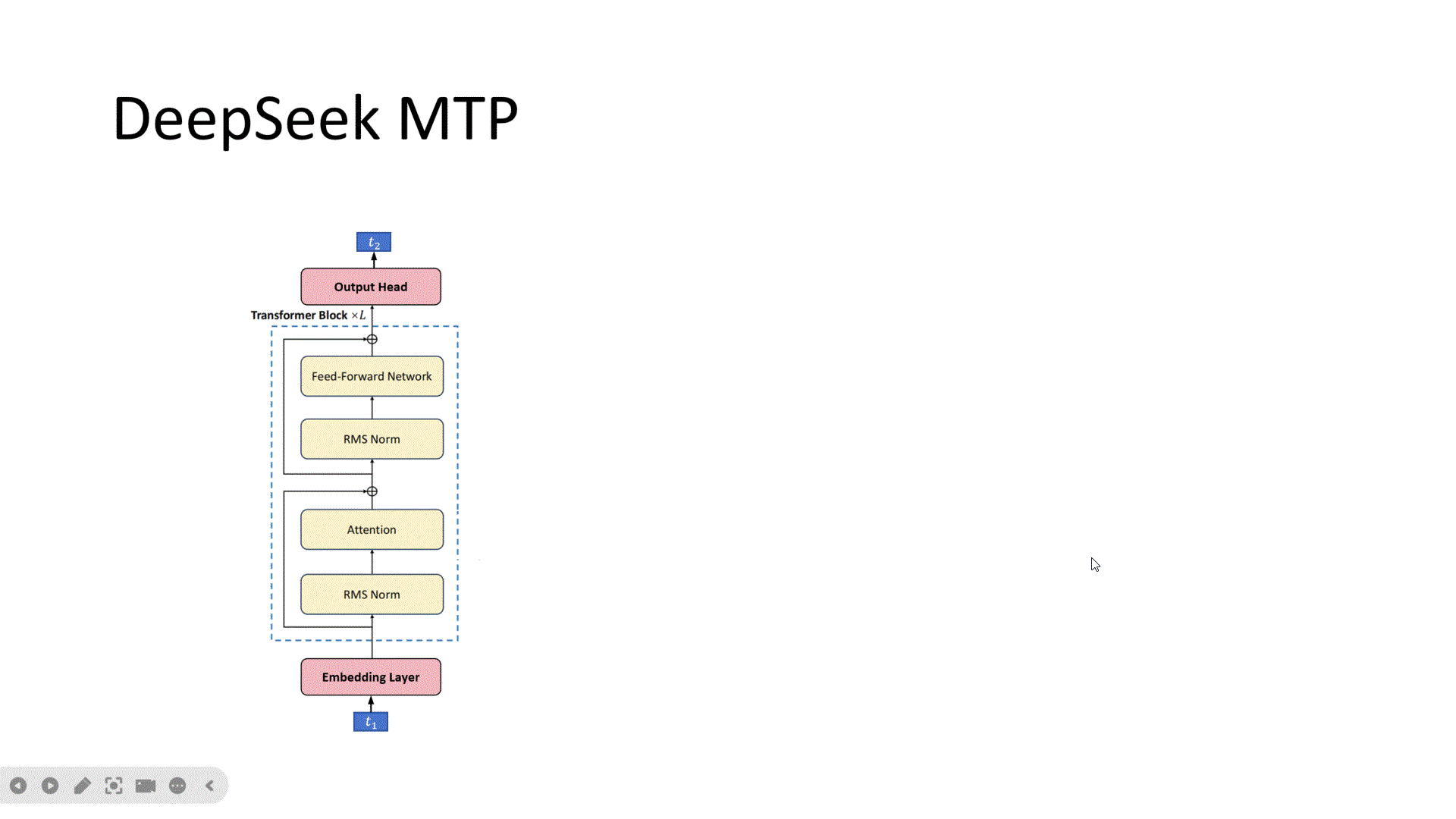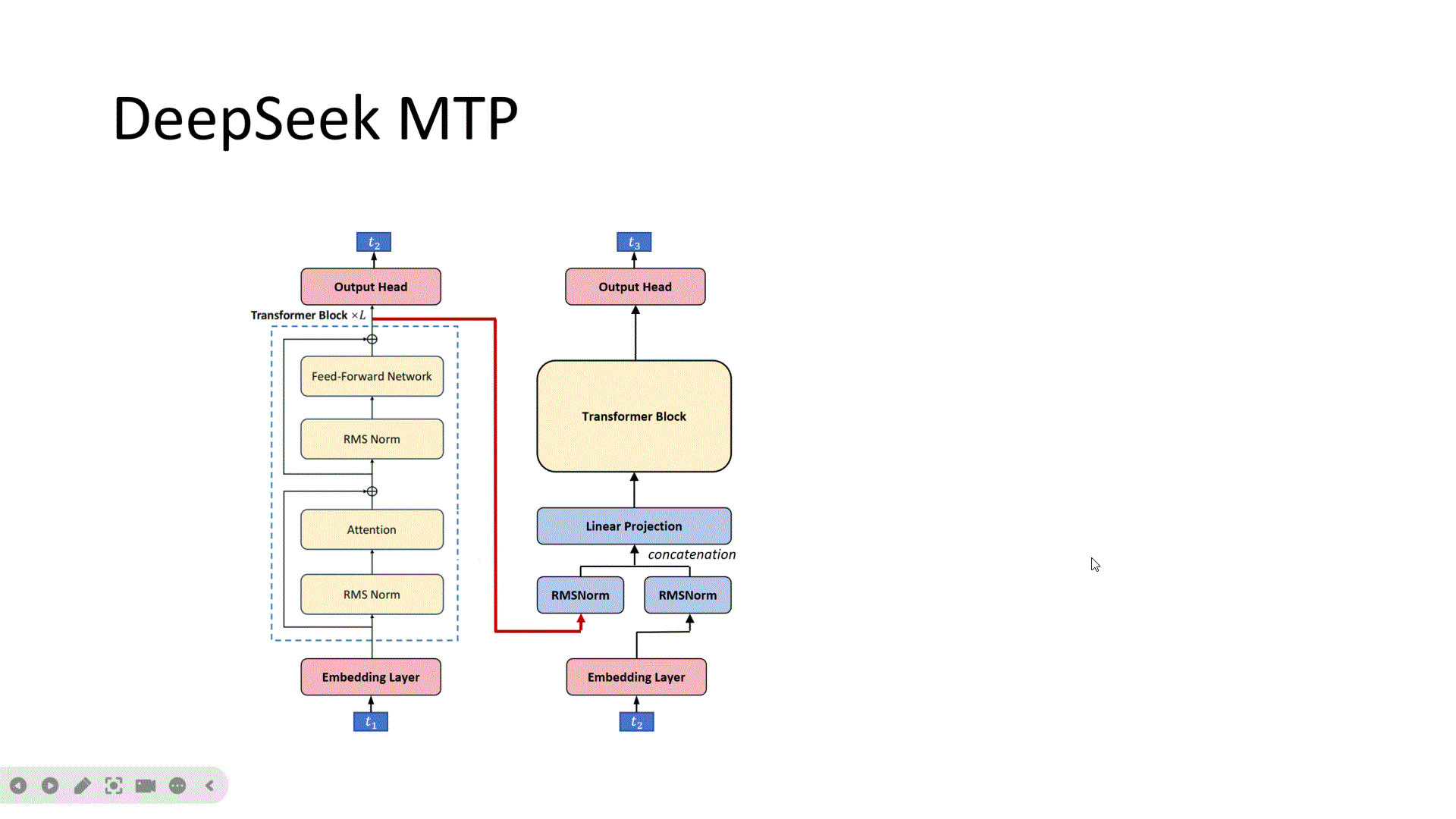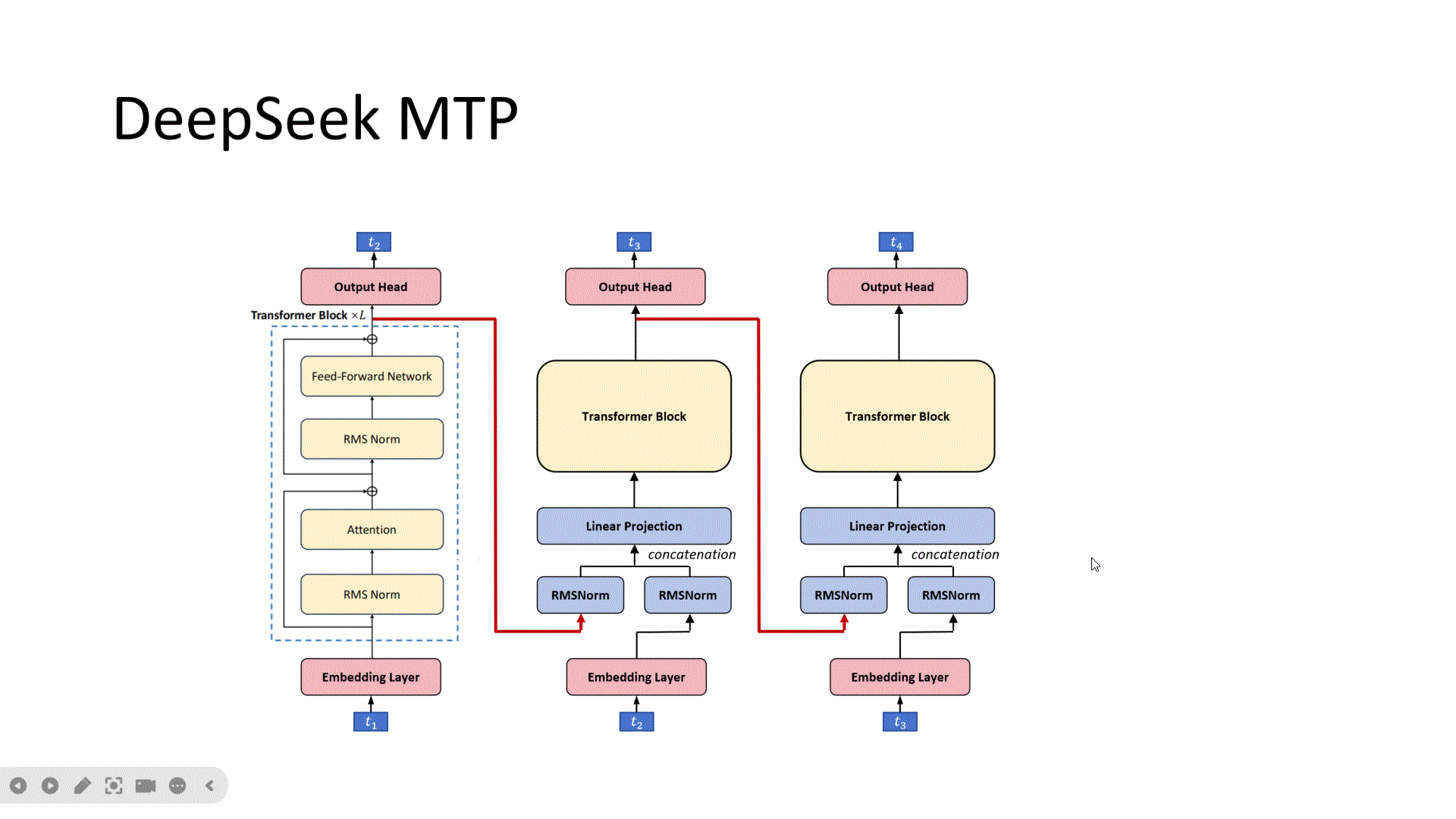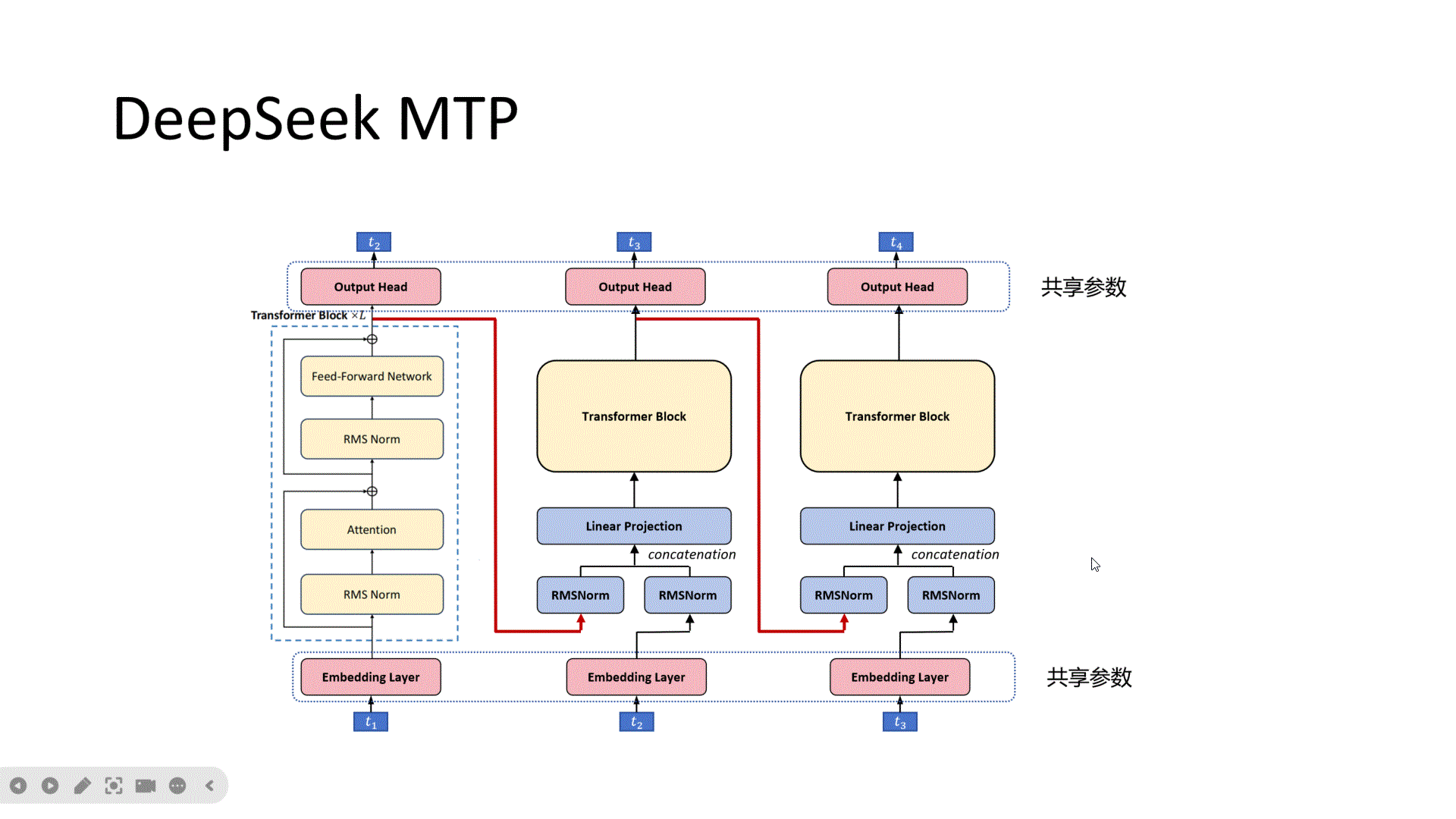
首先是原始的DeepSeek模型架构,输入为t1,进过L层的Transformer Block,输出经过分类头,预测出t2, 然后我们增加一个MTP头,它的输入来源有两个,一个是来自DeepSeek第L层的token的特征。注意,这里是第L层,不是L-1层。另一个是t2这个token经过Embedding后的特征。可以理解为左边传来的是可以预测T2的token的特征,因为主网络就是需要根据这个特征来预测t2。下边传来的是t2的Embedding的特征。然后分别做归一化,再按Token把特征拼接起来,这样每个token的特征维度就为原来的2倍,再经过一个线性层映射为原来的token的特征维度。经过一个TransformerBlock,接下来经过分类头来预测t3。可以看到对于这个MTP头,它输入的信息包含了可以预测t2这个token的特征,也包含了t2的Embedding,那就更容易预测出t2的下一个token:t3。接下来我们看第二个MTP头,同样它的输入来自两个部分,一部分是可以预测t3的特征,一部分是t3的Embedding,然后经过归一化,降维,Transformerblock,预测出T4。这样每个MTP头训练会更容易,也更稳定。其中embedding层和分类头是共享参数的。
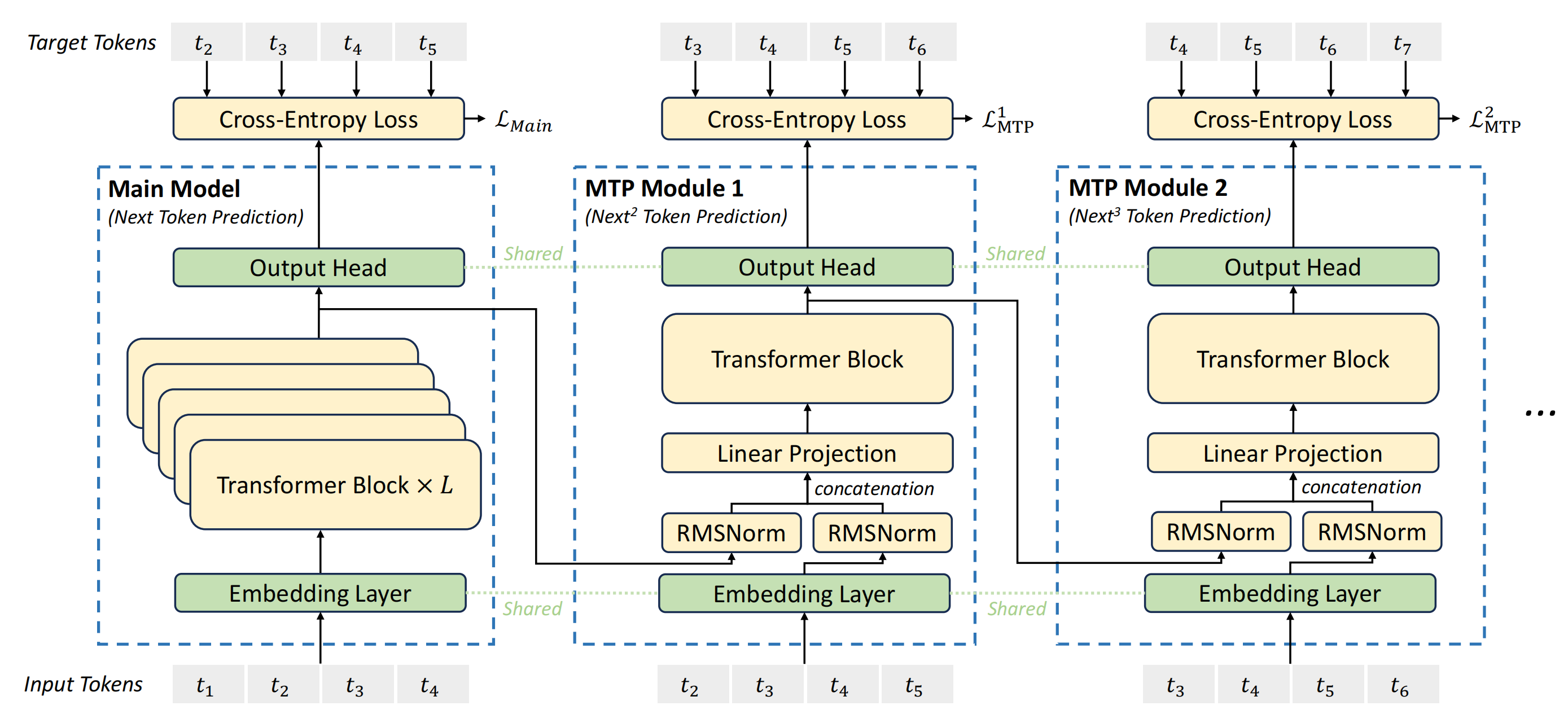
最后我们看一下原始论文里的MTP模型结构图,因为训练时所有token都是已知的,可以通过mask的方式一次进行多个token的训练,这里输入为t1-t4,主模型,预测下一个token,输出是t2-t5,它给MTP1传入的是可以预测出t2-t5的token的特征,同时t2-t5的embedding也被传入第一个MTP头,最终,第一个MTP头预测出t3-t6。第二个MTP头也是类似。输入t3-t6的相关特征,预测出t4-t7的token。
这里有两个MTP头,它的交叉熵loss最终也是会加入到模型最终的loss里的。比如在DeepSeekV3里先对所有MTP头的loss取平均,然后乘以权重𝜆,在训练前10Ttoken时,𝜆的值为0.3,在训练最后4.8Ttoken时,𝜆的值为0.1。
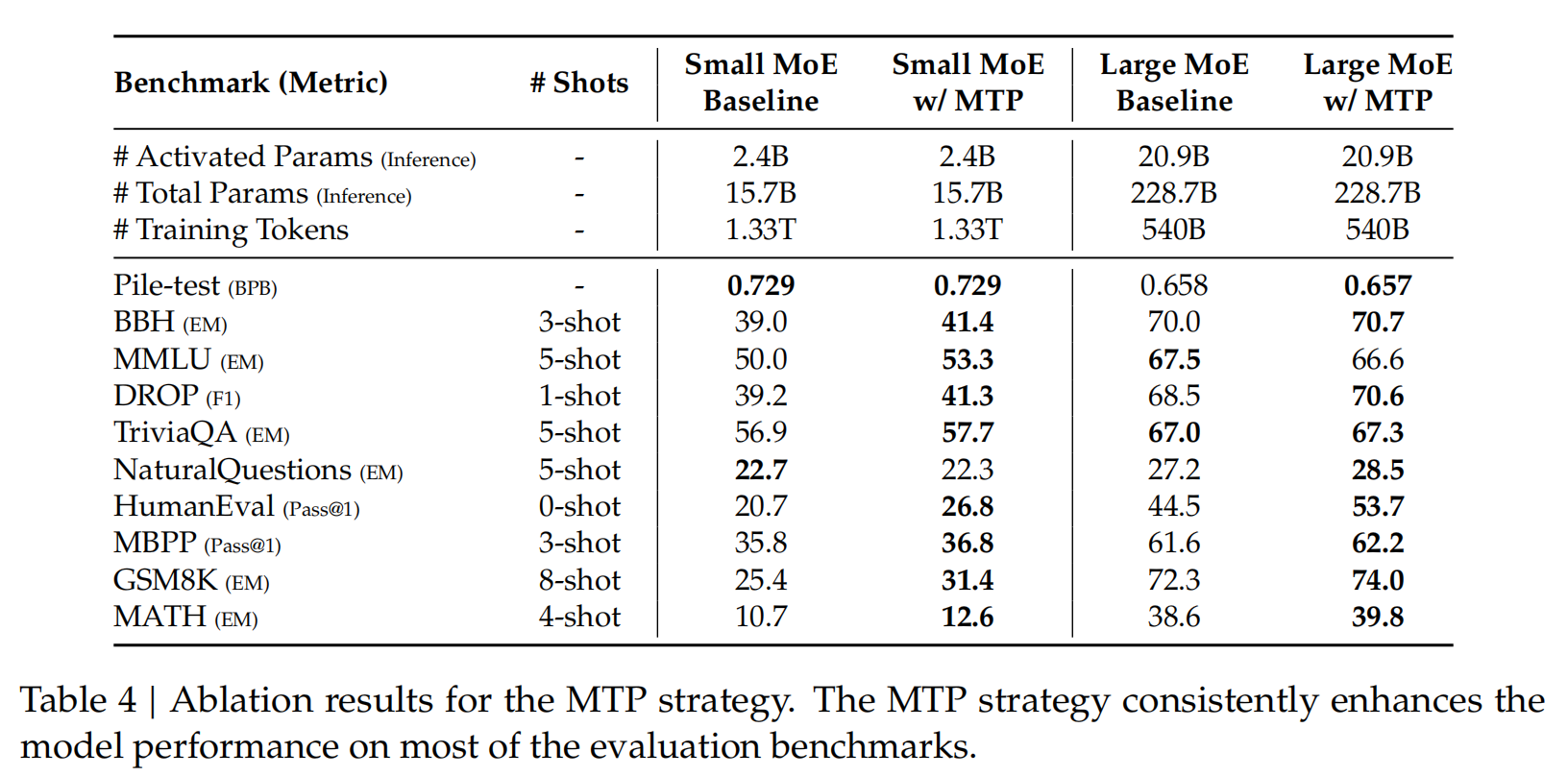
最后我们可以看一下论文里的消融实现,在添加MTP训练后,不论是15.7B的小模型还是228.7B的大模型,模型性能都有提高。